Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Large Language Model Uncertainty for Prompt Optimization
Paper and Code
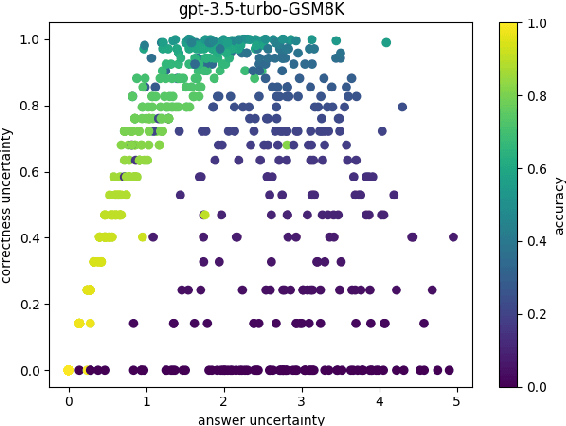
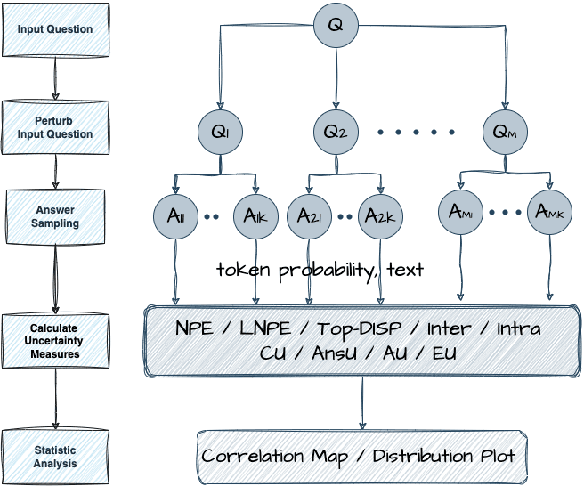
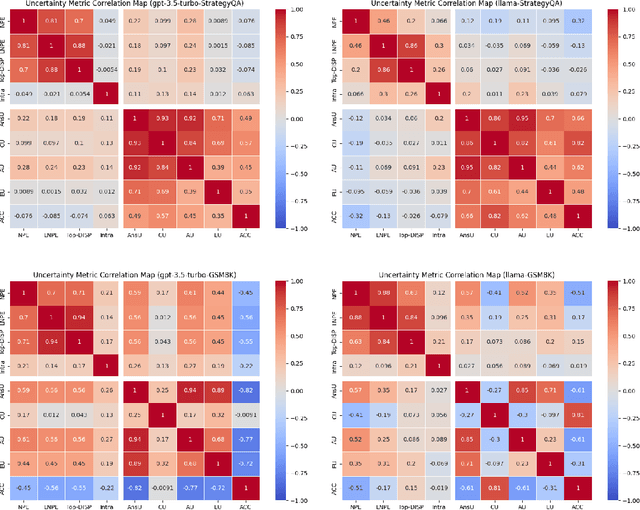
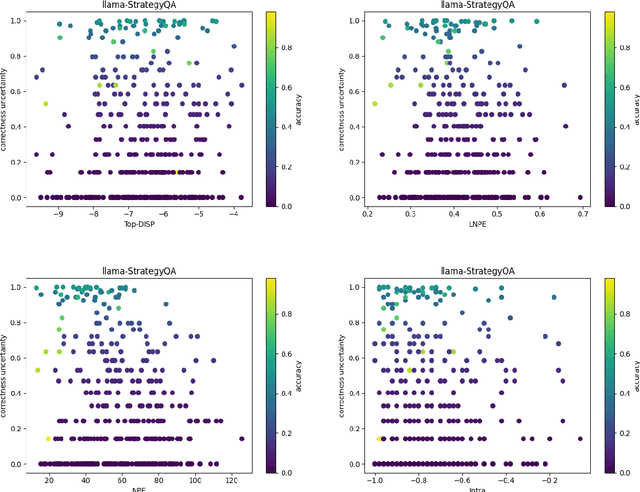
Prompt optimization algorithms for Large Language Models (LLMs) excel in multi-step reasoning but still lack effective uncertainty estimation. This paper introduces a benchmark dataset to evaluate uncertainty metrics, focusing on Answer, Correctness, Aleatoric, and Epistemic Uncertainty. Through analysis of models like GPT-3.5-Turbo and Meta-Llama-3.1-8B-Instruct, we show that current metrics align more with Answer Uncertainty, which reflects output confidence and diversity, rather than Correctness Uncertainty, highlighting the need for improved metrics that are optimization-objective-aware to better guide prompt optimization. Our code and dataset are available at https://github.com/0Frett/PO-Uncertainty-Benchmarking.
View paper on