 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Profiles for LLMs: Uncertainty Source Decomposition and Adaptive Model-Metric Selection
May 12, 2025Large language models (LLMs) often generate fluent but factually incorrect outputs, known as hallucinations, which undermine their reliability in real-world applications. While uncertainty estimation has emerged as a promising strategy for detecting such errors, current metrics offer limited interpretability and lack clarity about the types of uncertainty they capture. In this paper, we present a systematic framework for decomposing LLM uncertainty into four distinct sources, inspired by previous research. We develop a source-specific estimation pipeline to quantify these uncertainty types and evaluate how existing metrics relate to each source across tasks and models. Our results show that metrics, task, and model exhibit systematic variation in uncertainty characteristic. Building on this, we propose a method for task specific metric/model selection guided by the alignment or divergence between their uncertainty characteristics and that of a given task. Our experiments across datasets and models demonstrate that our uncertainty-aware selection strategy consistently outperforms baseline strategies, helping us select appropriate models or uncertainty metrics, and contributing to more reliable and efficient deployment in uncertainty estimation.
Benchmarking Large Language Model Uncertainty for Prompt Optimization
Sep 16, 2024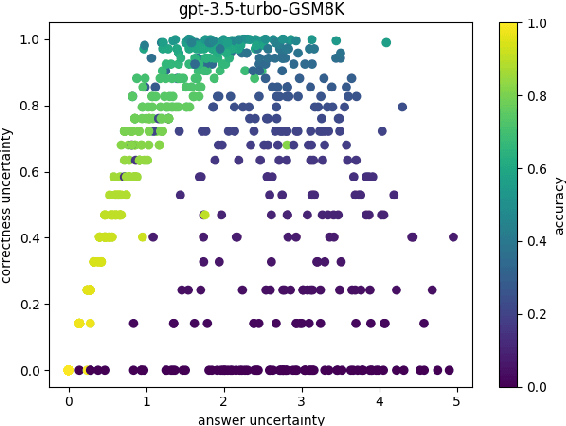
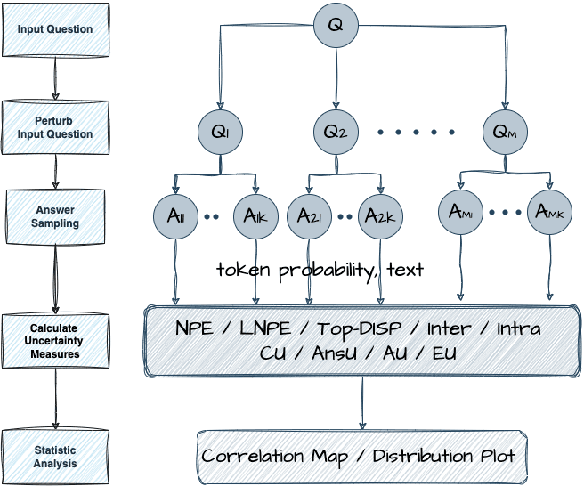
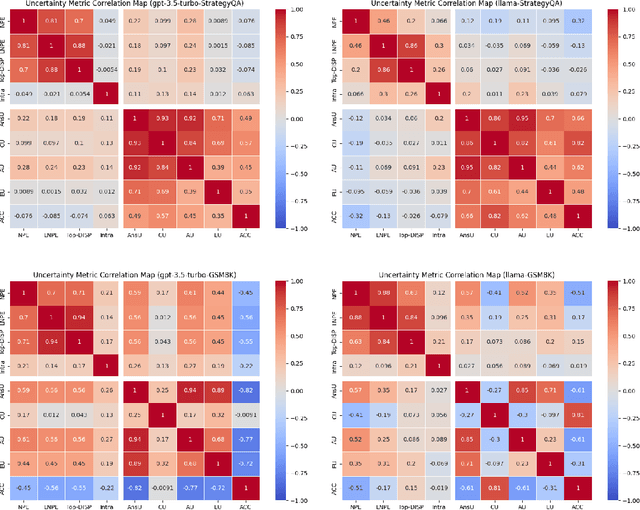
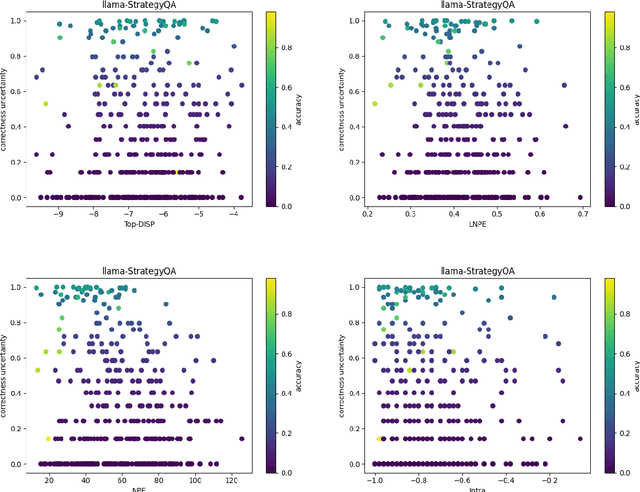
Prompt optimization algorithms for Large Language Models (LLMs) excel in multi-step reasoning but still lack effective uncertainty estimation. This paper introduces a benchmark dataset to evaluate uncertainty metrics, focusing on Answer, Correctness, Aleatoric, and Epistemic Uncertainty. Through analysis of models like GPT-3.5-Turbo and Meta-Llama-3.1-8B-Instruct, we show that current metrics align more with Answer Uncertainty, which reflects output confidence and diversity, rather than Correctness Uncertainty, highlighting the need for improved metrics that are optimization-objective-aware to better guide prompt optimization. Our code and dataset are available at https://github.com/0Frett/PO-Uncertainty-Benchmarking.
Text-centric Alignment for Multi-Modality Learning
Feb 12, 2024



This research paper addresses the challenge of modality mismatch in multimodal learning, where the modalities available during inference differ from those available at training. We propose the Text-centric Alignment for Multi-Modality Learning (TAMML) approach, an innovative method that utilizes Large Language Models (LLMs) with in-context learning and foundation models to enhance the generalizability of multimodal systems under these conditions. By leveraging the unique properties of text as a unified semantic space, TAMML demonstrates significant improvements in handling unseen, diverse, and unpredictable modality combinations. TAMML not only adapts to varying modalities but also maintains robust performance, showcasing the potential of foundation models in overcoming the limitations of traditional fixed-modality frameworks in embedding representations. This study contributes to the field by offering a flexible, effective solution for real-world applications where modality availability is dynamic and uncertain.
Towards Optimizing with Large Language Models
Oct 08, 2023
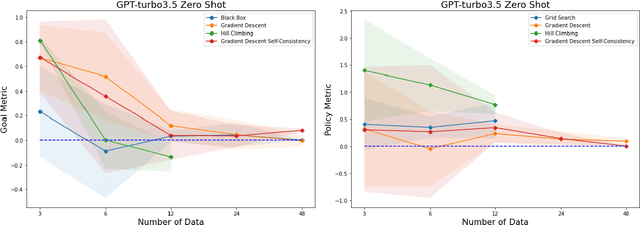
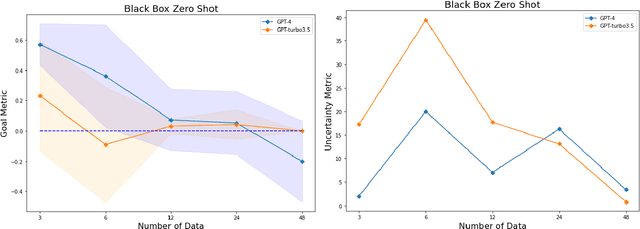
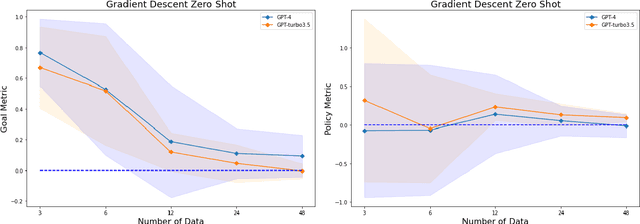
In this work, we conduct an assessment of the optimization capabilities of LLMs across various tasks and data sizes. Each of these tasks corresponds to unique optimization domains, and LLMs are required to execute these tasks with interactive prompting. That is, in each optimization step, the LLM generates new solutions from the past generated solutions with their values, and then the new solutions are evaluated and considered in the next optimization step. Additionally, we introduce three distinct metrics for a comprehensive assessment of task performance from various perspectives. These metrics offer the advantage of being applicable for evaluating LLM performance across a broad spectrum of optimization tasks and are less sensitive to variations in test samples. By applying these metrics, we observe that LLMs exhibit strong optimization capabilities when dealing with small-sized samples. However, their performance is significantly influenced by factors like data size and values, underscoring the importance of further research in the domain of optimization tasks for LLMs.