 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^2$TG: Adaptive Anisotropic Textured Gaussians for Efficient 3D Scene Representation
Jan 14, 2026Gaussian Splatting has emerged as a powerful representation for high-quality, real-time 3D scene rendering. While recent works extend Gaussians with learnable textures to enrich visual appearance, existing approaches allocate a fixed square texture per primitive, leading to inefficient memory usage and limited adaptability to scene variability. In this paper, we introduce adaptive anisotropic textured Gaussians (A$^2$TG), a novel representation that generalizes textured Gaussians by equipping each primitive with an anisotropic texture. Our method employs a gradient-guided adaptive rule to jointly determine texture resolution and aspect ratio, enabling non-uniform, detail-aware allocation that aligns with the anisotropic nature of Gaussian splats. This design significantly improves texture efficiency, reducing memory consumption while enhancing image quality. Experiments on multiple benchmark datasets demonstrate that A TG consistently outperforms fixed-texture Gaussian Splatting methods, achieving comparable rendering fidelity with substantially lower memory requirements.
LOBE-GS: Load-Balanced and Efficient 3D Gaussian Splatting for Large-Scale Scene Reconstruction
Oct 02, 20253D Gaussian Splatting (3DGS) has established itself as an efficient representation for real-time, high-fidelity 3D scene reconstruction. However, scaling 3DGS to large and unbounded scenes such as city blocks remains difficult. Existing divide-and-conquer methods alleviate memory pressure by partitioning the scene into blocks, but introduce new bottlenecks: (i) partitions suffer from severe load imbalance since uniform or heuristic splits do not reflect actual computational demands, and (ii) coarse-to-fine pipelines fail to exploit the coarse stage efficiently, often reloading the entire model and incurring high overhead. In this work, we introduce LoBE-GS, a novel Load-Balanced and Efficient 3D Gaussian Splatting framework, that re-engineers the large-scale 3DGS pipeline. LoBE-GS introduces a depth-aware partitioning method that reduces preprocessing from hours to minutes, an optimization-based strategy that balances visible Gaussians -- a strong proxy for computational load -- across blocks, and two lightweight techniques, visibility cropping and selective densification, to further reduce training cost. Evaluations on large-scale urban and outdoor datasets show that LoBE-GS consistently achieves up to $2\times$ faster end-to-end training time than state-of-the-art baselines, while maintaining reconstruction quality and enabling scalability to scenes infeasible with vanilla 3DGS.
Enhance Modality Robustness in Text-Centric Multimodal Alignment with Adversarial Prompting
Aug 19, 2024Converting different modalities into generalized text, which then serves as input prompts for large language models (LLMs), is a common approach for aligning multimodal models, particularly when pairwise data is limited. Text-centric alignment method leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation, thereby enabling downstream models to effectively interpret various modal inputs. This study evaluates the quality and robustness of multimodal representations in the face of noise imperfections, dynamic input order permutations, and missing modalities, revealing that current text-centric alignment methods can compromise downstream robustness. To address this issue, we propose a new text-centric adversarial training approach that significantly enhances robustness compared to traditional robust training methods and pre-trained multimodal foundation models. Our findings underscore the potential of this approach to improve the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Enhance the Robustness of Text-Centric Multimodal Alignments
Jul 06, 2024Converting different modalities into general text, serving as input prompts for large language models (LLMs), is a common method to align multimodal models when there is limited pairwise data. This text-centric approach leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation. This enables downstream models to effectively interpret various modal inputs. This study assesses the quality and robustness of multimodal representations in the presence of missing entries, noise, or absent modalities, revealing that current text-centric alignment methods compromise downstream robustness. To address this issue, we propose a new text-centric approach that achieves superior robustness compared to previous methods across various modalities in different settings. Our findings highlight the potential of this approach to enhance the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Text-centric Alignment for Multi-Modality Learning
Feb 12, 2024



This research paper addresses the challenge of modality mismatch in multimodal learning, where the modalities available during inference differ from those available at training. We propose the Text-centric Alignment for Multi-Modality Learning (TAMML) approach, an innovative method that utilizes Large Language Models (LLMs) with in-context learning and foundation models to enhance the generalizability of multimodal systems under these conditions. By leveraging the unique properties of text as a unified semantic space, TAMML demonstrates significant improvements in handling unseen, diverse, and unpredictable modality combinations. TAMML not only adapts to varying modalities but also maintains robust performance, showcasing the potential of foundation models in overcoming the limitations of traditional fixed-modality frameworks in embedding representations. This study contributes to the field by offering a flexible, effective solution for real-world applications where modality availability is dynamic and uncertain.
Sampling Neural Radiance Fields for Refractive Objects
Nov 27, 2022
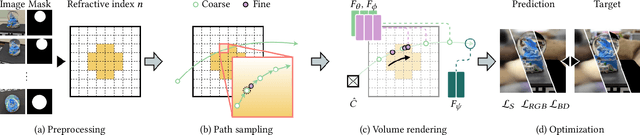
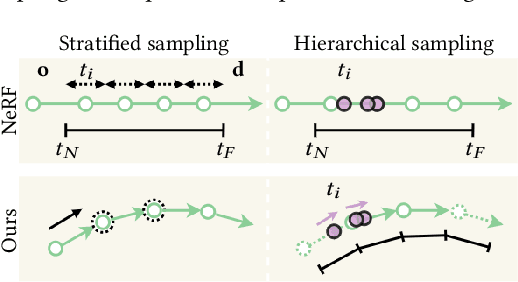
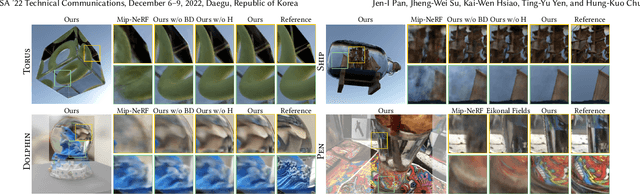
Recently, differentiable volume rendering in neural radiance fields (NeRF) has gained a lot of popularity, and its variants have attained many impressive results. However, existing methods usually assume the scene is a homogeneous volume so that a ray is cast along the straight path. In this work, the scene is instead a heterogeneous volume with a piecewise-constant refractive index, where the path will be curved if it intersects the different refractive indices. For novel view synthesis of refractive objects, our NeRF-based framework aims to optimize the radiance fields of bounded volume and boundary from multi-view posed images with refractive object silhouettes. To tackle this challenging problem, the refractive index of a scene is reconstructed from silhouettes. Given the refractive index, we extend the stratified and hierarchical sampling techniques in NeRF to allow drawing samples along a curved path tracked by the Eikonal equation. The results indicate that our framework outperforms the state-of-the-art method both quantitatively and qualitatively, demonstrating better performance on the perceptual similarity metric and an apparent improvement in the rendering quality on several synthetic and real scenes.