 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^2$TG: Adaptive Anisotropic Textured Gaussians for Efficient 3D Scene Representation
Jan 14, 2026Gaussian Splatting has emerged as a powerful representation for high-quality, real-time 3D scene rendering. While recent works extend Gaussians with learnable textures to enrich visual appearance, existing approaches allocate a fixed square texture per primitive, leading to inefficient memory usage and limited adaptability to scene variability. In this paper, we introduce adaptive anisotropic textured Gaussians (A$^2$TG), a novel representation that generalizes textured Gaussians by equipping each primitive with an anisotropic texture. Our method employs a gradient-guided adaptive rule to jointly determine texture resolution and aspect ratio, enabling non-uniform, detail-aware allocation that aligns with the anisotropic nature of Gaussian splats. This design significantly improves texture efficiency, reducing memory consumption while enhancing image quality. Experiments on multiple benchmark datasets demonstrate that A TG consistently outperforms fixed-texture Gaussian Splatting methods, achieving comparable rendering fidelity with substantially lower memory requirements.
LOBE-GS: Load-Balanced and Efficient 3D Gaussian Splatting for Large-Scale Scene Reconstruction
Oct 02, 20253D Gaussian Splatting (3DGS) has established itself as an efficient representation for real-time, high-fidelity 3D scene reconstruction. However, scaling 3DGS to large and unbounded scenes such as city blocks remains difficult. Existing divide-and-conquer methods alleviate memory pressure by partitioning the scene into blocks, but introduce new bottlenecks: (i) partitions suffer from severe load imbalance since uniform or heuristic splits do not reflect actual computational demands, and (ii) coarse-to-fine pipelines fail to exploit the coarse stage efficiently, often reloading the entire model and incurring high overhead. In this work, we introduce LoBE-GS, a novel Load-Balanced and Efficient 3D Gaussian Splatting framework, that re-engineers the large-scale 3DGS pipeline. LoBE-GS introduces a depth-aware partitioning method that reduces preprocessing from hours to minutes, an optimization-based strategy that balances visible Gaussians -- a strong proxy for computational load -- across blocks, and two lightweight techniques, visibility cropping and selective densification, to further reduce training cost. Evaluations on large-scale urban and outdoor datasets show that LoBE-GS consistently achieves up to $2\times$ faster end-to-end training time than state-of-the-art baselines, while maintaining reconstruction quality and enabling scalability to scenes infeasible with vanilla 3DGS.
CTGAN: Semantic-guided Conditional Texture Generator for 3D Shapes
Feb 08, 2024The entertainment industry relies on 3D visual content to create immersive experiences, but traditional methods for creating textured 3D models can be time-consuming and subjective. Generative networks such as StyleGAN have advanced image synthesis, but generating 3D objects with high-fidelity textures is still not well explored, and existing methods have limitations. We propose the Semantic-guided Conditional Texture Generator (CTGAN), producing high-quality textures for 3D shapes that are consistent with the viewing angle while respecting shape semantics. CTGAN utilizes the disentangled nature of StyleGAN to finely manipulate the input latent codes, enabling explicit control over both the style and structure of the generated textures. A coarse-to-fine encoder architecture is introduced to enhance control over the structure of the resulting textures via input segmentation. Experimental results show that CTGAN outperforms existing methods on multiple quality metrics and achieves state-of-the-art performance on texture generation in both conditional and unconditional settings.
Layout-guided Indoor Panorama Inpainting with Plane-aware Normalization
Jan 13, 2023We present an end-to-end deep learning framework for indoor panoramic image inpainting. Although previous inpainting methods have shown impressive performance on natural perspective images, most fail to handle panoramic images, particularly indoor scenes, which usually contain complex structure and texture content. To achieve better inpainting quality, we propose to exploit both the global and local context of indoor panorama during the inpainting process. Specifically, we take the low-level layout edges estimated from the input panorama as a prior to guide the inpainting model for recovering the global indoor structure. A plane-aware normalization module is employed to embed plane-wise style features derived from the layout into the generator, encouraging local texture restoration from adjacent room structures (i.e., ceiling, floor, and walls). Experimental results show that our work outperforms the current state-of-the-art methods on a public panoramic dataset in both qualitative and quantitative evaluations. Our code is available at https://ericsujw.github.io/LGPN-net/
Sampling Neural Radiance Fields for Refractive Objects
Nov 27, 2022
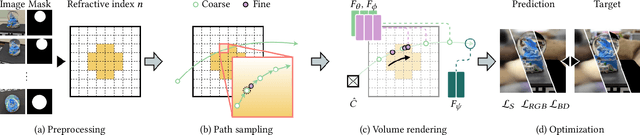
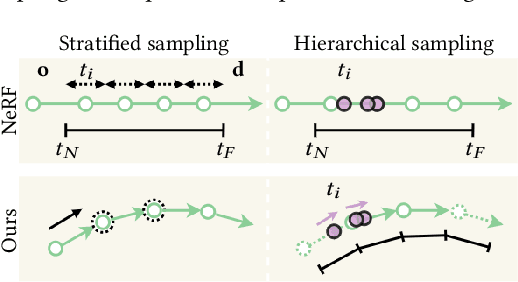
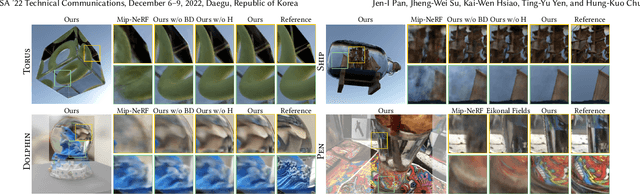
Recently, differentiable volume rendering in neural radiance fields (NeRF) has gained a lot of popularity, and its variants have attained many impressive results. However, existing methods usually assume the scene is a homogeneous volume so that a ray is cast along the straight path. In this work, the scene is instead a heterogeneous volume with a piecewise-constant refractive index, where the path will be curved if it intersects the different refractive indices. For novel view synthesis of refractive objects, our NeRF-based framework aims to optimize the radiance fields of bounded volume and boundary from multi-view posed images with refractive object silhouettes. To tackle this challenging problem, the refractive index of a scene is reconstructed from silhouettes. Given the refractive index, we extend the stratified and hierarchical sampling techniques in NeRF to allow drawing samples along a curved path tracked by the Eikonal equation. The results indicate that our framework outperforms the state-of-the-art method both quantitatively and qualitatively, demonstrating better performance on the perceptual similarity metric and an apparent improvement in the rendering quality on several synthetic and real scenes.
GPR-Net: Multi-view Layout Estimation via a Geometry-aware Panorama Registration Network
Oct 20, 2022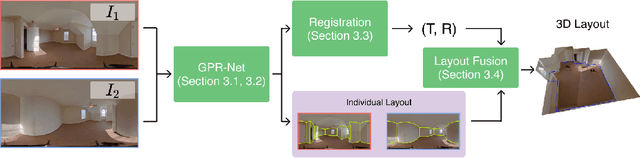

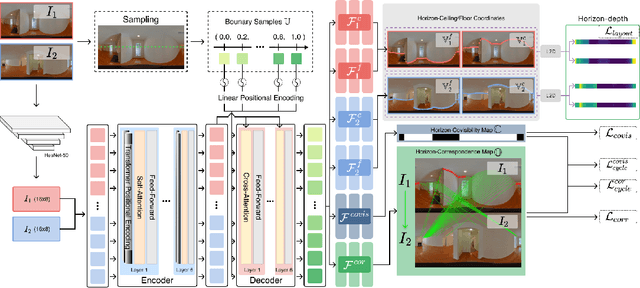

Reconstructing 3D layouts from multiple $360^{\circ}$ panoramas has received increasing attention recently as estimating a complete layout of a large-scale and complex room from a single panorama is very difficult. The state-of-the-art method, called PSMNet, introduces the first learning-based framework that jointly estimates the room layout and registration given a pair of panoramas. However, PSMNet relies on an approximate (i.e., "noisy") registration as input. Obtaining this input requires a solution for wide baseline registration which is a challenging problem. In this work, we present a complete multi-view panoramic layout estimation framework that jointly learns panorama registration and layout estimation given a pair of panoramas without relying on a pose prior. The major improvement over PSMNet comes from a novel Geometry-aware Panorama Registration Network or GPR-Net that effectively tackles the wide baseline registration problem by exploiting the layout geometry and computing fine-grained correspondences on the layout boundaries, instead of the global pixel-space. Our architecture consists of two parts. First, given two panoramas, we adopt a vision transformer to learn a set of 1D horizon features sampled on the panorama. These 1D horizon features encode the depths of individual layout boundary samples and the correspondence and covisibility maps between layout boundaries. We then exploit a non-linear registration module to convert these 1D horizon features into a set of corresponding 2D boundary points on the layout. Finally, we estimate the final relative camera pose via RANSAC and obtain the complete layout simply by taking the union of registered layouts. Experimental results indicate that our method achieves state-of-the-art performance in both panorama registration and layout estimation on a large-scale indoor panorama dataset ZInD.
Instance-aware Image Colorization
May 21, 2020

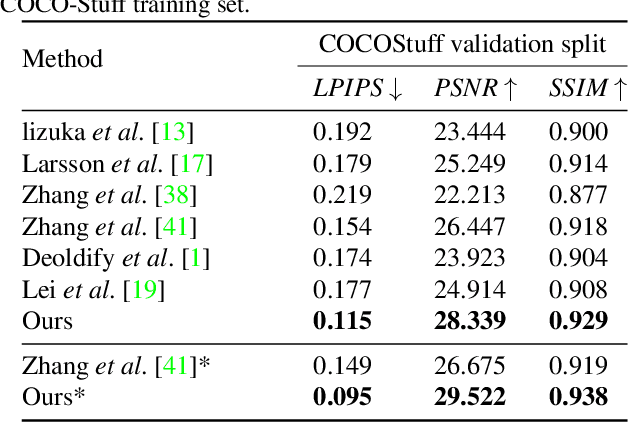
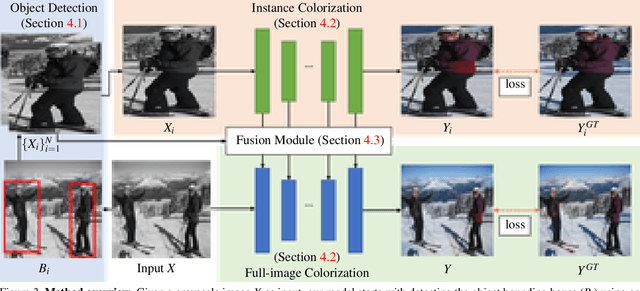
Image colorization is inherently an ill-posed problem with multi-modal uncertainty. Previous methods leverage the deep neural network to map input grayscale images to plausible color outputs directly. Although these learning-based methods have shown impressive performance, they usually fail on the input images that contain multiple objects. The leading cause is that existing models perform learning and colorization on the entire image. In the absence of a clear figure-ground separation, these models cannot effectively locate and learn meaningful object-level semantics. In this paper, we propose a method for achieving instance-aware colorization. Our network architecture leverages an off-the-shelf object detector to obtain cropped object images and uses an instance colorization network to extract object-level features. We use a similar network to extract the full-image features and apply a fusion module to full object-level and image-level features to predict the final colors. Both colorization networks and fusion modules are learned from a large-scale dataset. Experimental results show that our work outperforms existing methods on different quality metrics and achieves state-of-the-art performance on image colorization.
Vid2Curve: Simultaneous Camera Motion Estimation and Thin Structure Reconstruction from an RGB Video
May 20, 2020


Thin structures, such as wire-frame sculptures, fences, cables, power lines, and tree branches, are common in the real world. It is extremely challenging to acquire their 3D digital models using traditional image-based or depth-based reconstruction methods because thin structures often lack distinct point features and have severe self-occlusion. We propose the first approach that simultaneously estimates camera motion and reconstructs the geometry of complex 3D thin structures in high quality from a color video captured by a handheld camera. Specifically, we present a new curve-based approach to estimate accurate camera poses by establishing correspondences between featureless thin objects in the foreground in consecutive video frames, without requiring visual texture in the background scene to lock on. Enabled by this effective curve-based camera pose estimation strategy, we develop an iterative optimization method with tailored measures on geometry, topology as well as self-occlusion handling for reconstructing 3D thin structures. Extensive validations on a variety of thin structures show that our method achieves accurate camera pose estimation and faithful reconstruction of 3D thin structures with complex shape and topology at a level that has not been attained by other existing reconstruction methods.
3D Manhattan Room Layout Reconstruction from a Single 360 Image
Oct 24, 2019



Recent approaches for predicting layouts from 360 panoramas produce excellent results. These approaches build on a common framework consisting of three steps: a pre-processing step based on edge-based alignment, prediction of layout elements, and a post-processing step by fitting a 3D layout to the layout elements. Until now, it has been difficult to compare the methods due to multiple different design decisions, such as the encoding network (e.g. SegNet or ResNet), type of elements predicted (e.g. corners, wall/floor boundaries, or semantic segmentation), or method of fitting the 3D layout. To address this challenge, we summarize and describe the common framework, the variants, and the impact of the design decisions. For a complete evaluation, we also propose extended annotations for the Matterport3D dataset, and introduce two depth-based evaluation metrics.
DuLa-Net: A Dual-Projection Network for Estimating Room Layouts from a Single RGB Panorama
Nov 29, 2018

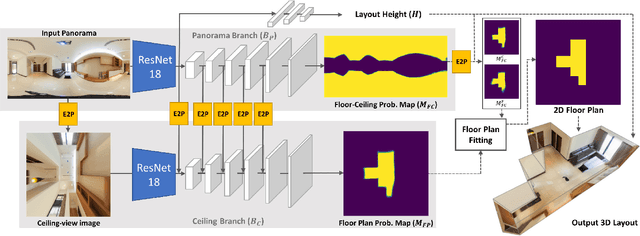

We present a deep learning framework, called DuLa-Net, to predict Manhattan-world 3D room layouts from a single RGB panorama. To achieve better prediction accuracy, our method leverages two projections of the panorama at once, namely the equirectangular panorama-view and the perspective ceiling-view, that each contains different clues about the room layouts. Our network architecture consists of two encoder-decoder branches for analyzing each of the two views. In addition, a novel feature fusion structure is proposed to connect the two branches, which are then jointly trained to predict the 2D floor plans and layout heights. To learn more complex room layouts, we introduce the Realtor360 dataset that contains panoramas of Manhattan-world room layouts with different numbers of corners. Experimental results show that our work outperforms recent state-of-the-art in prediction accuracy and performance, especially in the rooms with non-cuboid layouts.