 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoST: Level of Semantics Tokenization for 3D Shapes
Mar 18, 2026Tokenization is a fundamental technique in the generative modeling of various modalities. In particular, it plays a critical role in autoregressive (AR) models, which have recently emerged as a compelling option for 3D generation. However, optimal tokenization of 3D shapes remains an open question. State-of-the-art (SOTA) methods primarily rely on geometric level-of-detail (LoD) hierarchies, originally designed for rendering and compression. These spatial hierarchies are often token-inefficient and lack semantic coherence for AR modeling. We propose Level-of-Semantics Tokenization (LoST), which orders tokens by semantic salience, such that early prefixes decode into complete, plausible shapes that possess principal semantics, while subsequent tokens refine instance-specific geometric and semantic details. To train LoST, we introduce Relational Inter-Distance Alignment (RIDA), a novel 3D semantic alignment loss that aligns the relational structure of the 3D shape latent space with that of the semantic DINO feature space. Experiments show that LoST achieves SOTA reconstruction, surpassing previous LoD-based 3D shape tokenizers by large margins on both geometric and semantic reconstruction metrics. Moreover, LoST achieves efficient, high-quality AR 3D generation and enables downstream tasks like semantic retrieval, while using only 0.1%-10% of the tokens needed by prior AR models.
A Mixed Diet Makes DINO An Omnivorous Vision Encoder
Feb 27, 2026Pre-trained vision encoders like DINOv2 have demonstrated exceptional performance on unimodal tasks. However, we observe that their feature representations are poorly aligned across different modalities. For instance, the feature embedding for an RGB image and its corresponding depth map of the same scene exhibit a cosine similarity that is nearly identical to that of two random, unrelated images. To address this, we propose the Omnivorous Vision Encoder, a novel framework that learns a modality-agnostic feature space. We train the encoder with a dual objective: first, to maximize the feature alignment between different modalities of the same scene; and second, a distillation objective that anchors the learned representations to the output of a fully frozen teacher such as DINOv2. The resulting student encoder becomes "omnivorous" by producing a consistent, powerful embedding for a given scene, regardless of the input modality (RGB, Depth, Segmentation, etc.). This approach enables robust cross-modal understanding while retaining the discriminative semantics of the original foundation model.
ActionMesh: Animated 3D Mesh Generation with Temporal 3D Diffusion
Jan 22, 2026Generating animated 3D objects is at the heart of many applications, yet most advanced works are typically difficult to apply in practice because of their limited setup, their long runtime, or their limited quality. We introduce ActionMesh, a generative model that predicts production-ready 3D meshes "in action" in a feed-forward manner. Drawing inspiration from early video models, our key insight is to modify existing 3D diffusion models to include a temporal axis, resulting in a framework we dubbed "temporal 3D diffusion". Specifically, we first adapt the 3D diffusion stage to generate a sequence of synchronized latents representing time-varying and independent 3D shapes. Second, we design a temporal 3D autoencoder that translates a sequence of independent shapes into the corresponding deformations of a pre-defined reference shape, allowing us to build an animation. Combining these two components, ActionMesh generates animated 3D meshes from different inputs like a monocular video, a text description, or even a 3D mesh with a text prompt describing its animation. Besides, compared to previous approaches, our method is fast and produces results that are rig-free and topology consistent, hence enabling rapid iteration and seamless applications like texturing and retargeting. We evaluate our model on standard video-to-4D benchmarks (Consistent4D, Objaverse) and report state-of-the-art performances on both geometric accuracy and temporal consistency, demonstrating that our model can deliver animated 3D meshes with unprecedented speed and quality.
Beyond the Visible: Disocclusion-Aware Editing via Proxy Dynamic Graphs
Dec 16, 2025



We address image-to-video generation with explicit user control over the final frame's disoccluded regions. Current image-to-video pipelines produce plausible motion but struggle to generate predictable, articulated motions while enforcing user-specified content in newly revealed areas. Our key idea is to separate motion specification from appearance synthesis: we introduce a lightweight, user-editable Proxy Dynamic Graph (PDG) that deterministically yet approximately drives part motion, while a frozen diffusion prior is used to synthesize plausible appearance that follows that motion. In our training-free pipeline, the user loosely annotates and reposes a PDG, from which we compute a dense motion flow to leverage diffusion as a motion-guided shader. We then let the user edit appearance in the disoccluded areas of the image, and exploit the visibility information encoded by the PDG to perform a latent-space composite that reconciles motion with user intent in these areas. This design yields controllable articulation and user control over disocclusions without fine-tuning. We demonstrate clear advantages against state-of-the-art alternatives towards images turned into short videos of articulated objects, furniture, vehicles, and deformables. Our method mixes generative control, in the form of loose pose and structure, with predictable controls, in the form of appearance specification in the final frame in the disoccluded regions, unlocking a new image-to-video workflow. Code will be released on acceptance. Project page: https://anranqi.github.io/beyond-visible.github.io/
WorldReel: 4D Video Generation with Consistent Geometry and Motion Modeling
Dec 08, 2025Recent video generators achieve striking photorealism, yet remain fundamentally inconsistent in 3D. We present WorldReel, a 4D video generator that is natively spatio-temporally consistent. WorldReel jointly produces RGB frames together with 4D scene representations, including pointmaps, camera trajectory, and dense flow mapping, enabling coherent geometry and appearance modeling over time. Our explicit 4D representation enforces a single underlying scene that persists across viewpoints and dynamic content, yielding videos that remain consistent even under large non-rigid motion and significant camera movement. We train WorldReel by carefully combining synthetic and real data: synthetic data providing precise 4D supervision (geometry, motion, and camera), while real videos contribute visual diversity and realism. This blend allows WorldReel to generalize to in-the-wild footage while preserving strong geometric fidelity. Extensive experiments demonstrate that WorldReel sets a new state-of-the-art for consistent video generation with dynamic scenes and moving cameras, improving metrics of geometric consistency, motion coherence, and reducing view-time artifacts over competing methods. We believe that WorldReel brings video generation closer to 4D-consistent world modeling, where agents can render, interact, and reason about scenes through a single and stable spatiotemporal representation.
Hand-Shadow Poser
May 11, 2025



Hand shadow art is a captivating art form, creatively using hand shadows to reproduce expressive shapes on the wall. In this work, we study an inverse problem: given a target shape, find the poses of left and right hands that together best produce a shadow resembling the input. This problem is nontrivial, since the design space of 3D hand poses is huge while being restrictive due to anatomical constraints. Also, we need to attend to the input's shape and crucial features, though the input is colorless and textureless. To meet these challenges, we design Hand-Shadow Poser, a three-stage pipeline, to decouple the anatomical constraints (by hand) and semantic constraints (by shadow shape): (i) a generative hand assignment module to explore diverse but reasonable left/right-hand shape hypotheses; (ii) a generalized hand-shadow alignment module to infer coarse hand poses with a similarity-driven strategy for selecting hypotheses; and (iii) a shadow-feature-aware refinement module to optimize the hand poses for physical plausibility and shadow feature preservation. Further, we design our pipeline to be trainable on generic public hand data, thus avoiding the need for any specialized training dataset. For method validation, we build a benchmark of 210 diverse shadow shapes of varying complexity and a comprehensive set of metrics, including a novel DINOv2-based evaluation metric. Through extensive comparisons with multiple baselines and user studies, our approach is demonstrated to effectively generate bimanual hand poses for a large variety of hand shapes for over 85% of the benchmark cases.
MonetGPT: Solving Puzzles Enhances MLLMs' Image Retouching Skills
May 09, 2025



Retouching is an essential task in post-manipulation of raw photographs. Generative editing, guided by text or strokes, provides a new tool accessible to users but can easily change the identity of the original objects in unacceptable and unpredictable ways. In contrast, although traditional procedural edits, as commonly supported by photoediting tools (e.g., Gimp, Lightroom), are conservative, they are still preferred by professionals. Unfortunately, professional quality retouching involves many individual procedural editing operations that is challenging to plan for most novices. In this paper, we ask if a multimodal large language model (MLLM) can be taught to critique raw photographs, suggest suitable remedies, and finally realize them with a given set of pre-authored procedural image operations. We demonstrate that MLLMs can be first made aware of the underlying image processing operations, by training them to solve specially designed visual puzzles. Subsequently, such an operation-aware MLLM can both plan and propose edit sequences. To facilitate training, given a set of expert-edited photos, we synthesize a reasoning dataset by procedurally manipulating the expert edits and then grounding a pretrained LLM on the visual adjustments, to synthesize reasoning for finetuning. The proposed retouching operations are, by construction, understandable by the users, preserve object details and resolution, and can be optionally overridden. We evaluate our setup on a variety of test examples and show advantages, in terms of explainability and identity preservation, over existing generative and other procedural alternatives. Code, data, models, and supplementary results can be found via our project website at https://monetgpt.github.io.
SMF: Template-free and Rig-free Animation Transfer using Kinetic Codes
Apr 07, 2025Animation retargeting involves applying a sparse motion description (e.g., 2D/3D keypoint sequences) to a given character mesh to produce a semantically plausible and temporally coherent full-body motion. Existing approaches come with a mix of restrictions - they require annotated training data, assume access to template-based shape priors or artist-designed deformation rigs, suffer from limited generalization to unseen motion and/or shapes, or exhibit motion jitter. We propose Self-supervised Motion Fields (SMF) as a self-supervised framework that can be robustly trained with sparse motion representations, without requiring dataset specific annotations, templates, or rigs. At the heart of our method are Kinetic Codes, a novel autoencoder-based sparse motion encoding, that exposes a semantically rich latent space simplifying large-scale training. Our architecture comprises dedicated spatial and temporal gradient predictors, which are trained end-to-end. The resultant network, regularized by the Kinetic Codes's latent space, has good generalization across shapes and motions. We evaluated our method on unseen motion sampled from AMASS, D4D, Mixamo, and raw monocular video for animation transfer on various characters with varying shapes and topology. We report a new SoTA on the AMASS dataset in the context of generalization to unseen motion. Project webpage at https://motionfields.github.io/
LIM: Large Interpolator Model for Dynamic Reconstruction
Mar 28, 2025



Reconstructing dynamic assets from video data is central to many in computer vision and graphics tasks. Existing 4D reconstruction approaches are limited by category-specific models or slow optimization-based methods. Inspired by the recent Large Reconstruction Model (LRM), we present the Large Interpolation Model (LIM), a transformer-based feed-forward solution, guided by a novel causal consistency loss, for interpolating implicit 3D representations across time. Given implicit 3D representations at times $t_0$ and $t_1$, LIM produces a deformed shape at any continuous time $t\in[t_0,t_1]$, delivering high-quality interpolated frames in seconds. Furthermore, LIM allows explicit mesh tracking across time, producing a consistently uv-textured mesh sequence ready for integration into existing production pipelines. We also use LIM, in conjunction with a diffusion-based multiview generator, to produce dynamic 4D reconstructions from monocular videos. We evaluate LIM on various dynamic datasets, benchmarking against image-space interpolation methods (e.g., FiLM) and direct triplane linear interpolation, and demonstrate clear advantages. In summary, LIM is the first feed-forward model capable of high-speed tracked 4D asset reconstruction across diverse categories.
ShapeLib: designing a library of procedural 3D shape abstractions with Large Language Models
Feb 13, 2025

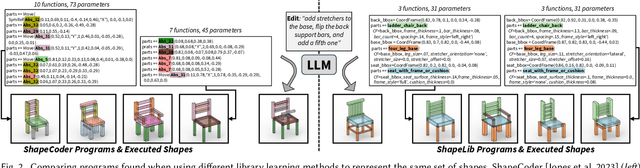

Procedural representations are desirable, versatile, and popular shape encodings. Authoring them, either manually or using data-driven procedures, remains challenging, as a well-designed procedural representation should be compact, intuitive, and easy to manipulate. A long-standing problem in shape analysis studies how to discover a reusable library of procedural functions, with semantically aligned exposed parameters, that can explain an entire shape family. We present ShapeLib as the first method that leverages the priors of frontier LLMs to design a library of 3D shape abstraction functions. Our system accepts two forms of design intent: text descriptions of functions to include in the library and a seed set of exemplar shapes. We discover procedural abstractions that match this design intent by proposing, and then validating, function applications and implementations. The discovered shape functions in the library are not only expressive but also generalize beyond the seed set to a full family of shapes. We train a recognition network that learns to infer shape programs based on our library from different visual modalities (primitives, voxels, point clouds). Our shape functions have parameters that are semantically interpretable and can be modified to produce plausible shape variations. We show that this allows inferred programs to be successfully manipulated by an LLM given a text prompt. We evaluate ShapeLib on different datasets and show clear advantages over existing methods and alternative formulations.