 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch2Arti: Sketch-based Articulation Modeling of CAD Objects
Apr 28, 2026Articulation modeling aims to infer movable parts and their motion parameters for a 3D object, enabling interactive animation, simulation, and shape editing. In this paper, we present Sketch2Arti, the first sketch-based articulation modeling system for CAD objects. Our key observation is that designers naturally communicate articulation intent through lightweight sketches (e.g., arrows and strokes) that indicate how parts should move, yet translating such sketches into articulated 3D models remains largely manual. Sketch2Arti bridges this gap by enabling users to specify articulation through simple 2D sketches drawn from a chosen viewpoint. Given a CAD model and user sketches, our approach automatically discovers the corresponding movable parts and predicts their motion parameters, allowing iterative modeling of multiple articulations on complex objects with fine-grained control. Importantly, Sketch2Arti is trained in a category-agnostic manner without requiring object category information, leading to strong generalization to diverse objects beyond existing articulation datasets. Moreover, for shell models lacking interior structures, Sketch2Arti supports controllable internal completion guided by user sketches, generating plausible internal components consistent with the existing geometry and predicted motion constraints. Comprehensive experiments and user evaluations demonstrate the effectiveness, controllability, and generalization of Sketch2Arti. The code, dataset, and the prototype system are at https://arlo-yang.github.io/Sketch2Arti.
DancingBox: A Lightweight MoCap System for Character Animation from Physical Proxies
Mar 18, 2026Creating compelling 3D character animations typically requires either expert use of professional software or expensive motion capture systems operated by skilled actors. We present DancingBox, a lightweight, vision-based system that makes motion capture accessible to novices by reimagining the process as digital puppetry. Instead of tracking precise human motions, DancingBox captures the approximate movements of everyday objects manipulated by users with a single webcam. These coarse proxy motions are then refined into realistic character animations by conditioning a generative motion model on bounding-box representations, enriched with human motion priors learned from large-scale datasets. To overcome the lack of paired proxy-animation data, we synthesize training pairs by converting existing motion capture sequences into proxy representations. A user study demonstrates that DancingBox enables intuitive and creative character animation using diverse proxies, from plush toys to bananas, lowering the barrier to entry for novice animators.
Beyond the Visible: Disocclusion-Aware Editing via Proxy Dynamic Graphs
Dec 16, 2025



We address image-to-video generation with explicit user control over the final frame's disoccluded regions. Current image-to-video pipelines produce plausible motion but struggle to generate predictable, articulated motions while enforcing user-specified content in newly revealed areas. Our key idea is to separate motion specification from appearance synthesis: we introduce a lightweight, user-editable Proxy Dynamic Graph (PDG) that deterministically yet approximately drives part motion, while a frozen diffusion prior is used to synthesize plausible appearance that follows that motion. In our training-free pipeline, the user loosely annotates and reposes a PDG, from which we compute a dense motion flow to leverage diffusion as a motion-guided shader. We then let the user edit appearance in the disoccluded areas of the image, and exploit the visibility information encoded by the PDG to perform a latent-space composite that reconciles motion with user intent in these areas. This design yields controllable articulation and user control over disocclusions without fine-tuning. We demonstrate clear advantages against state-of-the-art alternatives towards images turned into short videos of articulated objects, furniture, vehicles, and deformables. Our method mixes generative control, in the form of loose pose and structure, with predictable controls, in the form of appearance specification in the final frame in the disoccluded regions, unlocking a new image-to-video workflow. Code will be released on acceptance. Project page: https://anranqi.github.io/beyond-visible.github.io/
SMooGPT: Stylized Motion Generation using Large Language Models
Sep 04, 2025Stylized motion generation is actively studied in computer graphics, especially benefiting from the rapid advances in diffusion models. The goal of this task is to produce a novel motion respecting both the motion content and the desired motion style, e.g., ``walking in a loop like a Monkey''. Existing research attempts to address this problem via motion style transfer or conditional motion generation. They typically embed the motion style into a latent space and guide the motion implicitly in a latent space as well. Despite the progress, their methods suffer from low interpretability and control, limited generalization to new styles, and fail to produce motions other than ``walking'' due to the strong bias in the public stylization dataset. In this paper, we propose to solve the stylized motion generation problem from a new perspective of reasoning-composition-generation, based on our observations: i) human motion can often be effectively described using natural language in a body-part centric manner, ii) LLMs exhibit a strong ability to understand and reason about human motion, and iii) human motion has an inherently compositional nature, facilitating the new motion content or style generation via effective recomposing. We thus propose utilizing body-part text space as an intermediate representation, and present SMooGPT, a fine-tuned LLM, acting as a reasoner, composer, and generator when generating the desired stylized motion. Our method executes in the body-part text space with much higher interpretability, enabling fine-grained motion control, effectively resolving potential conflicts between motion content and style, and generalizes well to new styles thanks to the open-vocabulary ability of LLMs. Comprehensive experiments and evaluations, and a user perceptual study, demonstrate the effectiveness of our approach, especially under the pure text-driven stylized motion generation.
Sketch2Anim: Towards Transferring Sketch Storyboards into 3D Animation
Apr 27, 2025



Storyboarding is widely used for creating 3D animations. Animators use the 2D sketches in storyboards as references to craft the desired 3D animations through a trial-and-error process. The traditional approach requires exceptional expertise and is both labor-intensive and time-consuming. Consequently, there is a high demand for automated methods that can directly translate 2D storyboard sketches into 3D animations. This task is under-explored to date and inspired by the significant advancements of motion diffusion models, we propose to address it from the perspective of conditional motion synthesis. We thus present Sketch2Anim, composed of two key modules for sketch constraint understanding and motion generation. Specifically, due to the large domain gap between the 2D sketch and 3D motion, instead of directly conditioning on 2D inputs, we design a 3D conditional motion generator that simultaneously leverages 3D keyposes, joint trajectories, and action words, to achieve precise and fine-grained motion control. Then, we invent a neural mapper dedicated to aligning user-provided 2D sketches with their corresponding 3D keyposes and trajectories in a shared embedding space, enabling, for the first time, direct 2D control of motion generation. Our approach successfully transfers storyboards into high-quality 3D motions and inherently supports direct 3D animation editing, thanks to the flexibility of our multi-conditional motion generator. Comprehensive experiments and evaluations, and a user perceptual study demonstrate the effectiveness of our approach.
PoseTraj: Pose-Aware Trajectory Control in Video Diffusion
Mar 20, 2025



Recent advancements in trajectory-guided video generation have achieved notable progress. However, existing models still face challenges in generating object motions with potentially changing 6D poses under wide-range rotations, due to limited 3D understanding. To address this problem, we introduce PoseTraj, a pose-aware video dragging model for generating 3D-aligned motion from 2D trajectories. Our method adopts a novel two-stage pose-aware pretraining framework, improving 3D understanding across diverse trajectories. Specifically, we propose a large-scale synthetic dataset PoseTraj-10K, containing 10k videos of objects following rotational trajectories, and enhance the model perception of object pose changes by incorporating 3D bounding boxes as intermediate supervision signals. Following this, we fine-tune the trajectory-controlling module on real-world videos, applying an additional camera-disentanglement module to further refine motion accuracy. Experiments on various benchmark datasets demonstrate that our method not only excels in 3D pose-aligned dragging for rotational trajectories but also outperforms existing baselines in trajectory accuracy and video quality.
CrossSDF: 3D Reconstruction of Thin Structures From Cross-Sections
Dec 05, 2024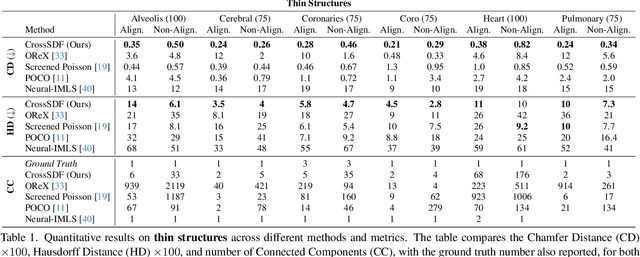
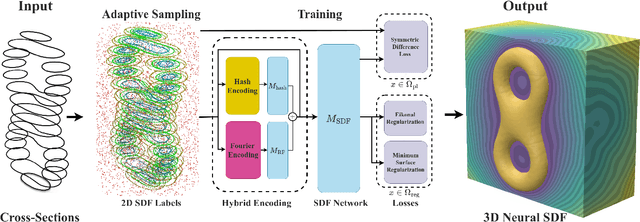
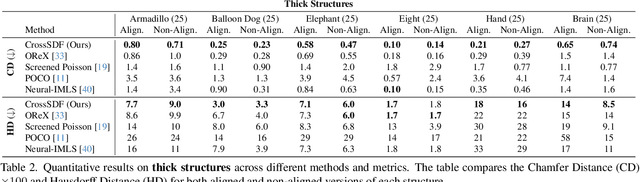

Reconstructing complex structures from planar cross-sections is a challenging problem, with wide-reaching applications in medical imaging, manufacturing, and topography. Out-of-the-box point cloud reconstruction methods can often fail due to the data sparsity between slicing planes, while current bespoke methods struggle to reconstruct thin geometric structures and preserve topological continuity. This is important for medical applications where thin vessel structures are present in CT and MRI scans. This paper introduces \method, a novel approach for extracting a 3D signed distance field from 2D signed distances generated from planar contours. Our approach makes the training of neural SDFs contour-aware by using losses designed for the case where geometry is known within 2D slices. Our results demonstrate a significant improvement over existing methods, effectively reconstructing thin structures and producing accurate 3D models without the interpolation artifacts or over-smoothing of prior approaches.
PCDreamer: Point Cloud Completion Through Multi-view Diffusion Priors
Nov 28, 2024



This paper presents PCDreamer, a novel method for point cloud completion. Traditional methods typically extract features from partial point clouds to predict missing regions, but the large solution space often leads to unsatisfactory results. More recent approaches have started to use images as extra guidance, effectively improving performance, but obtaining paired data of images and partial point clouds is challenging in practice. To overcome these limitations, we harness the relatively view-consistent multi-view diffusion priors within large models, to generate novel views of the desired shape. The resulting image set encodes both global and local shape cues, which is especially beneficial for shape completion. To fully exploit the priors, we have designed a shape fusion module for producing an initial complete shape from multi-modality input (\ie, images and point clouds), and a follow-up shape consolidation module to obtain the final complete shape by discarding unreliable points introduced by the inconsistency from diffusion priors. Extensive experimental results demonstrate our superior performance, especially in recovering fine details.
DepthCues: Evaluating Monocular Depth Perception in Large Vision Models
Nov 26, 2024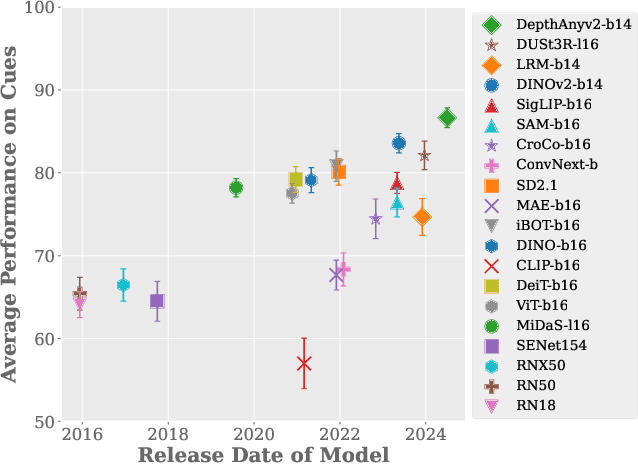
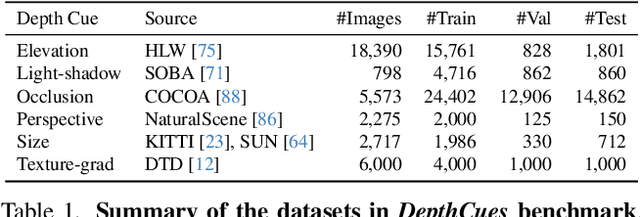
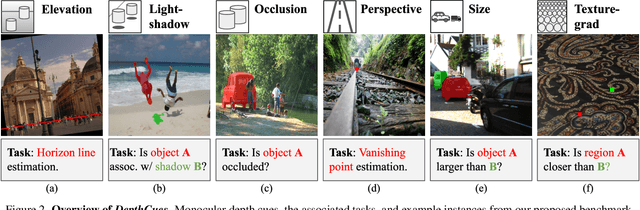
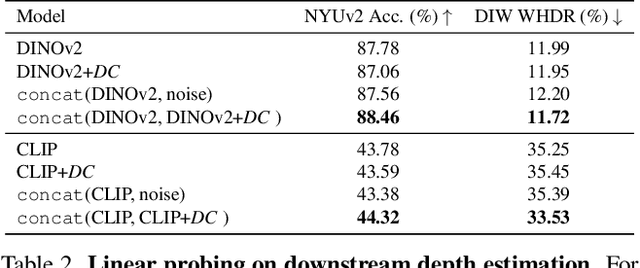
Large-scale pre-trained vision models are becoming increasingly prevalent, offering expressive and generalizable visual representations that benefit various downstream tasks. Recent studies on the emergent properties of these models have revealed their high-level geometric understanding, in particular in the context of depth perception. However, it remains unclear how depth perception arises in these models without explicit depth supervision provided during pre-training. To investigate this, we examine whether the monocular depth cues, similar to those used by the human visual system, emerge in these models. We introduce a new benchmark, DepthCues, designed to evaluate depth cue understanding, and present findings across 20 diverse and representative pre-trained vision models. Our analysis shows that human-like depth cues emerge in more recent larger models. We also explore enhancing depth perception in large vision models by fine-tuning on DepthCues, and find that even without dense depth supervision, this improves depth estimation. To support further research, our benchmark and evaluation code will be made publicly available for studying depth perception in vision models.
VQ-SGen: A Vector Quantized Stroke Representation for Sketch Generation
Nov 25, 2024



This paper presents VQ-SGen, a novel algorithm for high-quality sketch generation. Recent approaches have often framed the task as pixel-based generation either as a whole or part-by-part, neglecting the intrinsic and contextual relationships among individual strokes, such as the shape and spatial positioning of both proximal and distant strokes. To overcome these limitations, we propose treating each stroke within a sketch as an entity and introducing a vector-quantized (VQ) stroke representation for fine-grained sketch generation. Our method follows a two-stage framework - in the first stage, we decouple each stroke's shape and location information to ensure the VQ representation prioritizes stroke shape learning. In the second stage, we feed the precise and compact representation into an auto-decoding Transformer to incorporate stroke semantics, positions, and shapes into the generation process. By utilizing tokenized stroke representation, our approach generates strokes with high fidelity and facilitates novel applications, such as conditional generation and semantic-aware stroke editing. Comprehensive experiments demonstrate our method surpasses existing state-of-the-art techniques, underscoring its effectiveness. The code and model will be made publicly available upon publication.