 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSegAgent: Zero-Shot Tooth Segmentation via Geometry-Aware Vision-Language Agents
Mar 20, 2026Automatic tooth segmentation and identification from intra-oral scanned 3D models are fundamental problems in digital dentistry, yet most existing approaches rely on task-specific 3D neural networks trained with densely annotated datasets, resulting in high annotation cost and limited generalization to scans from unseen sources. Thus, we propose TSegAgent, which addresses these challenges by reformulating dental analysis as a zero-shot geometric reasoning problem rather than a purely data-driven recognition task. The key idea is to combine the representational capacity of general-purpose foundation models with explicit geometric inductive biases derived from dental anatomy. Instead of learning dental-specific features, the proposed framework leverages multi-view visual abstraction and geometry-grounded reasoning to infer tooth instances and identities without task-specific training. By explicitly encoding structural constraints such as dental arch organization and volumetric relationships, the method reduces uncertainty in ambiguous cases and mitigates overfitting to particular shape distributions. Experimental results demonstrate that this reasoning-oriented formulation enables accurate and reliable tooth segmentation and identification with low computational and annotation cost, while exhibiting strong generalization across diverse and previously unseen dental scans.
Detecting Dental Landmarks from Intraoral 3D Scans: the 3DTeethLand challenge
Dec 09, 2025Teeth landmark detection is a critical task in modern clinical orthodontics. Their precise identification enables advanced diagnostics, facilitates personalized treatment strategies, and supports more effective monitoring of treatment progress in clinical dentistry. However, several significant challenges may arise due to the intricate geometry of individual teeth and the substantial variations observed across different individuals. To address these complexities, the development of advanced techniques, especially through the application of deep learning, is essential for the precise and reliable detection of 3D tooth landmarks. In this context, the 3DTeethLand challenge was held in collaboration with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2024, calling for algorithms focused on teeth landmark detection from intraoral 3D scans. This challenge introduced the first publicly available dataset for 3D teeth landmark detection, offering a valuable resource to assess the state-of-the-art methods in this task and encourage the community to provide methodological contributions towards the resolution of their problem with significant clinical implications.
NeuVAS: Neural Implicit Surfaces for Variational Shape Modeling
Jun 16, 2025Neural implicit shape representation has drawn significant attention in recent years due to its smoothness, differentiability, and topological flexibility. However, directly modeling the shape of a neural implicit surface, especially as the zero-level set of a neural signed distance function (SDF), with sparse geometric control is still a challenging task. Sparse input shape control typically includes 3D curve networks or, more generally, 3D curve sketches, which are unstructured and cannot be connected to form a curve network, and therefore more difficult to deal with. While 3D curve networks or curve sketches provide intuitive shape control, their sparsity and varied topology pose challenges in generating high-quality surfaces to meet such curve constraints. In this paper, we propose NeuVAS, a variational approach to shape modeling using neural implicit surfaces constrained under sparse input shape control, including unstructured 3D curve sketches as well as connected 3D curve networks. Specifically, we introduce a smoothness term based on a functional of surface curvatures to minimize shape variation of the zero-level set surface of a neural SDF. We also develop a new technique to faithfully model G0 sharp feature curves as specified in the input curve sketches. Comprehensive comparisons with the state-of-the-art methods demonstrate the significant advantages of our method.
Ev-Layout: A Large-scale Event-based Multi-modal Dataset for Indoor Layout Estimation and Tracking
Mar 11, 2025This paper presents Ev-Layout, a novel large-scale event-based multi-modal dataset designed for indoor layout estimation and tracking. Ev-Layout makes key contributions to the community by: Utilizing a hybrid data collection platform (with a head-mounted display and VR interface) that integrates both RGB and bio-inspired event cameras to capture indoor layouts in motion. Incorporating time-series data from inertial measurement units (IMUs) and ambient lighting conditions recorded during data collection to highlight the potential impact of motion speed and lighting on layout estimation accuracy. The dataset consists of 2.5K sequences, including over 771.3K RGB images and 10 billion event data points. Of these, 39K images are annotated with indoor layouts, enabling research in both event-based and video-based indoor layout estimation. Based on the dataset, we propose an event-based layout estimation pipeline with a novel event-temporal distribution feature module to effectively aggregate the spatio-temporal information from events. Additionally, we introduce a spatio-temporal feature fusion module that can be easily integrated into a transformer module for fusion purposes. Finally, we conduct benchmarking and extensive experiments on the Ev-Layout dataset, demonstrating that our approach significantly improves the accuracy of dynamic indoor layout estimation compared to existing event-based methods.
PCDreamer: Point Cloud Completion Through Multi-view Diffusion Priors
Nov 28, 2024



This paper presents PCDreamer, a novel method for point cloud completion. Traditional methods typically extract features from partial point clouds to predict missing regions, but the large solution space often leads to unsatisfactory results. More recent approaches have started to use images as extra guidance, effectively improving performance, but obtaining paired data of images and partial point clouds is challenging in practice. To overcome these limitations, we harness the relatively view-consistent multi-view diffusion priors within large models, to generate novel views of the desired shape. The resulting image set encodes both global and local shape cues, which is especially beneficial for shape completion. To fully exploit the priors, we have designed a shape fusion module for producing an initial complete shape from multi-modality input (\ie, images and point clouds), and a follow-up shape consolidation module to obtain the final complete shape by discarding unreliable points introduced by the inconsistency from diffusion priors. Extensive experimental results demonstrate our superior performance, especially in recovering fine details.
Monge-Ampere Regularization for Learning Arbitrary Shapes from Point Clouds
Oct 24, 2024As commonly used implicit geometry representations, the signed distance function (SDF) is limited to modeling watertight shapes, while the unsigned distance function (UDF) is capable of representing various surfaces. However, its inherent theoretical shortcoming, i.e., the non-differentiability at the zero level set, would result in sub-optimal reconstruction quality. In this paper, we propose the scaled-squared distance function (S$^{2}$DF), a novel implicit surface representation for modeling arbitrary surface types. S$^{2}$DF does not distinguish between inside and outside regions while effectively addressing the non-differentiability issue of UDF at the zero level set. We demonstrate that S$^{2}$DF satisfies a second-order partial differential equation of Monge-Ampere-type, allowing us to develop a learning pipeline that leverages a novel Monge-Ampere regularization to directly learn S$^{2}$DF from raw unoriented point clouds without supervision from ground-truth S$^{2}$DF values. Extensive experiments across multiple datasets show that our method significantly outperforms state-of-the-art supervised approaches that require ground-truth surface information as supervision for training. The code will be publicly available at https://github.com/chuanxiang-yang/S2DF.
iPUNet:Iterative Cross Field Guided Point Cloud Upsampling
Oct 13, 2023Point clouds acquired by 3D scanning devices are often sparse, noisy, and non-uniform, causing a loss of geometric features. To facilitate the usability of point clouds in downstream applications, given such input, we present a learning-based point upsampling method, i.e., iPUNet, which generates dense and uniform points at arbitrary ratios and better captures sharp features. To generate feature-aware points, we introduce cross fields that are aligned to sharp geometric features by self-supervision to guide point generation. Given cross field defined frames, we enable arbitrary ratio upsampling by learning at each input point a local parameterized surface. The learned surface consumes the neighboring points and 2D tangent plane coordinates as input, and maps onto a continuous surface in 3D where arbitrary ratios of output points can be sampled. To solve the non-uniformity of input points, on top of the cross field guided upsampling, we further introduce an iterative strategy that refines the point distribution by moving sparse points onto the desired continuous 3D surface in each iteration. Within only a few iterations, the sparse points are evenly distributed and their corresponding dense samples are more uniform and better capture geometric features. Through extensive evaluations on diverse scans of objects and scenes, we demonstrate that iPUNet is robust to handle noisy and non-uniformly distributed inputs, and outperforms state-of-the-art point cloud upsampling methods.
3DTeethSeg'22: 3D Teeth Scan Segmentation and Labeling Challenge
May 29, 2023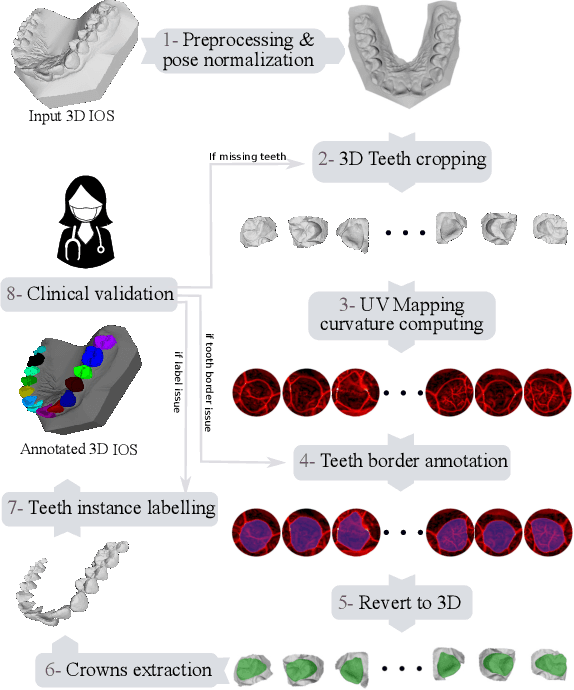
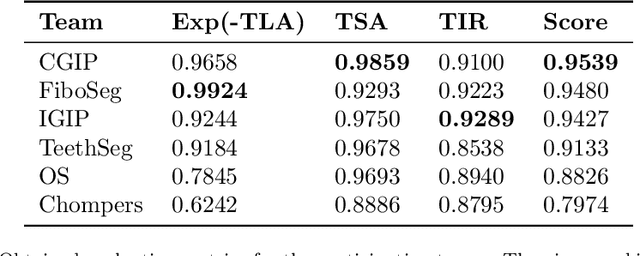
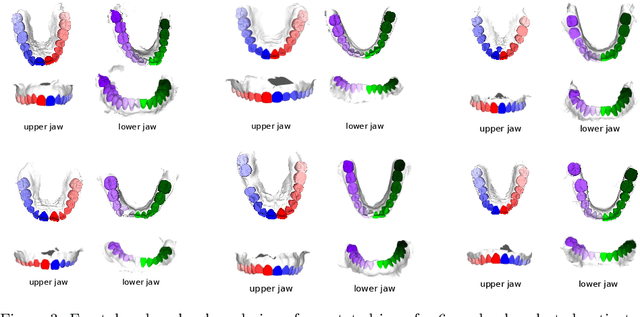
Teeth localization, segmentation, and labeling from intra-oral 3D scans are essential tasks in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, developing automated algorithms for teeth analysis presents significant challenges due to variations in dental anatomy, imaging protocols, and limited availability of publicly accessible data. To address these challenges, the 3DTeethSeg'22 challenge was organized in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) in 2022, with a call for algorithms tackling teeth localization, segmentation, and labeling from intraoral 3D scans. A dataset comprising a total of 1800 scans from 900 patients was prepared, and each tooth was individually annotated by a human-machine hybrid algorithm. A total of 6 algorithms were evaluated on this dataset. In this study, we present the evaluation results of the 3DTeethSeg'22 challenge. The 3DTeethSeg'22 challenge code can be accessed at: https://github.com/abenhamadou/3DTeethSeg22_challenge
Region-wise matching for image inpainting based on adaptive weighted low-rank decomposition
Mar 22, 2023Digital image inpainting is an interpolation problem, inferring the content in the missing (unknown) region to agree with the known region data such that the interpolated result fulfills some prior knowledge. Low-rank and nonlocal self-similarity are two important priors for image inpainting. Based on the nonlocal self-similarity assumption, an image is divided into overlapped square target patches (submatrices) and the similar patches of any target patch are reshaped as vectors and stacked into a patch matrix. Such a patch matrix usually enjoys a property of low rank or approximately low rank, and its missing entries are recoveried by low-rank matrix approximation (LRMA) algorithms. Traditionally, $n$ nearest neighbor similar patches are searched within a local window centered at a target patch. However, for an image with missing lines, the generated patch matrix is prone to having entirely-missing rows such that the downstream low-rank model fails to reconstruct it well. To address this problem, we propose a region-wise matching (RwM) algorithm by dividing the neighborhood of a target patch into multiple subregions and then search the most similar one within each subregion. A non-convex weighted low-rank decomposition (NC-WLRD) model for LRMA is also proposed to reconstruct all degraded patch matrices grouped by the proposed RwM algorithm. We solve the proposed NC-WLRD model by the alternating direction method of multipliers (ADMM) and analyze the convergence in detail. Numerous experiments on line inpainting (entire-row/column missing) demonstrate the superiority of our method over other competitive inpainting algorithms. Unlike other low-rank-based matrix completion methods and inpainting algorithms, the proposed model NC-WLRD is also effective for removing random-valued impulse noise and structural noise (stripes).
Dense Representative Tooth Landmark/axis Detection Network on 3D Model
Nov 09, 2021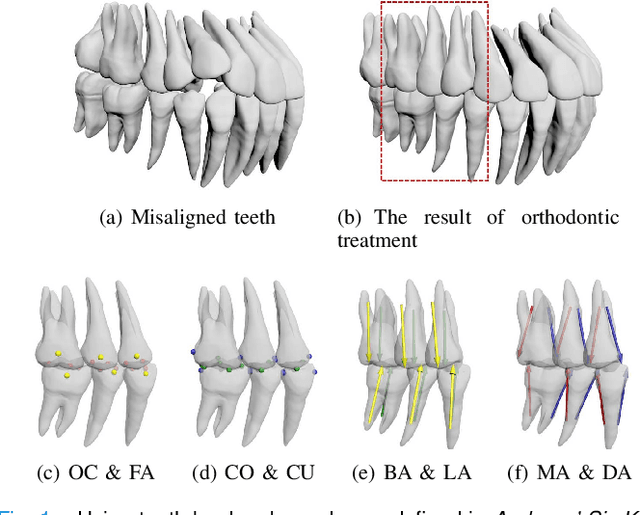
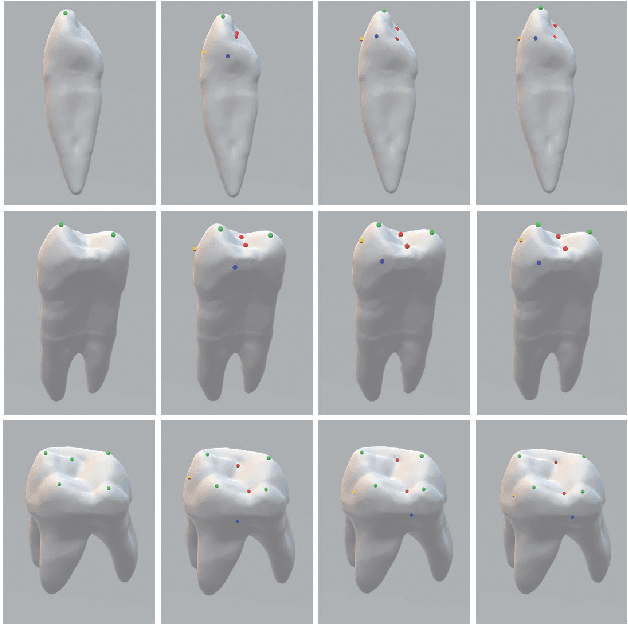
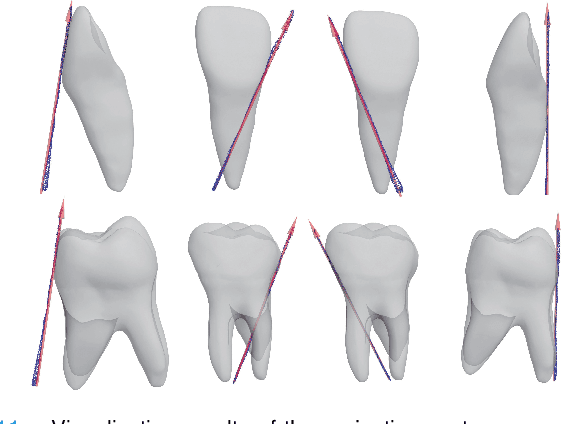
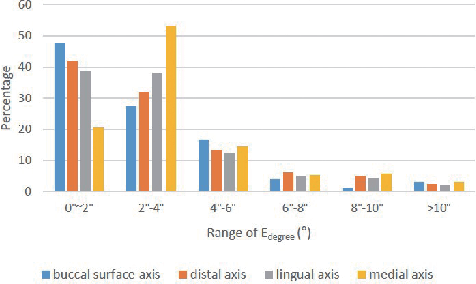
Artificial intelligence (AI) technology is increasingly used for digital orthodontics, but one of the challenges is to automatically and accurately detect tooth landmarks and axes. This is partly because of sophisticated geometric definitions of them, and partly due to large variations among individual tooth and across different types of tooth. As such, we propose a deep learning approach with a labeled dataset by professional dentists to the tooth landmark/axis detection on tooth model that are crucial for orthodontic treatments. Our method can extract not only tooth landmarks in the form of point (e.g. cusps), but also axes that measure the tooth angulation and inclination. The proposed network takes as input a 3D tooth model and predicts various types of the tooth landmarks and axes. Specifically, we encode the landmarks and axes as dense fields defined on the surface of the tooth model. This design choice and a set of added components make the proposed network more suitable for extracting sparse landmarks from a given 3D tooth model. Extensive evaluation of the proposed method was conducted on a set of dental models prepared by experienced dentists. Results show that our method can produce tooth landmarks with high accuracy. Our method was examined and justified via comparison with the state-of-the-art methods as well as the ablation studies.