 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DTeethSeg'22: 3D Teeth Scan Segmentation and Labeling Challenge
May 29, 2023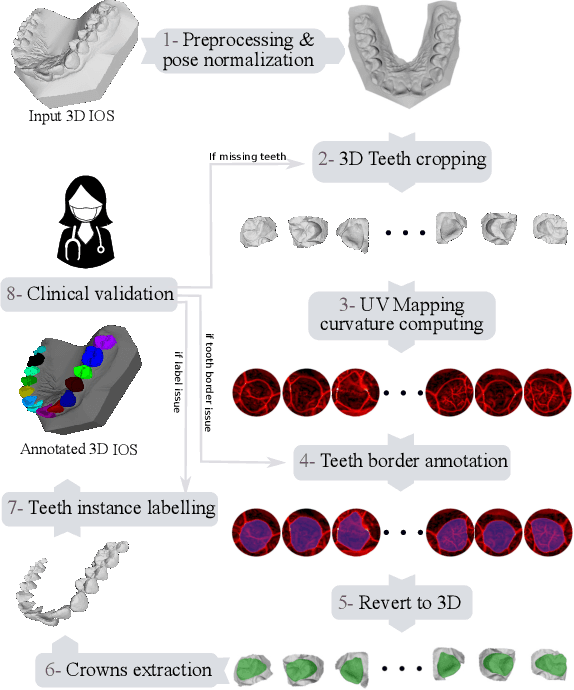
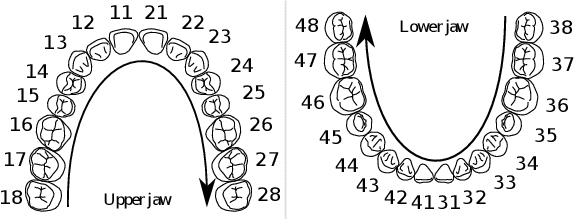
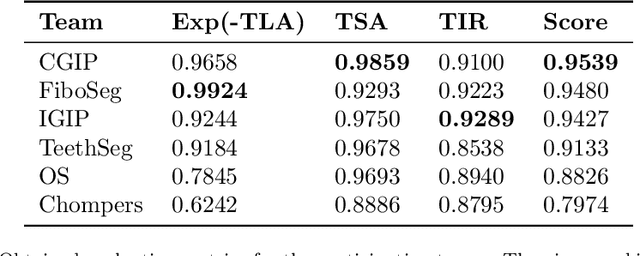
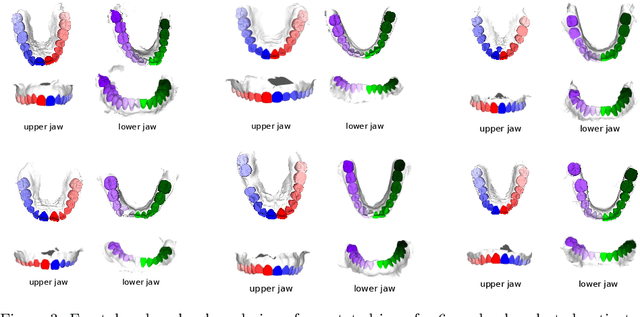
Teeth localization, segmentation, and labeling from intra-oral 3D scans are essential tasks in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, developing automated algorithms for teeth analysis presents significant challenges due to variations in dental anatomy, imaging protocols, and limited availability of publicly accessible data. To address these challenges, the 3DTeethSeg'22 challenge was organized in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) in 2022, with a call for algorithms tackling teeth localization, segmentation, and labeling from intraoral 3D scans. A dataset comprising a total of 1800 scans from 900 patients was prepared, and each tooth was individually annotated by a human-machine hybrid algorithm. A total of 6 algorithms were evaluated on this dataset. In this study, we present the evaluation results of the 3DTeethSeg'22 challenge. The 3DTeethSeg'22 challenge code can be accessed at: https://github.com/abenhamadou/3DTeethSeg22_challenge
Meta-Learning with Adaptive Weighted Loss for Imbalanced Cold-Start Recommendation
Feb 28, 2023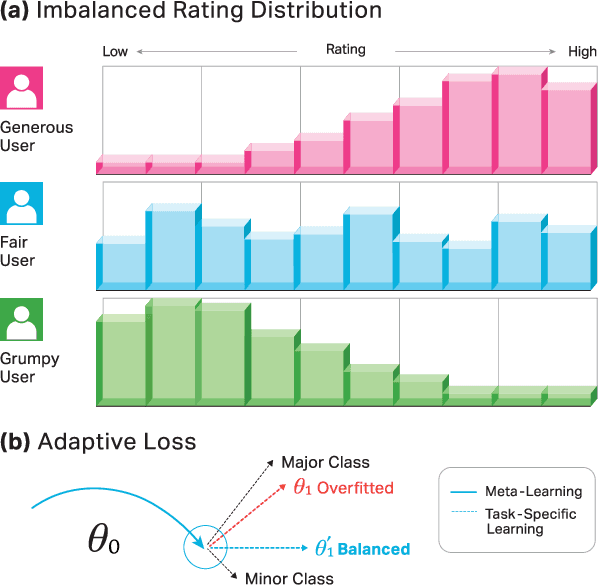
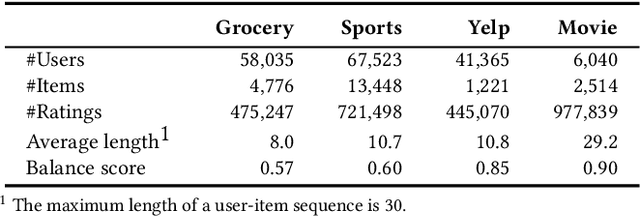
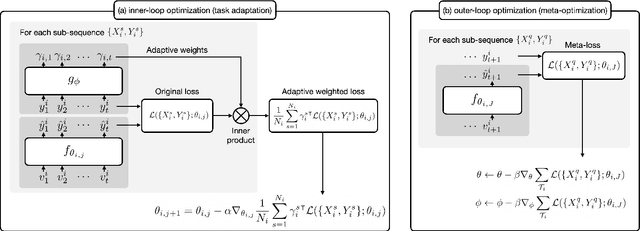
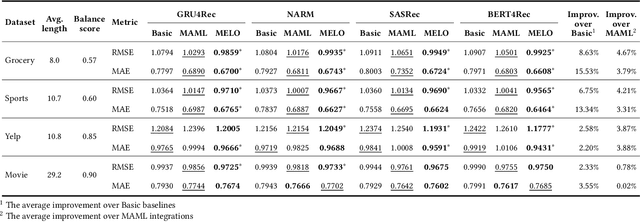
Sequential recommenders have made great strides in capturing a user's preferences. Nevertheless, the cold-start recommendation remains a fundamental challenge in which only a few user-item interactions are available for personalization. Gradient-based meta-learning approaches have recently emerged in the sequential recommendation field due to their fast adaptation and easy-to-integrate abilities. The meta-learning algorithms formulate the cold-start recommendation as a few-shot learning problem, where each user is represented as a task to be adapted. However, while meta-learning algorithms generally assume that task-wise samples are evenly distributed over classes or values, user-item interactions are not that way in real-world applications (e.g., watching favorite videos multiple times, leaving only good ratings and no bad ones). As a result, in the real-world, imbalanced user feedback that accounts for most task training data may dominate the user adaptation and prevent meta-learning algorithms from learning meaningful meta-knowledge for personalized recommendations. To alleviate this limitation, we propose a novel sequential recommendation framework based on gradient-based meta-learning that captures the imbalance of each user's rating distribution and accordingly computes adaptive loss for user-specific learning. It is the first work to tackle the impact of imbalanced ratings in cold-start sequential recommendation scenarios. We design adaptive weighted loss and improve the existing meta-learning algorithms for state-of-the-art sequential recommendation methods. Extensive experiments conducted on real-world datasets demonstrate the effectiveness of our framework.
Accurate Ground-Truth Depth Image Generation via Overfit Training of Point Cloud Registration using Local Frame Sets
Jul 14, 2022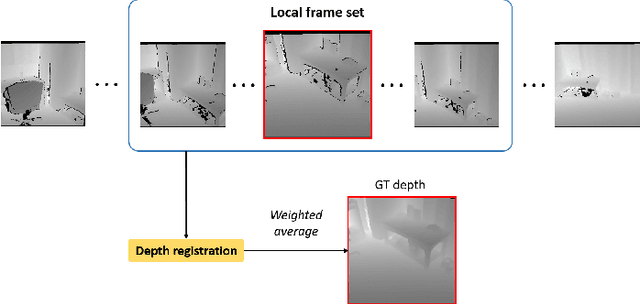
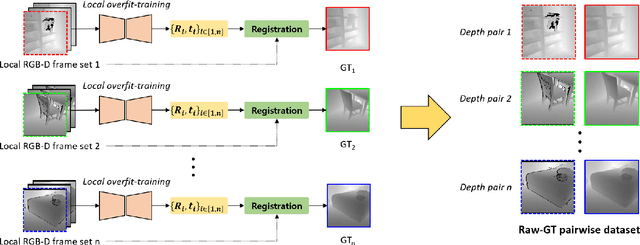


Accurate three-dimensional perception is a fundamental task in several computer vision applications. Recently, commercial RGB-depth (RGB-D) cameras have been widely adopted as single-view depth-sensing devices owing to their efficient depth-sensing abilities. However, the depth quality of most RGB-D sensors remains insufficient owing to the inherent noise from a single-view environment. Recently, several studies have focused on the single-view depth enhancement of RGB-D cameras. Recent research has proposed deep-learning-based approaches that typically train networks using high-quality supervised depth datasets, which indicates that the quality of the ground-truth (GT) depth dataset is a top-most important factor for accurate system; however, such high-quality GT datasets are difficult to obtain. In this study, we developed a novel method for high-quality GT depth generation based on an RGB-D stream dataset. First, we defined consecutive depth frames in a local spatial region as a local frame set. Then, the depth frames were aligned to a certain frame in the local frame set using an unsupervised point cloud registration scheme. The registration parameters were trained based on an overfit-training scheme, which was primarily used to construct a single GT depth image for each frame set. The final GT depth dataset was constructed using several local frame sets, and each local frame set was trained independently. The primary advantage of this study is that a high-quality GT depth dataset can be constructed under various scanning environments using only the RGB-D stream dataset. Moreover, our proposed method can be used as a new benchmark GT dataset for accurate performance evaluations. We evaluated our GT dataset on previously benchmarked GT depth datasets and demonstrated that our method is superior to state-of-the-art depth enhancement frameworks.