 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DTeethSeg'22: 3D Teeth Scan Segmentation and Labeling Challenge
May 29, 2023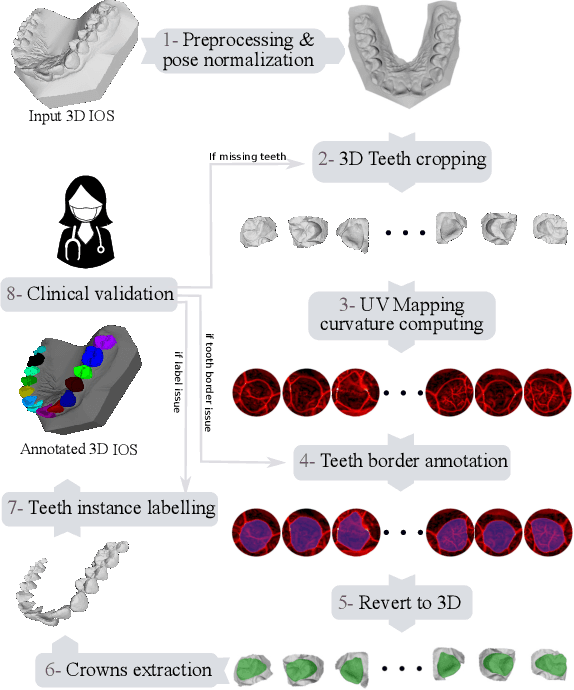
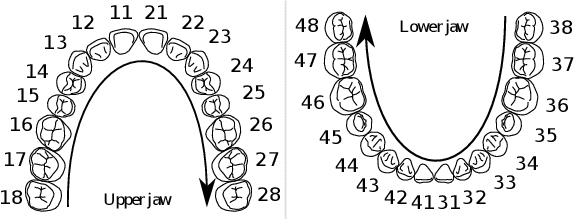
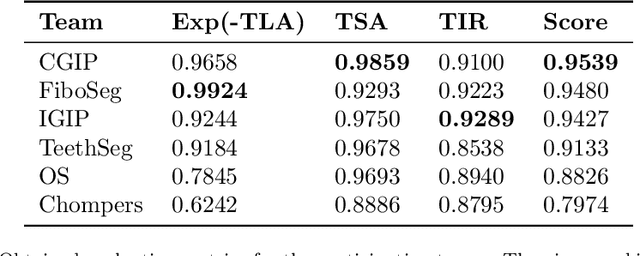
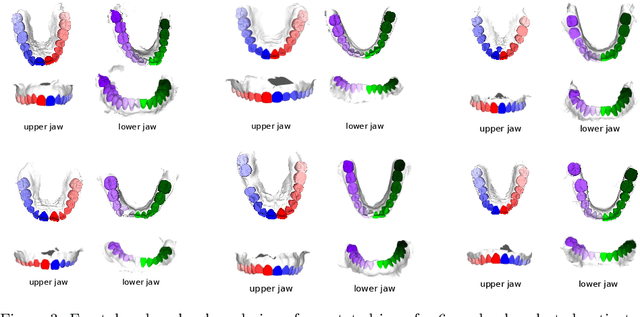
Teeth localization, segmentation, and labeling from intra-oral 3D scans are essential tasks in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, developing automated algorithms for teeth analysis presents significant challenges due to variations in dental anatomy, imaging protocols, and limited availability of publicly accessible data. To address these challenges, the 3DTeethSeg'22 challenge was organized in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) in 2022, with a call for algorithms tackling teeth localization, segmentation, and labeling from intraoral 3D scans. A dataset comprising a total of 1800 scans from 900 patients was prepared, and each tooth was individually annotated by a human-machine hybrid algorithm. A total of 6 algorithms were evaluated on this dataset. In this study, we present the evaluation results of the 3DTeethSeg'22 challenge. The 3DTeethSeg'22 challenge code can be accessed at: https://github.com/abenhamadou/3DTeethSeg22_challenge
Accurate Ground-Truth Depth Image Generation via Overfit Training of Point Cloud Registration using Local Frame Sets
Jul 14, 2022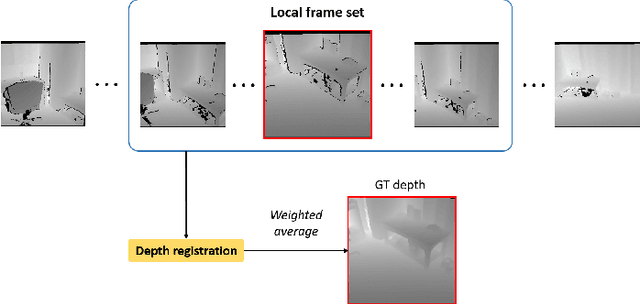
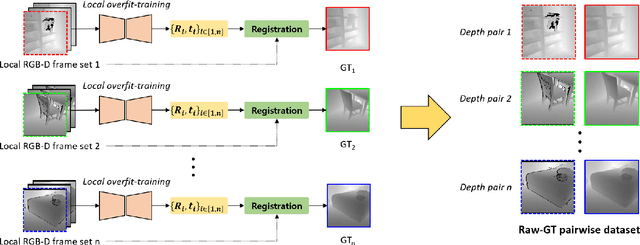


Accurate three-dimensional perception is a fundamental task in several computer vision applications. Recently, commercial RGB-depth (RGB-D) cameras have been widely adopted as single-view depth-sensing devices owing to their efficient depth-sensing abilities. However, the depth quality of most RGB-D sensors remains insufficient owing to the inherent noise from a single-view environment. Recently, several studies have focused on the single-view depth enhancement of RGB-D cameras. Recent research has proposed deep-learning-based approaches that typically train networks using high-quality supervised depth datasets, which indicates that the quality of the ground-truth (GT) depth dataset is a top-most important factor for accurate system; however, such high-quality GT datasets are difficult to obtain. In this study, we developed a novel method for high-quality GT depth generation based on an RGB-D stream dataset. First, we defined consecutive depth frames in a local spatial region as a local frame set. Then, the depth frames were aligned to a certain frame in the local frame set using an unsupervised point cloud registration scheme. The registration parameters were trained based on an overfit-training scheme, which was primarily used to construct a single GT depth image for each frame set. The final GT depth dataset was constructed using several local frame sets, and each local frame set was trained independently. The primary advantage of this study is that a high-quality GT depth dataset can be constructed under various scanning environments using only the RGB-D stream dataset. Moreover, our proposed method can be used as a new benchmark GT dataset for accurate performance evaluations. We evaluated our GT dataset on previously benchmarked GT depth datasets and demonstrated that our method is superior to state-of-the-art depth enhancement frameworks.
Voxel-wise Adversarial Semi-supervised Learning for Medical Image Segmentation
May 14, 2022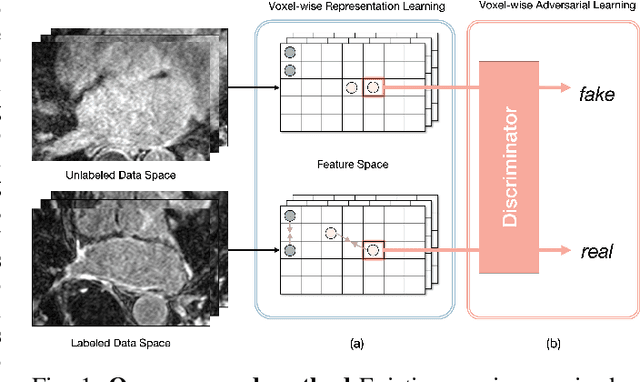
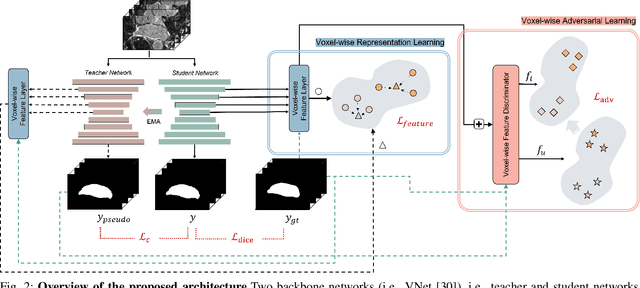
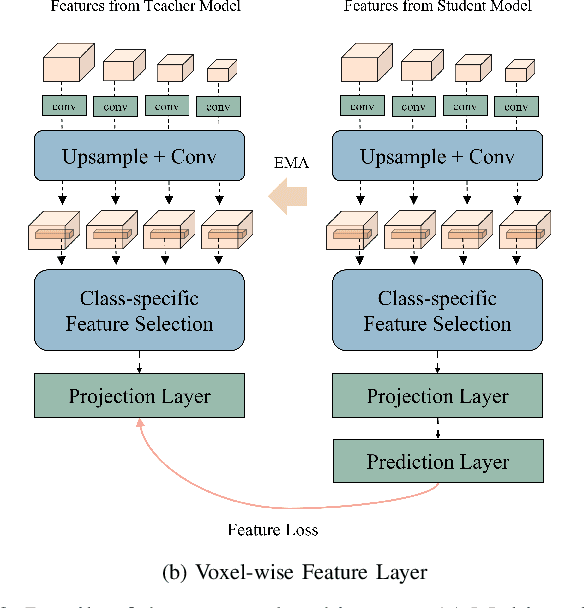
Semi-supervised learning for medical image segmentation is an important area of research for alleviating the huge cost associated with the construction of reliable large-scale annotations in the medical domain. Recent semi-supervised approaches have demonstrated promising results by employing consistency regularization, pseudo-labeling techniques, and adversarial learning. These methods primarily attempt to learn the distribution of labeled and unlabeled data by enforcing consistency in the predictions or embedding context. However, previous approaches have focused only on local discrepancy minimization or context relations across single classes. In this paper, we introduce a novel adversarial learning-based semi-supervised segmentation method that effectively embeds both local and global features from multiple hidden layers and learns context relations between multiple classes. Our voxel-wise adversarial learning method utilizes a voxel-wise feature discriminator, which considers multilayer voxel-wise features (involving both local and global features) as an input by embedding class-specific voxel-wise feature distribution. Furthermore, we improve our previous representation learning method by overcoming information loss and learning stability problems, which enables rich representations of labeled data. Our method outperforms current best-performing state-of-the-art semi-supervised learning approaches on the image segmentation of the left atrium (single class) and multiorgan datasets (multiclass). Moreover, our visual interpretation of the feature space demonstrates that our proposed method enables a well-distributed and separated feature space from both labeled and unlabeled data, which improves the overall prediction results.
Cardiac Segmentation on CT Images through Shape-Aware Contour Attentions
May 27, 2021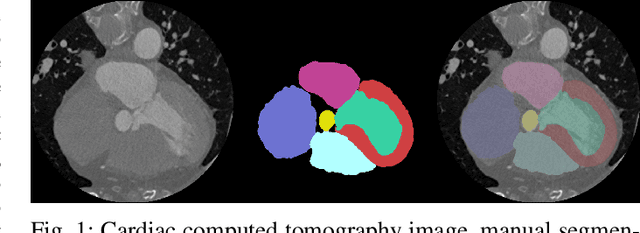
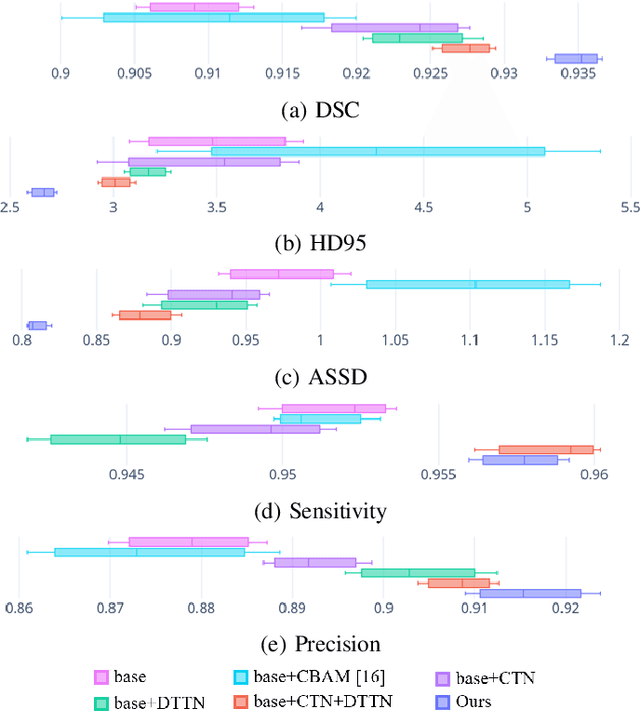
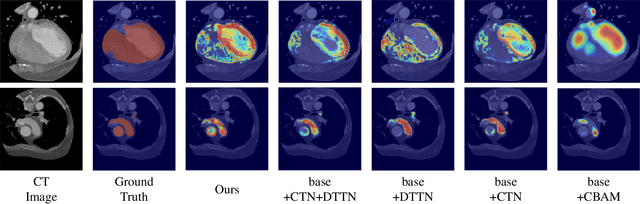
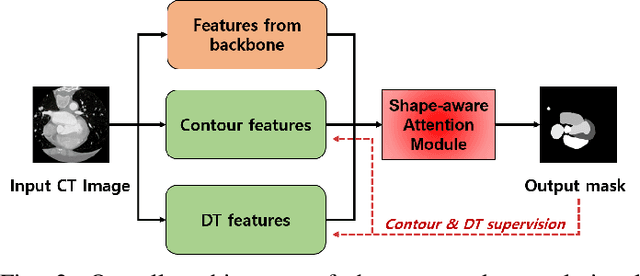
Cardiac segmentation of atriums, ventricles, and myocardium in computed tomography (CT) images is an important first-line task for presymptomatic cardiovascular disease diagnosis. In several recent studies, deep learning models have shown significant breakthroughs in medical image segmentation tasks. Unlike other organs such as the lungs and liver, the cardiac organ consists of multiple substructures, i.e., ventricles, atriums, aortas, arteries, veins, and myocardium. These cardiac substructures are proximate to each other and have indiscernible boundaries (i.e., homogeneous intensity values), making it difficult for the segmentation network focus on the boundaries between the substructures. In this paper, to improve the segmentation accuracy between proximate organs, we introduce a novel model to exploit shape and boundary-aware features. We primarily propose a shape-aware attention module, that exploits distance regression, which can guide the model to focus on the edges between substructures so that it can outperform the conventional contour-based attention method. In the experiments, we used the Multi-Modality Whole Heart Segmentation dataset that has 20 CT cardiac images for training and validation, and 40 CT cardiac images for testing. The experimental results show that the proposed network produces more accurate results than state-of-the-art networks by improving the Dice similarity coefficient score by 4.97%. Our proposed shape-aware contour attention mechanism demonstrates that distance transformation and boundary features improve the actual attention map to strengthen the responses in the boundary area. Moreover, our proposed method significantly reduces the false-positive responses of the final output, resulting in accurate segmentation.
Voxel-level Siamese Representation Learning for Abdominal Multi-Organ Segmentation
May 17, 2021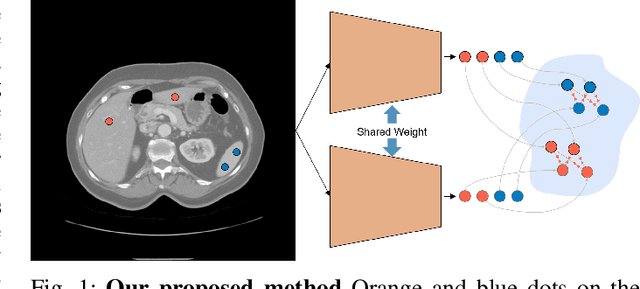
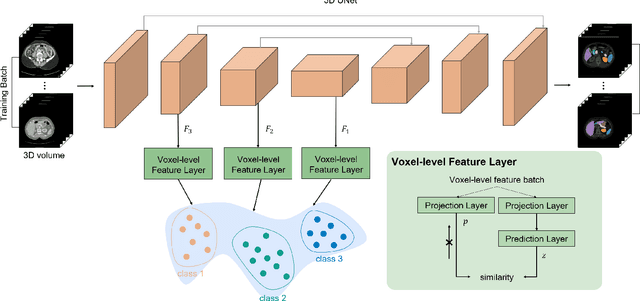
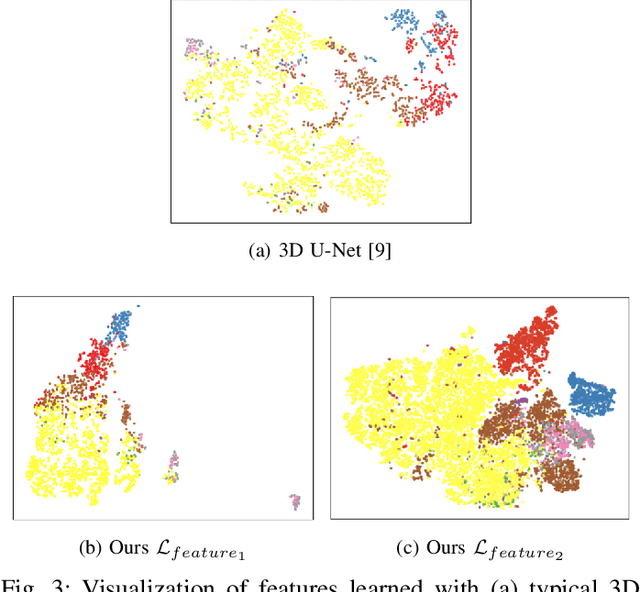
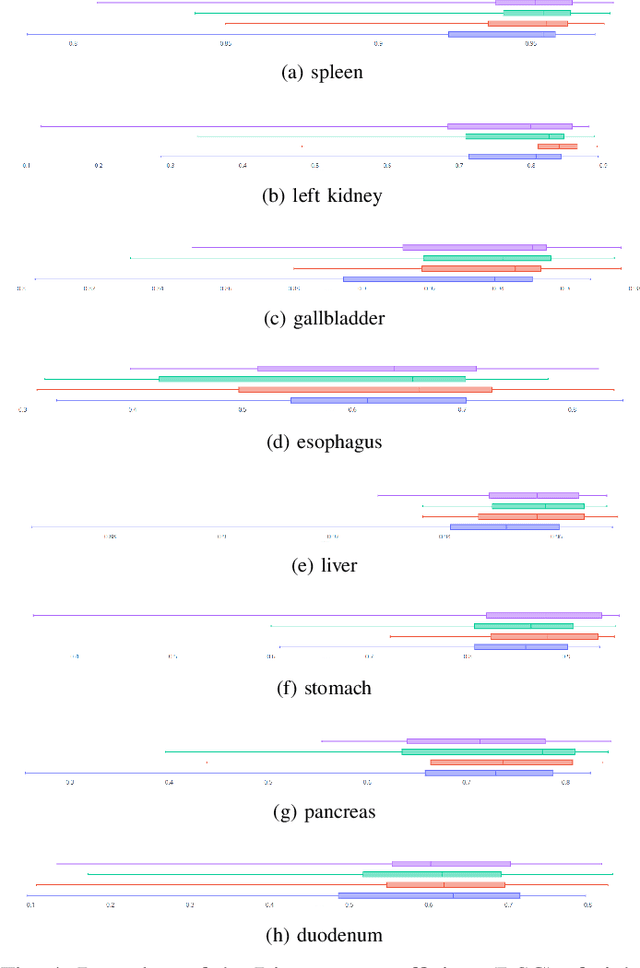
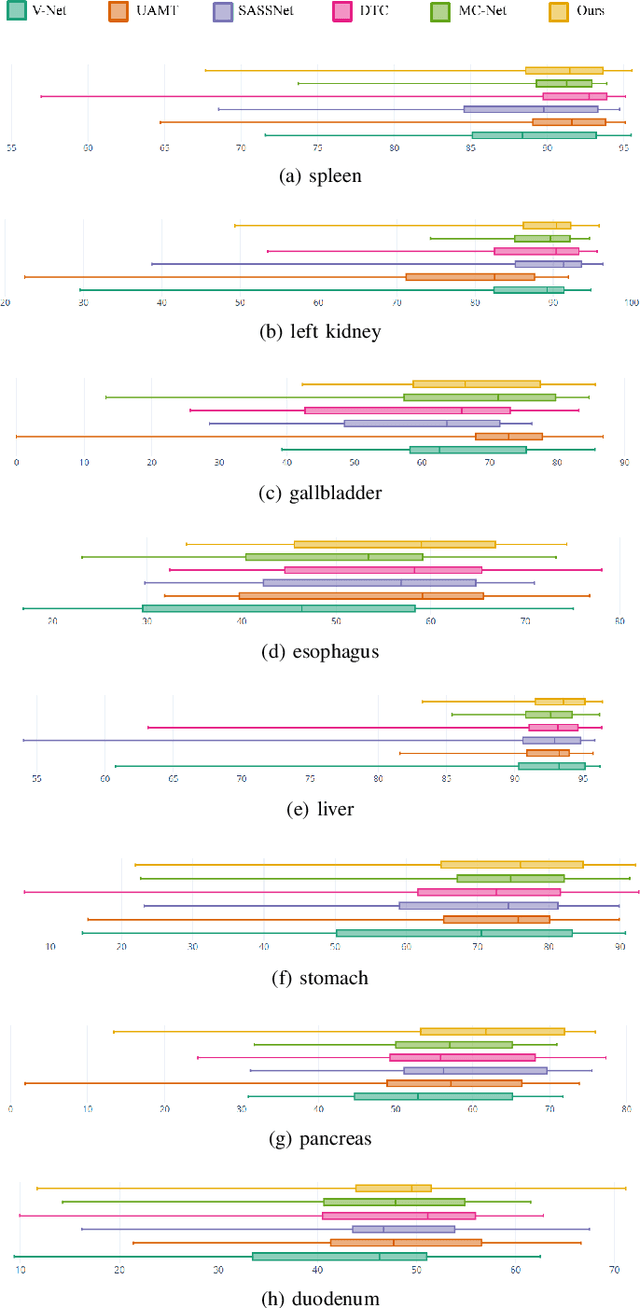
Recent works in medical image segmentation have actively explored various deep learning architectures or objective functions to encode high-level features from volumetric data owing to limited image annotations. However, most existing approaches tend to ignore cross-volume global context and define context relations in the decision space. In this work, we propose a novel voxel-level Siamese representation learning method for abdominal multi-organ segmentation to improve representation space. The proposed method enforces voxel-wise feature relations in the representation space for leveraging limited datasets more comprehensively to achieve better performance. Inspired by recent progress in contrastive learning, we suppressed voxel-wise relations from the same class to be projected to the same point without using negative samples. Moreover, we introduce a multi-resolution context aggregation method that aggregates features from multiple hidden layers, which encodes both the global and local contexts for segmentation. Our experiments on the multi-organ dataset outperformed the existing approaches by 2% in Dice score coefficient. The qualitative visualizations of the representation spaces demonstrate that the improvements were gained primarily by a disentangled feature space.
Tooth Instance Segmentation from Cone-Beam CT Images through Point-based Detection and Gaussian Disentanglement
Feb 02, 2021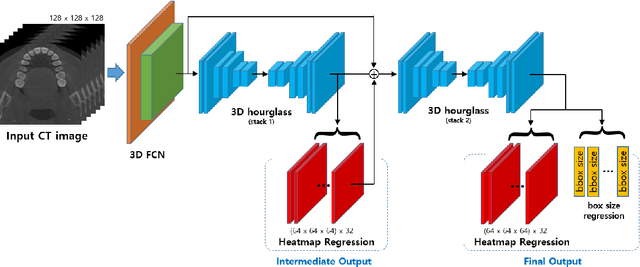
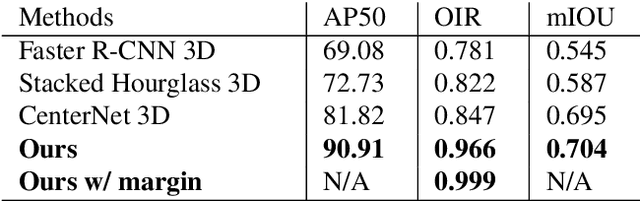
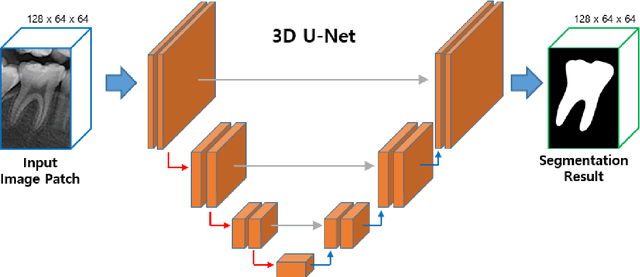
Individual tooth segmentation and identification from cone-beam computed tomography images are preoperative prerequisites for orthodontic treatments. Instance segmentation methods using convolutional neural networks have demonstrated ground-breaking results on individual tooth segmentation tasks, and are used in various medical imaging applications. While point-based detection networks achieve superior results on dental images, it is still a challenging task to distinguish adjacent teeth because of their similar topologies and proximate nature. In this study, we propose a point-based tooth localization network that effectively disentangles each individual tooth based on a Gaussian disentanglement objective function. The proposed network first performs heatmap regression accompanied by box regression for all the anatomical teeth. A novel Gaussian disentanglement penalty is employed by minimizing the sum of the pixel-wise multiplication of the heatmaps for all adjacent teeth pairs. Subsequently, individual tooth segmentation is performed by converting a pixel-wise labeling task to a distance map regression task to minimize false positives in adjacent regions of the teeth. Experimental results demonstrate that the proposed algorithm outperforms state-of-the-art approaches by increasing the average precision of detection by 9.1%, which results in a high performance in terms of individual tooth segmentation. The primary significance of the proposed method is two-fold: 1) the introduction of a point-based tooth detection framework that does not require additional classification and 2) the design of a novel loss function that effectively separates Gaussian distributions based on heatmap responses in the point-based detection framework.
Robust Kernel-based Feature Representation for 3D Point Cloud Analysis via Circular Graph Convolutional Network
Jan 14, 2021



Feature descriptors of point clouds are used in several applications, such as registration and part segmentation of 3D point clouds. Learning discriminative representations of local geometric features is unquestionably the most important task for accurate point cloud analyses. However, it is challenging to develop rotation or scale-invariant descriptors. Most previous studies have either ignored rotations or empirically studied optimal scale parameters, which hinders the applicability of the methods for real-world datasets. In this paper, we present a new local feature description method that is robust to rotation, density, and scale variations. Moreover, to improve representations of the local descriptors, we propose a global aggregation method. First, we place kernels aligned around each point in the normal direction. To avoid the sign problem of the normal vector, we use a symmetric kernel point distribution in the tangential plane. From each kernel point, we first projected the points from the spatial space to the feature space, which is robust to multiple scales and rotation, based on angles and distances. Subsequently, we perform graph convolutions by considering local kernel point structures and long-range global context, obtained by a global aggregation method. We experimented with our proposed descriptors on benchmark datasets (i.e., ModelNet40 and ShapeNetPart) to evaluate the performance of registration, classification, and part segmentation on 3D point clouds. Our method showed superior performances when compared to the state-of-the-art methods by reducing 70$\%$ of the rotation and translation errors in the registration task. Our method also showed comparable performance in the classification and part-segmentation tasks with simple and low-dimensional architectures.
Individual Tooth Detection and Identification from Dental Panoramic X-Ray Images via Point-wise Localization and Distance Regularization
Apr 12, 2020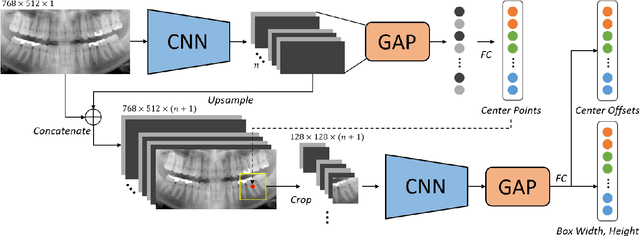
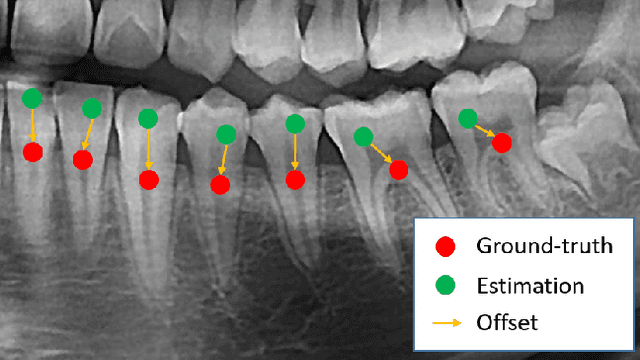
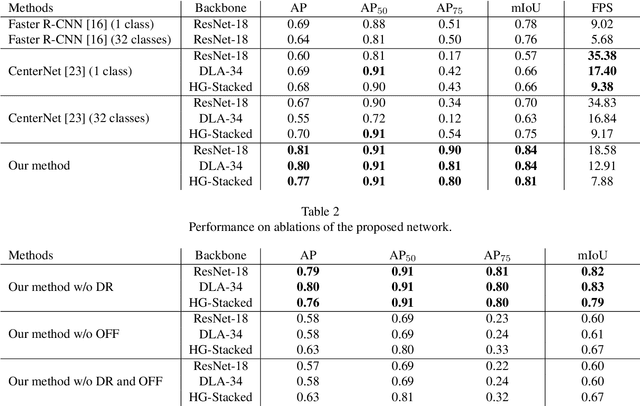
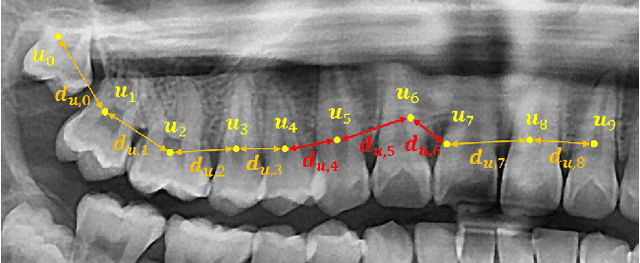
Dental panoramic X-ray imaging is a popular diagnostic method owing to its very small dose of radiation. For an automated computer-aided diagnosis system in dental clinics, automatic detection and identification of individual teeth from panoramic X-ray images are critical prerequisites. In this study, we propose a point-wise tooth localization neural network by introducing a spatial distance regularization loss. The proposed network initially performs center point regression for all the anatomical teeth (i.e., 32 points), which automatically identifies each tooth. A novel distance regularization penalty is employed on the 32 points by considering $L_2$ regularization loss of Laplacian on spatial distances. Subsequently, teeth boxes are individually localized using a cascaded neural network on a patch basis. A multitask offset training is employed on the final output to improve the localization accuracy. Our method successfully localizes not only the existing teeth but also missing teeth; consequently, highly accurate detection and identification are achieved. The experimental results demonstrate that the proposed algorithm outperforms state-of-the-art approaches by increasing the average precision of teeth detection by 15.71% compared to the best performing method. The accuracy of identification achieved a precision of 0.997 and recall value of 0.972. Moreover, the proposed network does not require any additional identification algorithm owing to the preceding regression of the fixed 32 points regardless of the existence of the teeth.
Liver Segmentation in Abdominal CT Images via Auto-Context Neural Network and Self-Supervised Contour Attention
Feb 14, 2020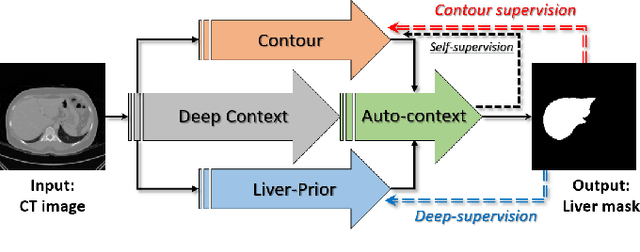
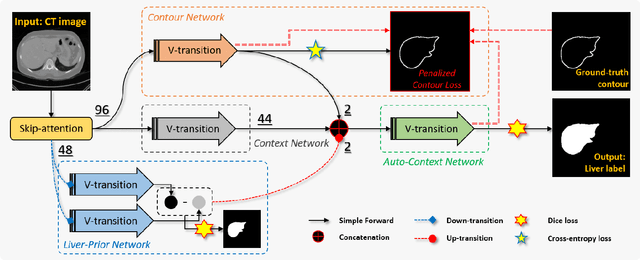
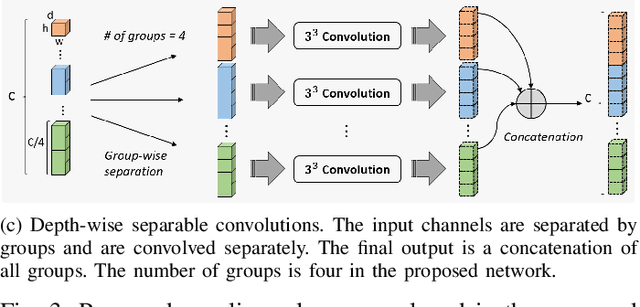
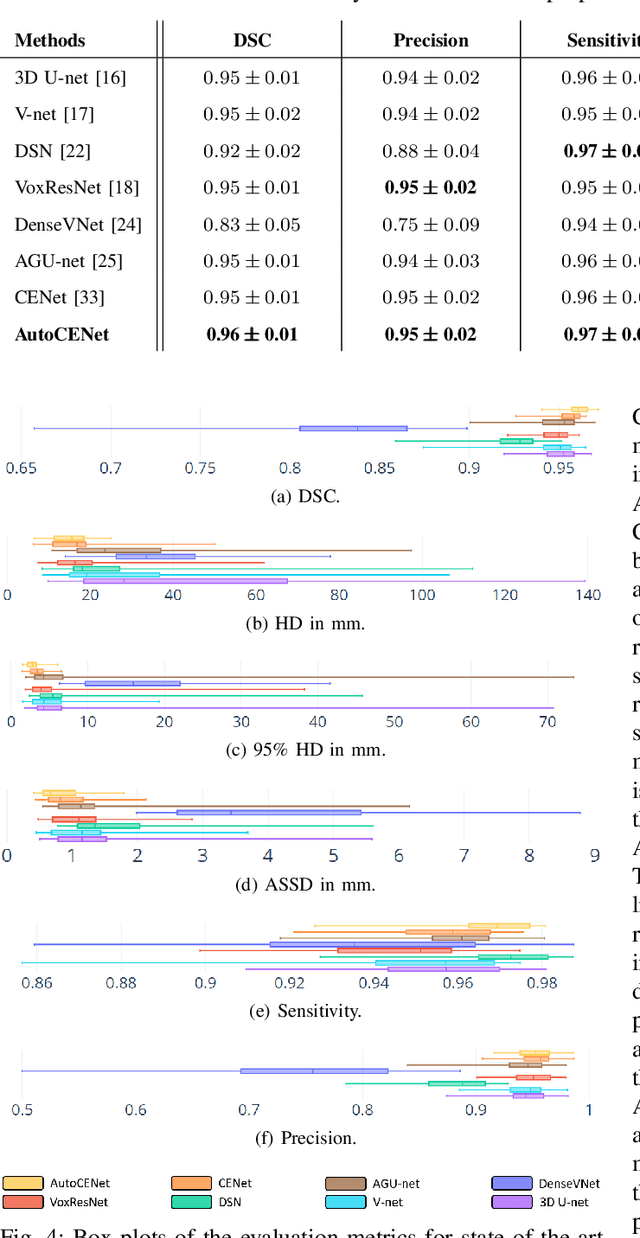
Accurate image segmentation of the liver is a challenging problem owing to its large shape variability and unclear boundaries. Although the applications of fully convolutional neural networks (CNNs) have shown groundbreaking results, limited studies have focused on the performance of generalization. In this study, we introduce a CNN for liver segmentation on abdominal computed tomography (CT) images that shows high generalization performance and accuracy. To improve the generalization performance, we initially propose an auto-context algorithm in a single CNN. The proposed auto-context neural network exploits an effective high-level residual estimation to obtain the shape prior. Identical dual paths are effectively trained to represent mutual complementary features for an accurate posterior analysis of a liver. Further, we extend our network by employing a self-supervised contour scheme. We trained sparse contour features by penalizing the ground-truth contour to focus more contour attentions on the failures. The experimental results show that the proposed network results in better accuracy when compared to the state-of-the-art networks by reducing 10.31% of the Hausdorff distance. We used 180 abdominal CT images for training and validation. Two-fold cross-validation is presented for a comparison with the state-of-the-art neural networks. Novel multiple N-fold cross-validations are conducted to verify the performance of generalization. The proposed network showed the best generalization performance among the networks. Additionally, we present a series of ablation experiments that comprehensively support the importance of the underlying concepts.
Pose-Aware Instance Segmentation Framework from Cone Beam CT Images for Tooth Segmentation
Feb 06, 2020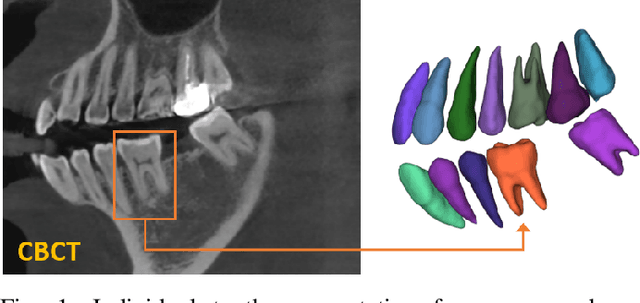
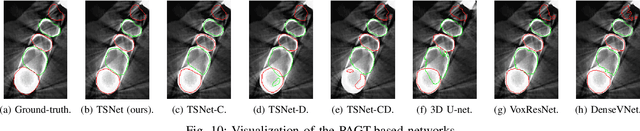
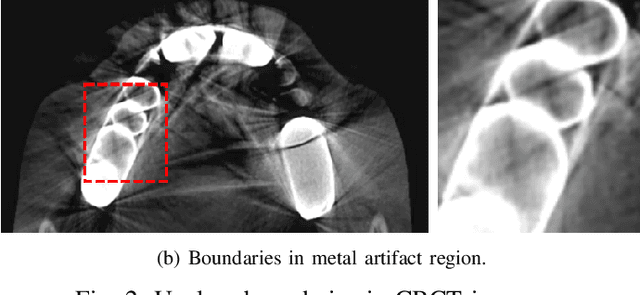
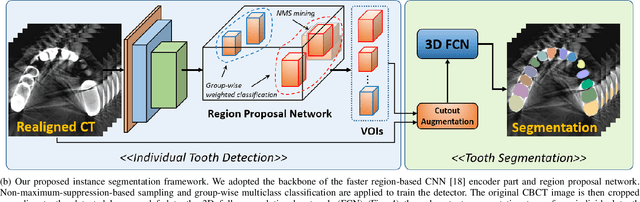
Individual tooth segmentation from cone beam computed tomography (CBCT) images is an essential prerequisite for an anatomical understanding of orthodontic structures in several applications, such as tooth reformation planning and implant guide simulations. However, the presence of severe metal artifacts in CBCT images hinders the accurate segmentation of each individual tooth. In this study, we propose a neural network for pixel-wise labeling to exploit an instance segmentation framework that is robust to metal artifacts. Our method comprises of three steps: 1) image cropping and realignment by pose regressions, 2) metal-robust individual tooth detection, and 3) segmentation. We first extract the alignment information of the patient by pose regression neural networks to attain a volume-of-interest (VOI) region and realign the input image, which reduces the inter-overlapping area between tooth bounding boxes. Then, individual tooth regions are localized within a VOI realigned image using a convolutional detector. We improved the accuracy of the detector by employing non-maximum suppression and multiclass classification metrics in the region proposal network. Finally, we apply a convolutional neural network (CNN) to perform individual tooth segmentation by converting the pixel-wise labeling task to a distance regression task. Metal-intensive image augmentation is also employed for a robust segmentation of metal artifacts. The result shows that our proposed method outperforms other state-of-the-art methods, especially for teeth with metal artifacts. The primary significance of the proposed method is two-fold: 1) an introduction of pose-aware VOI realignment followed by a robust tooth detection and 2) a metal-robust CNN framework for accurate tooth segmentation.