 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxel-level Siamese Representation Learning for Abdominal Multi-Organ Segmentation
Paper and Code
May 17, 2021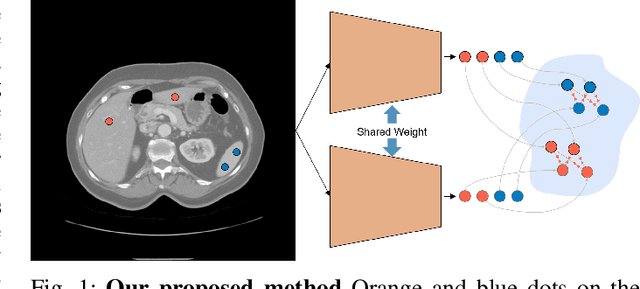
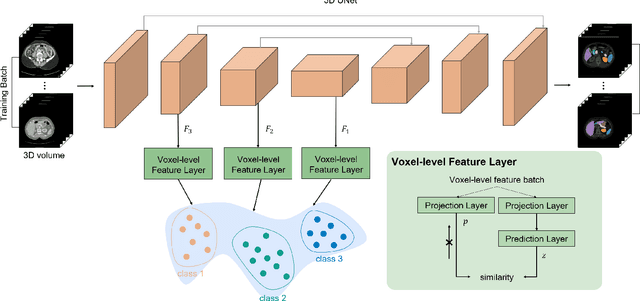
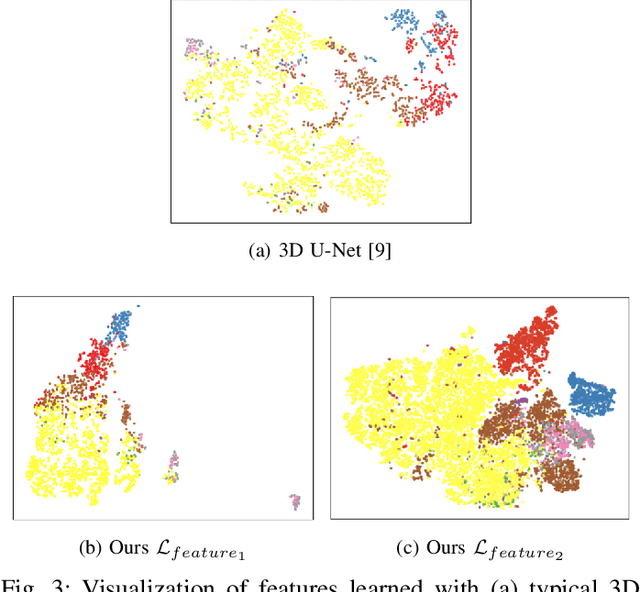
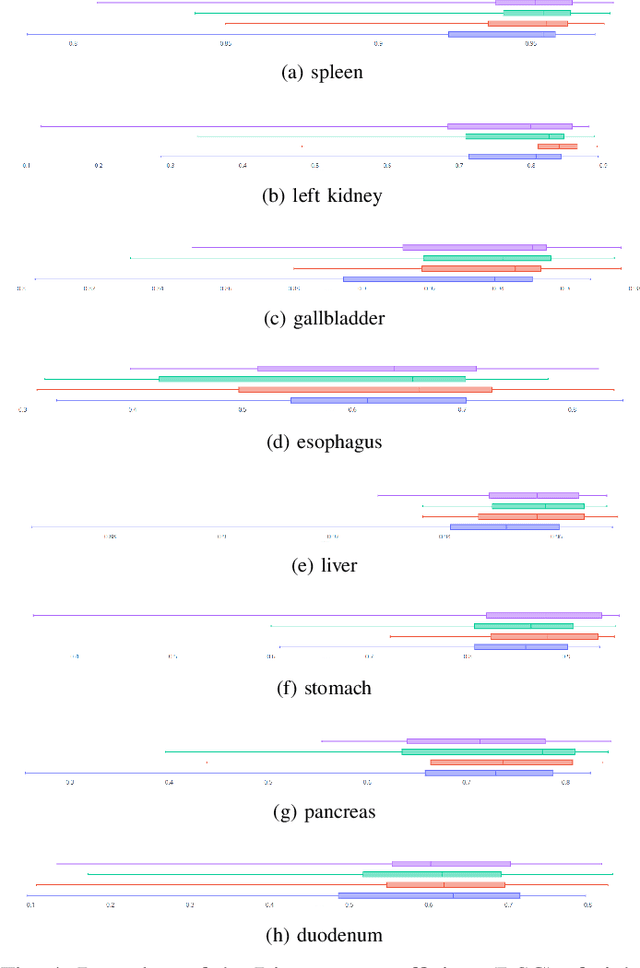
Recent works in medical image segmentation have actively explored various deep learning architectures or objective functions to encode high-level features from volumetric data owing to limited image annotations. However, most existing approaches tend to ignore cross-volume global context and define context relations in the decision space. In this work, we propose a novel voxel-level Siamese representation learning method for abdominal multi-organ segmentation to improve representation space. The proposed method enforces voxel-wise feature relations in the representation space for leveraging limited datasets more comprehensively to achieve better performance. Inspired by recent progress in contrastive learning, we suppressed voxel-wise relations from the same class to be projected to the same point without using negative samples. Moreover, we introduce a multi-resolution context aggregation method that aggregates features from multiple hidden layers, which encodes both the global and local contexts for segmentation. Our experiments on the multi-organ dataset outperformed the existing approaches by 2% in Dice score coefficient. The qualitative visualizations of the representation spaces demonstrate that the improvements were gained primarily by a disentangled feature space.