 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive-Sum Fairness: Leveraging Demographic Attributes to Achieve Fair AI Outcomes Without Sacrificing Group Gains
Sep 30, 2024Fairness in medical AI is increasingly recognized as a crucial aspect of healthcare delivery. While most of the prior work done on fairness emphasizes the importance of equal performance, we argue that decreases in fairness can be either harmful or non-harmful, depending on the type of change and how sensitive attributes are used. To this end, we introduce the notion of positive-sum fairness, which states that an increase in performance that results in a larger group disparity is acceptable as long as it does not come at the cost of individual subgroup performance. This allows sensitive attributes correlated with the disease to be used to increase performance without compromising on fairness. We illustrate this idea by comparing four CNN models that make different use of the race attribute in the training phase. The results show that removing all demographic encodings from the images helps close the gap in performance between the different subgroups, whereas leveraging the race attribute as a model's input increases the overall performance while widening the disparities between subgroups. These larger gaps are then put in perspective of the collective benefit through our notion of positive-sum fairness to distinguish harmful from non harmful disparities.
Technical Report for CVPR 2022 LOVEU AQTC Challenge
Jun 29, 2022

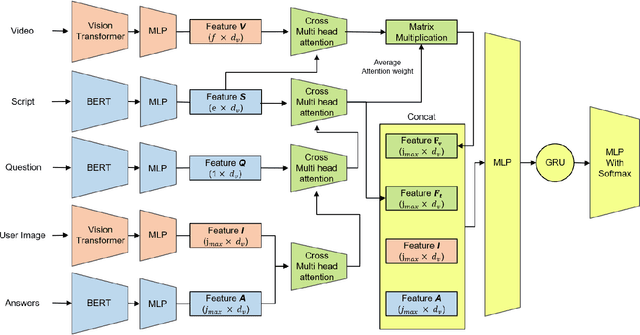
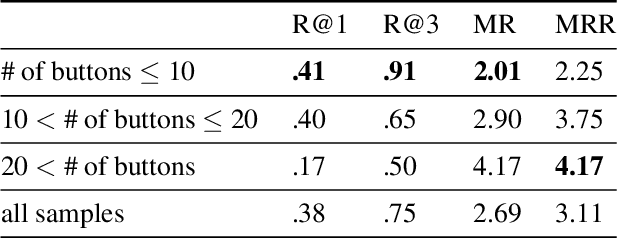
This technical report presents the 2nd winning model for AQTC, a task newly introduced in CVPR 2022 LOng-form VidEo Understanding (LOVEU) challenges. This challenge faces difficulties with multi-step answers, multi-modal, and diverse and changing button representations in video. We address this problem by proposing a new context ground module attention mechanism for more effective feature mapping. In addition, we also perform the analysis over the number of buttons and ablation study of different step networks and video features. As a result, we achieved the overall 2nd place in LOVEU competition track 3, specifically the 1st place in two out of four evaluation metrics. Our code is available at https://github.com/jaykim9870/ CVPR-22_LOVEU_unipyler.
Cardiac Segmentation on CT Images through Shape-Aware Contour Attentions
May 27, 2021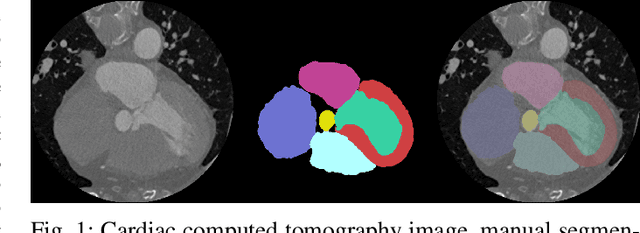
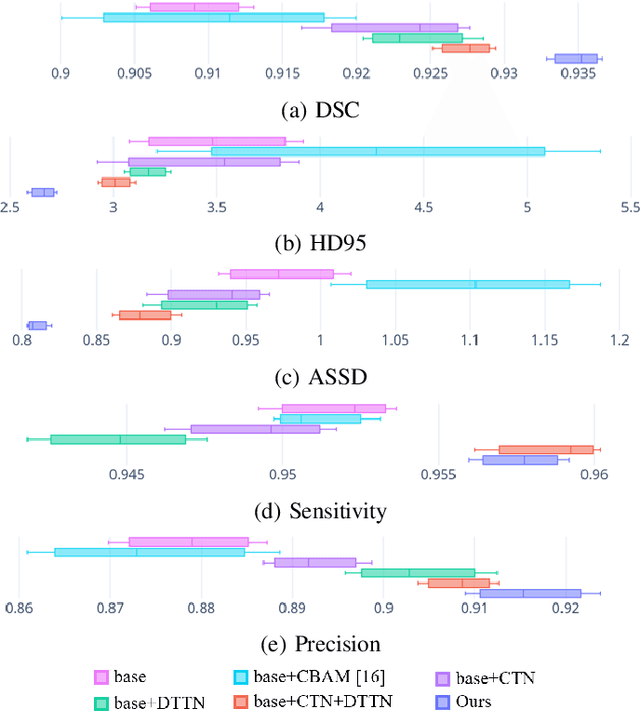
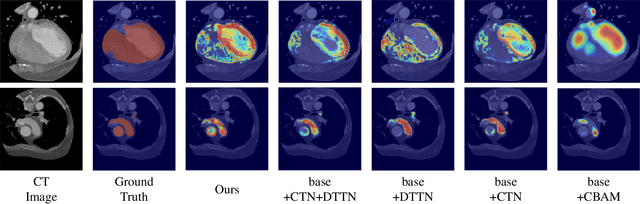
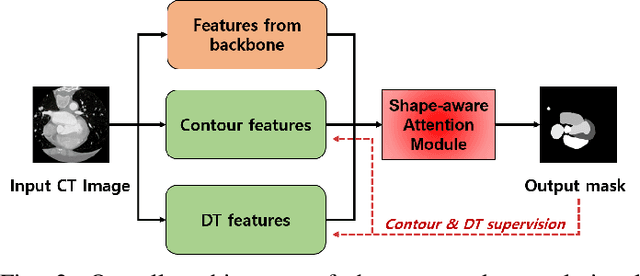
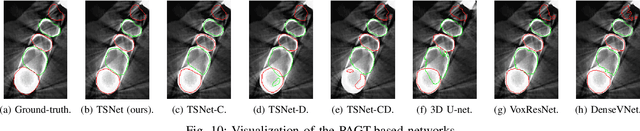
Cardiac segmentation of atriums, ventricles, and myocardium in computed tomography (CT) images is an important first-line task for presymptomatic cardiovascular disease diagnosis. In several recent studies, deep learning models have shown significant breakthroughs in medical image segmentation tasks. Unlike other organs such as the lungs and liver, the cardiac organ consists of multiple substructures, i.e., ventricles, atriums, aortas, arteries, veins, and myocardium. These cardiac substructures are proximate to each other and have indiscernible boundaries (i.e., homogeneous intensity values), making it difficult for the segmentation network focus on the boundaries between the substructures. In this paper, to improve the segmentation accuracy between proximate organs, we introduce a novel model to exploit shape and boundary-aware features. We primarily propose a shape-aware attention module, that exploits distance regression, which can guide the model to focus on the edges between substructures so that it can outperform the conventional contour-based attention method. In the experiments, we used the Multi-Modality Whole Heart Segmentation dataset that has 20 CT cardiac images for training and validation, and 40 CT cardiac images for testing. The experimental results show that the proposed network produces more accurate results than state-of-the-art networks by improving the Dice similarity coefficient score by 4.97%. Our proposed shape-aware contour attention mechanism demonstrates that distance transformation and boundary features improve the actual attention map to strengthen the responses in the boundary area. Moreover, our proposed method significantly reduces the false-positive responses of the final output, resulting in accurate segmentation.
Individual Tooth Detection and Identification from Dental Panoramic X-Ray Images via Point-wise Localization and Distance Regularization
Apr 12, 2020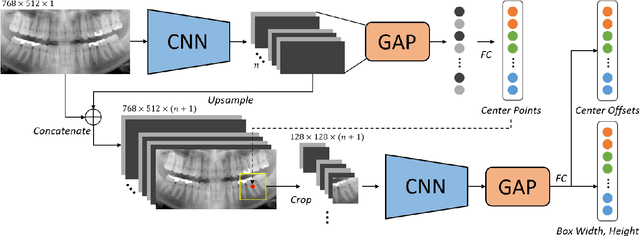
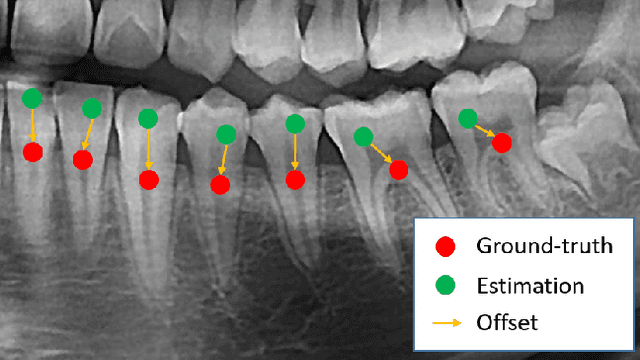
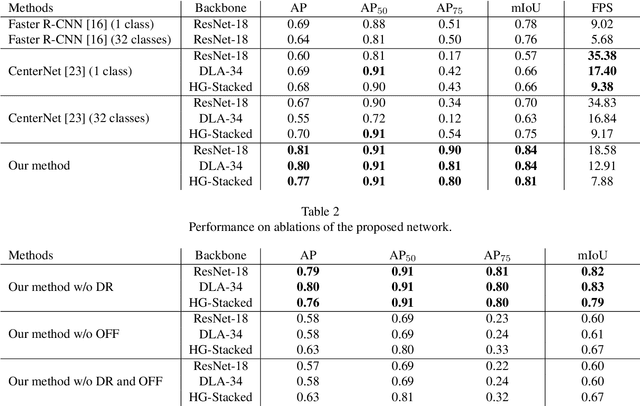
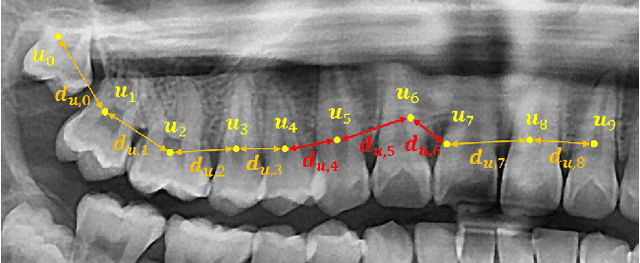
Dental panoramic X-ray imaging is a popular diagnostic method owing to its very small dose of radiation. For an automated computer-aided diagnosis system in dental clinics, automatic detection and identification of individual teeth from panoramic X-ray images are critical prerequisites. In this study, we propose a point-wise tooth localization neural network by introducing a spatial distance regularization loss. The proposed network initially performs center point regression for all the anatomical teeth (i.e., 32 points), which automatically identifies each tooth. A novel distance regularization penalty is employed on the 32 points by considering $L_2$ regularization loss of Laplacian on spatial distances. Subsequently, teeth boxes are individually localized using a cascaded neural network on a patch basis. A multitask offset training is employed on the final output to improve the localization accuracy. Our method successfully localizes not only the existing teeth but also missing teeth; consequently, highly accurate detection and identification are achieved. The experimental results demonstrate that the proposed algorithm outperforms state-of-the-art approaches by increasing the average precision of teeth detection by 15.71% compared to the best performing method. The accuracy of identification achieved a precision of 0.997 and recall value of 0.972. Moreover, the proposed network does not require any additional identification algorithm owing to the preceding regression of the fixed 32 points regardless of the existence of the teeth.
Pose-Aware Instance Segmentation Framework from Cone Beam CT Images for Tooth Segmentation
Feb 06, 2020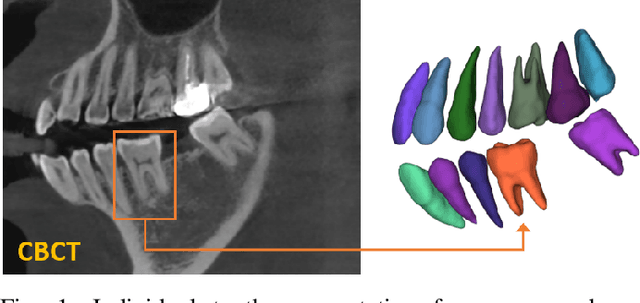
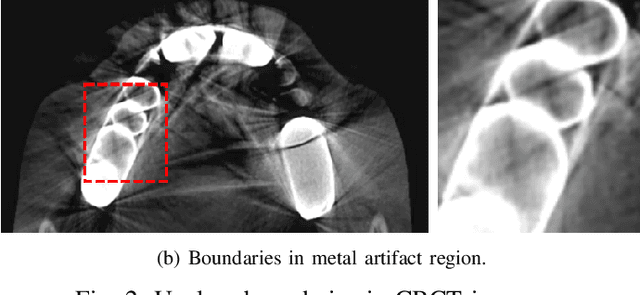
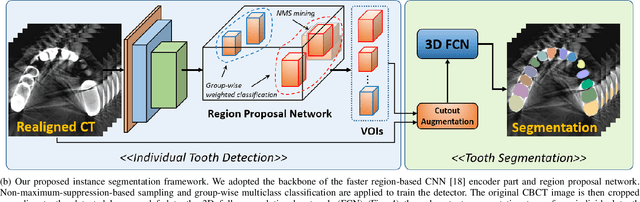
Individual tooth segmentation from cone beam computed tomography (CBCT) images is an essential prerequisite for an anatomical understanding of orthodontic structures in several applications, such as tooth reformation planning and implant guide simulations. However, the presence of severe metal artifacts in CBCT images hinders the accurate segmentation of each individual tooth. In this study, we propose a neural network for pixel-wise labeling to exploit an instance segmentation framework that is robust to metal artifacts. Our method comprises of three steps: 1) image cropping and realignment by pose regressions, 2) metal-robust individual tooth detection, and 3) segmentation. We first extract the alignment information of the patient by pose regression neural networks to attain a volume-of-interest (VOI) region and realign the input image, which reduces the inter-overlapping area between tooth bounding boxes. Then, individual tooth regions are localized within a VOI realigned image using a convolutional detector. We improved the accuracy of the detector by employing non-maximum suppression and multiclass classification metrics in the region proposal network. Finally, we apply a convolutional neural network (CNN) to perform individual tooth segmentation by converting the pixel-wise labeling task to a distance regression task. Metal-intensive image augmentation is also employed for a robust segmentation of metal artifacts. The result shows that our proposed method outperforms other state-of-the-art methods, especially for teeth with metal artifacts. The primary significance of the proposed method is two-fold: 1) an introduction of pose-aware VOI realignment followed by a robust tooth detection and 2) a metal-robust CNN framework for accurate tooth segmentation.