 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Dependent Video Representation for Moment Retrieval and Highlight Detection
Mar 24, 2023Recently, video moment retrieval and highlight detection (MR/HD) are being spotlighted as the demand for video understanding is drastically increased. The key objective of MR/HD is to localize the moment and estimate clip-wise accordance level, i.e., saliency score, to the given text query. Although the recent transformer-based models brought some advances, we found that these methods do not fully exploit the information of a given query. For example, the relevance between text query and video contents is sometimes neglected when predicting the moment and its saliency. To tackle this issue, we introduce Query-Dependent DETR (QD-DETR), a detection transformer tailored for MR/HD. As we observe the insignificant role of a given query in transformer architectures, our encoding module starts with cross-attention layers to explicitly inject the context of text query into video representation. Then, to enhance the model's capability of exploiting the query information, we manipulate the video-query pairs to produce irrelevant pairs. Such negative (irrelevant) video-query pairs are trained to yield low saliency scores, which in turn, encourages the model to estimate precise accordance between query-video pairs. Lastly, we present an input-adaptive saliency predictor which adaptively defines the criterion of saliency scores for the given video-query pairs. Our extensive studies verify the importance of building the query-dependent representation for MR/HD. Specifically, QD-DETR outperforms state-of-the-art methods on QVHighlights, TVSum, and Charades-STA datasets. Codes are available at github.com/wjun0830/QD-DETR.
Technical Report for CVPR 2022 LOVEU AQTC Challenge
Jun 29, 2022

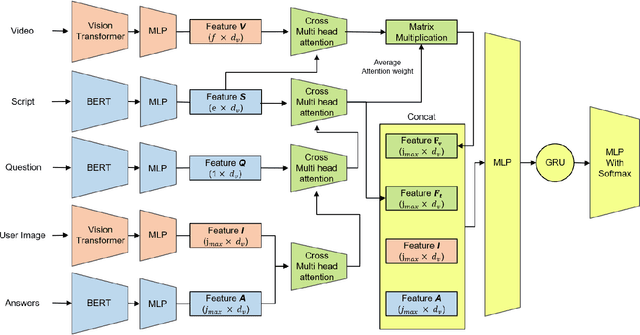
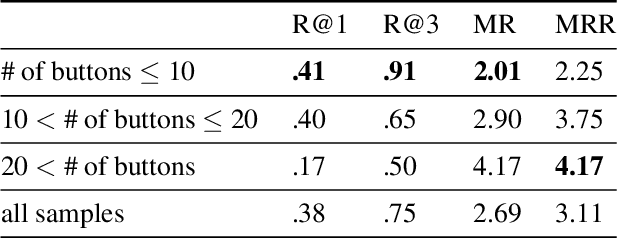
This technical report presents the 2nd winning model for AQTC, a task newly introduced in CVPR 2022 LOng-form VidEo Understanding (LOVEU) challenges. This challenge faces difficulties with multi-step answers, multi-modal, and diverse and changing button representations in video. We address this problem by proposing a new context ground module attention mechanism for more effective feature mapping. In addition, we also perform the analysis over the number of buttons and ablation study of different step networks and video features. As a result, we achieved the overall 2nd place in LOVEU competition track 3, specifically the 1st place in two out of four evaluation metrics. Our code is available at https://github.com/jaykim9870/ CVPR-22_LOVEU_unipyler.