 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report for CVPR 2022 LOVEU AQTC Challenge
Paper and Code


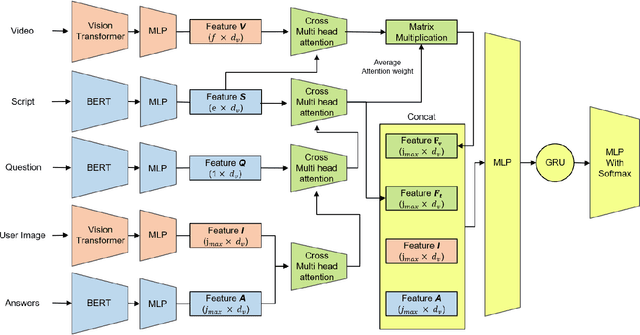
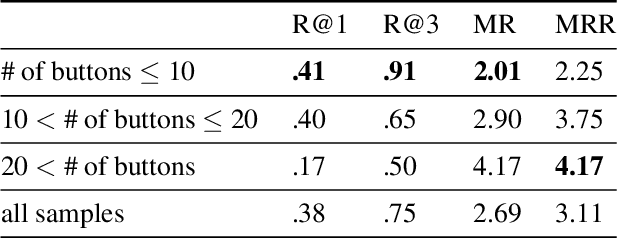
This technical report presents the 2nd winning model for AQTC, a task newly introduced in CVPR 2022 LOng-form VidEo Understanding (LOVEU) challenges. This challenge faces difficulties with multi-step answers, multi-modal, and diverse and changing button representations in video. We address this problem by proposing a new context ground module attention mechanism for more effective feature mapping. In addition, we also perform the analysis over the number of buttons and ablation study of different step networks and video features. As a result, we achieved the overall 2nd place in LOVEU competition track 3, specifically the 1st place in two out of four evaluation metrics. Our code is available at https://github.com/jaykim9870/ CVPR-22_LOVEU_unipyler.