 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVHighlights: Towards Extremely Long Sport Video Highlight Detection
Jun 05, 2026While highlight detection for long-form videos is of great practical importance, most existing methods remain limited to short-form content, largely due to the absence of a suitable benchmark. To bridge this gap, we introduce SVHighlights, to the best of our knowledge, the first benchmark for highlight detection in extremely long sports videos, each exceeding one hour in duration, across multiple sports categories. SVHighlights is constructed from pairs of full-length sports videos and their corresponding official highlight videos using a dataset generation pipeline, enabling scalable label generation without conventional per-clip saliency annotation. The benchmark comprises 320 videos with an average duration of 2.00 hours and a total of 640.18 hours, substantially exceeding previous datasets. Existing methods also face fundamental challenges on long videos: models trained on short clips fail to generalize to hour-long content, and their clip-level scoring lacks the broader context needed to identify highlights. To address this and provide a strong baseline, we present TF-SELECTOR, a training-free segment-based approach that divides each video into context-aware segments by merging adjacent shots sharing the same semantic content, and predicts segment-level saliency scores using a large language model with multimodal inputs including visual captions, transcripts, and audio volume. Experiments demonstrate that TF-SELECTOR achieves superior performance across most metrics compared to Video Temporal Grounding (VTG)-tuned baselines, with improvements of +3.12 in HIT@1, +4.06 in HIT@K, and +2.95 in IoU. These results establish SVHighlights as a challenging testbed for long-form highlight detection and demonstrate that a simple segment-based strategy can effectively scale to hour-long videos.
Environmental Understanding Vision-Language Model for Embodied Agent
Apr 21, 2026Vision-language models (VLMs) have shown strong perception and reasoning abilities for instruction-following embodied agents. However, despite these abilities and their generalization performance, they still face limitations in environmental understanding, often failing on interactions or relying on environment metadata during execution. To address this challenge, we propose a novel framework named Environmental Understanding Embodied Agent (EUEA), which fine-tunes four core skills: 1) object perception for identifying relevant objects, 2) task planning for generating interaction subgoals, 3) action understanding for judging success likelihood, and 4) goal recognition for determining goal completion. By fine-tuning VLMs with EUEA skills, our framework enables more reliable task execution for instruction-following. We further introduce a recovery step that leverages these core skills and a group relative policy optimization (GRPO) stage that refines inconsistent skill predictions. The recovery step samples alternative actions to correct failure cases, and the GRPO stage refines inconsistent skill predictions. Across ALFRED tasks, our VLM significantly outperforms a behavior-cloning baseline, achieving an 8.86% improvement in average success rate. The recovery and GRPO stages provide an additional 3.03% gain, further enhancing overall performance. Finally, our skill-level analyses reveal key limitations in the environmental understanding of closed- and open-source VLMs and identify the capabilities necessary for effective agent-environment interaction.
Cross-Modal Emotion Transfer for Emotion Editing in Talking Face Video
Apr 09, 2026Talking face generation has gained significant attention as a core application of generative models. To enhance the expressiveness and realism of synthesized videos, emotion editing in talking face video plays a crucial role. However, existing approaches often limit expressive flexibility and struggle to generate extended emotions. Label-based methods represent emotions with discrete categories, which fail to capture a wide range of emotions. Audio-based methods can leverage emotionally rich speech signals - and even benefit from expressive text-to-speech (TTS) synthesis - but they fail to express the target emotions because emotions and linguistic contents are entangled in emotional speeches. Images-based methods, on the other hand, rely on target reference images to guide emotion transfer, yet they require high-quality frontal views and face challenges in acquiring reference data for extended emotions (e.g., sarcasm). To address these limitations, we propose Cross-Modal Emotion Transfer (C-MET), a novel approach that generates facial expressions based on speeches by modeling emotion semantic vectors between speech and visual feature spaces. C-MET leverages a large-scale pretrained audio encoder and a disentangled facial expression encoder to learn emotion semantic vectors that represent the difference between two different emotional embeddings across modalities. Extensive experiments on the MEAD and CREMA-D datasets demonstrate that our method improves emotion accuracy by 14% over state-of-the-art methods, while generating expressive talking face videos - even for unseen extended emotions. Code, checkpoint, and demo are available at https://chanhyeok-choi.github.io/C-MET/
V-Warper: Appearance-Consistent Video Diffusion Personalization via Value Warping
Dec 13, 2025Video personalization aims to generate videos that faithfully reflect a user-provided subject while following a text prompt. However, existing approaches often rely on heavy video-based finetuning or large-scale video datasets, which impose substantial computational cost and are difficult to scale. Furthermore, they still struggle to maintain fine-grained appearance consistency across frames. To address these limitations, we introduce V-Warper, a training-free coarse-to-fine personalization framework for transformer-based video diffusion models. The framework enhances fine-grained identity fidelity without requiring any additional video training. (1) A lightweight coarse appearance adaptation stage leverages only a small set of reference images, which are already required for the task. This step encodes global subject identity through image-only LoRA and subject-embedding adaptation. (2) A inference-time fine appearance injection stage refines visual fidelity by computing semantic correspondences from RoPE-free mid-layer query--key features. These correspondences guide the warping of appearance-rich value representations into semantically aligned regions of the generation process, with masking ensuring spatial reliability. V-Warper significantly improves appearance fidelity while preserving prompt alignment and motion dynamics, and it achieves these gains efficiently without large-scale video finetuning.
Data Descriptions from Large Language Models with Influence Estimation
Nov 11, 2025



Deep learning models have been successful in many areas but understanding their behaviors still remains a black-box. Most prior explainable AI (XAI) approaches have focused on interpreting and explaining how models make predictions. In contrast, we would like to understand how data can be explained with deep learning model training and propose a novel approach to understand the data via one of the most common media - language - so that humans can easily understand. Our approach proposes a pipeline to generate textual descriptions that can explain the data with large language models by incorporating external knowledge bases. However, generated data descriptions may still include irrelevant information, so we introduce to exploit influence estimation to choose the most informative textual descriptions, along with the CLIP score. Furthermore, based on the phenomenon of cross-modal transferability, we propose a novel benchmark task named cross-modal transfer classification to examine the effectiveness of our textual descriptions. In the experiment of zero-shot setting, we show that our textual descriptions are more effective than other baseline descriptions, and furthermore, we successfully boost the performance of the model trained only on images across all nine image classification datasets. These results are further supported by evaluation using GPT-4o. Through our approach, we may gain insights into the inherent interpretability of the decision-making process of the model.
VEHME: A Vision-Language Model For Evaluating Handwritten Mathematics Expressions
Oct 26, 2025Automatically assessing handwritten mathematical solutions is an important problem in educational technology with practical applications, but it remains a significant challenge due to the diverse formats, unstructured layouts, and symbolic complexity of student work. To address this challenge, we introduce VEHME-a Vision-Language Model for Evaluating Handwritten Mathematics Expressions-designed to assess open-form handwritten math responses with high accuracy and interpretable reasoning traces. VEHME integrates a two-phase training pipeline: (i) supervised fine-tuning using structured reasoning data, and (ii) reinforcement learning that aligns model outputs with multi-dimensional grading objectives, including correctness, reasoning depth, and error localization. To enhance spatial understanding, we propose an Expression-Aware Visual Prompting Module, trained on our synthesized multi-line math expressions dataset to robustly guide attention in visually heterogeneous inputs. Evaluated on AIHub and FERMAT datasets, VEHME achieves state-of-the-art performance among open-source models and approaches the accuracy of proprietary systems, demonstrating its potential as a scalable and accessible tool for automated math assessment. Our training and experiment code is publicly available at our GitHub repository.
Grouped Differential Attention
Oct 08, 2025The self-attention mechanism, while foundational to modern Transformer architectures, suffers from a critical inefficiency: it frequently allocates substantial attention to redundant or noisy context. Differential Attention addressed this by using subtractive attention maps for signal and noise, but its required balanced head allocation imposes rigid constraints on representational flexibility and scalability. To overcome this, we propose Grouped Differential Attention (GDA), a novel approach that introduces unbalanced head allocation between signal-preserving and noise-control groups. GDA significantly enhances signal focus by strategically assigning more heads to signal extraction and fewer to noise-control, stabilizing the latter through controlled repetition (akin to GQA). This design achieves stronger signal fidelity with minimal computational overhead. We further extend this principle to group-differentiated growth, a scalable strategy that selectively replicates only the signal-focused heads, thereby ensuring efficient capacity expansion. Through large-scale pretraining and continual training experiments, we demonstrate that moderate imbalance ratios in GDA yield substantial improvements in generalization and stability compared to symmetric baselines. Our results collectively establish that ratio-aware head allocation and selective expansion offer an effective and practical path toward designing scalable, computation-efficient Transformer architectures.
Towards Human-like Multimodal Conversational Agent by Generating Engaging Speech
Sep 18, 2025Human conversation involves language, speech, and visual cues, with each medium providing complementary information. For instance, speech conveys a vibe or tone not fully captured by text alone. While multimodal LLMs focus on generating text responses from diverse inputs, less attention has been paid to generating natural and engaging speech. We propose a human-like agent that generates speech responses based on conversation mood and responsive style information. To achieve this, we build a novel MultiSensory Conversation dataset focused on speech to enable agents to generate natural speech. We then propose a multimodal LLM-based model for generating text responses and voice descriptions, which are used to generate speech covering paralinguistic information. Experimental results demonstrate the effectiveness of utilizing both visual and audio modalities in conversation to generate engaging speech. The source code is available in https://github.com/kimtaesu24/MSenC
Semi-Supervised Audio-Visual Video Action Recognition with Audio Source Localization Guided Mixup
Mar 04, 2025



Video action recognition is a challenging but important task for understanding and discovering what the video does. However, acquiring annotations for a video is costly, and semi-supervised learning (SSL) has been studied to improve performance even with a small number of labeled data in the task. Prior studies for semi-supervised video action recognition have mostly focused on using single modality - visuals - but the video is multi-modal, so utilizing both visuals and audio would be desirable and improve performance further, which has not been explored well. Therefore, we propose audio-visual SSL for video action recognition, which uses both visual and audio together, even with quite a few labeled data, which is challenging. In addition, to maximize the information of audio and video, we propose a novel audio source localization-guided mixup method that considers inter-modal relations between video and audio modalities. In experiments on UCF-51, Kinetics-400, and VGGSound datasets, our model shows the superior performance of the proposed semi-supervised audio-visual action recognition framework and audio source localization-guided mixup.
RingFormer: Rethinking Recurrent Transformer with Adaptive Level Signals
Feb 18, 2025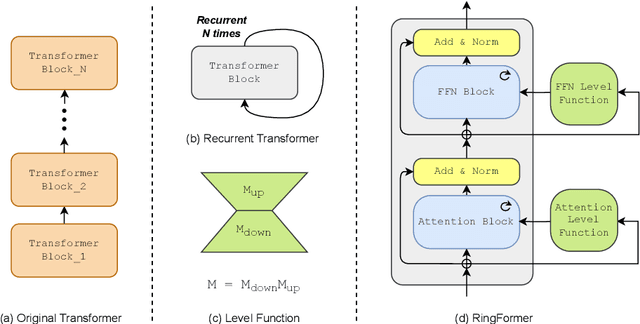

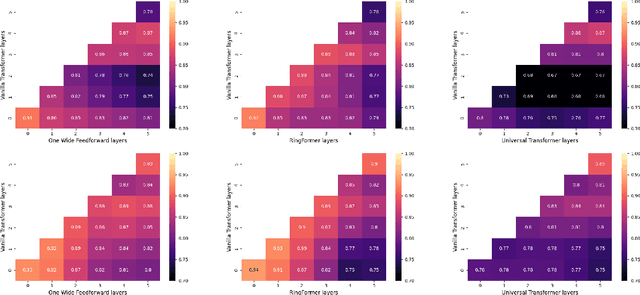
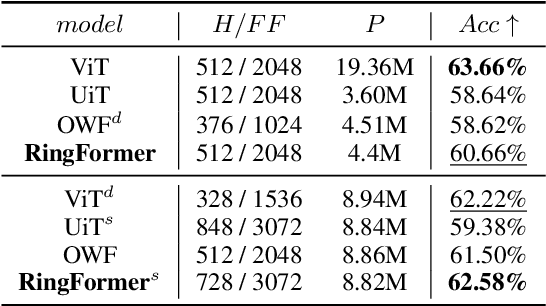
Transformers have achieved great success in effectively processing sequential data such as text. Their architecture consisting of several attention and feedforward blocks can model relations between elements of a sequence in parallel manner, which makes them very efficient to train and effective in sequence modeling. Even though they have shown strong performance in processing sequential data, the size of their parameters is considerably larger when compared to other architectures such as RNN and CNN based models. Therefore, several approaches have explored parameter sharing and recurrence in Transformer models to address their computational demands. However, such methods struggle to maintain high performance compared to the original transformer model. To address this challenge, we propose our novel approach, RingFormer, which employs one Transformer layer that processes input repeatedly in a circular, ring-like manner, while utilizing low-rank matrices to generate input-dependent level signals. This allows us to reduce the model parameters substantially while maintaining high performance in a variety of tasks such as translation and image classification, as validated in the experiments.