 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Text-guided Infinite Image Synthesis with LLM guidance
Jul 17, 2024Text-guided image editing and generation methods have diverse real-world applications. However, text-guided infinite image synthesis faces several challenges. First, there is a lack of text-image paired datasets with high-resolution and contextual diversity. Second, expanding images based on text requires global coherence and rich local context understanding. Previous studies have mainly focused on limited categories, such as natural landscapes, and also required to train on high-resolution images with paired text. To address these challenges, we propose a novel approach utilizing Large Language Models (LLMs) for both global coherence and local context understanding, without any high-resolution text-image paired training dataset. We train the diffusion model to expand an image conditioned on global and local captions generated from the LLM and visual feature. At the inference stage, given an image and a global caption, we use the LLM to generate a next local caption to expand the input image. Then, we expand the image using the global caption, generated local caption and the visual feature to consider global consistency and spatial local context. In experiments, our model outperforms the baselines both quantitatively and qualitatively. Furthermore, our model demonstrates the capability of text-guided arbitrary-sized image generation in zero-shot manner with LLM guidance.
Grid Diffusion Models for Text-to-Video Generation
Mar 30, 2024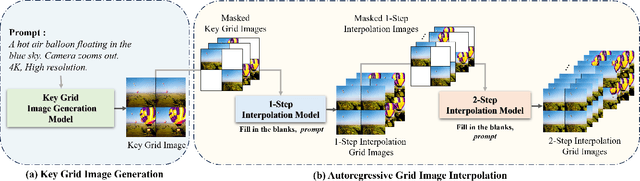

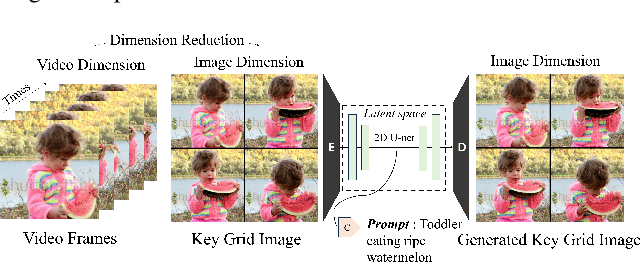

Recent advances in the diffusion models have significantly improved text-to-image generation. However, generating videos from text is a more challenging task than generating images from text, due to the much larger dataset and higher computational cost required. Most existing video generation methods use either a 3D U-Net architecture that considers the temporal dimension or autoregressive generation. These methods require large datasets and are limited in terms of computational costs compared to text-to-image generation. To tackle these challenges, we propose a simple but effective novel grid diffusion for text-to-video generation without temporal dimension in architecture and a large text-video paired dataset. We can generate a high-quality video using a fixed amount of GPU memory regardless of the number of frames by representing the video as a grid image. Additionally, since our method reduces the dimensions of the video to the dimensions of the image, various image-based methods can be applied to videos, such as text-guided video manipulation from image manipulation. Our proposed method outperforms the existing methods in both quantitative and qualitative evaluations, demonstrating the suitability of our model for real-world video generation.