 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatbot is Not All You Need: Information-rich Prompting for More Realistic Responses
Dec 25, 2023Recent Large Language Models (LLMs) have shown remarkable capabilities in mimicking fictional characters or real humans in conversational settings. However, the realism and consistency of these responses can be further enhanced by providing richer information of the agent being mimicked. In this paper, we propose a novel approach to generate more realistic and consistent responses from LLMs, leveraging five senses, attributes, emotional states, relationship with the interlocutor, and memories. By incorporating these factors, we aim to increase the LLM's capacity for generating natural and realistic reactions in conversational exchanges. Through our research, we expect to contribute to the development of LLMs that demonstrate improved capabilities in mimicking fictional characters. We release a new benchmark dataset and all our codes, prompts, and sample results on our Github: https://github.com/srafsasm/InfoRichBot
Sound of Story: Multi-modal Storytelling with Audio
Oct 30, 2023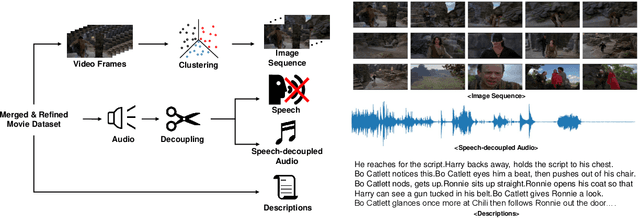



Storytelling is multi-modal in the real world. When one tells a story, one may use all of the visualizations and sounds along with the story itself. However, prior studies on storytelling datasets and tasks have paid little attention to sound even though sound also conveys meaningful semantics of the story. Therefore, we propose to extend story understanding and telling areas by establishing a new component called "background sound" which is story context-based audio without any linguistic information. For this purpose, we introduce a new dataset, called "Sound of Story (SoS)", which has paired image and text sequences with corresponding sound or background music for a story. To the best of our knowledge, this is the largest well-curated dataset for storytelling with sound. Our SoS dataset consists of 27,354 stories with 19.6 images per story and 984 hours of speech-decoupled audio such as background music and other sounds. As benchmark tasks for storytelling with sound and the dataset, we propose retrieval tasks between modalities, and audio generation tasks from image-text sequences, introducing strong baselines for them. We believe the proposed dataset and tasks may shed light on the multi-modal understanding of storytelling in terms of sound. Downloading the dataset and baseline codes for each task will be released in the link: https://github.com/Sosdatasets/SoS_Dataset.