 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Audio-Visual Video Action Recognition with Audio Source Localization Guided Mixup
Mar 04, 2025



Video action recognition is a challenging but important task for understanding and discovering what the video does. However, acquiring annotations for a video is costly, and semi-supervised learning (SSL) has been studied to improve performance even with a small number of labeled data in the task. Prior studies for semi-supervised video action recognition have mostly focused on using single modality - visuals - but the video is multi-modal, so utilizing both visuals and audio would be desirable and improve performance further, which has not been explored well. Therefore, we propose audio-visual SSL for video action recognition, which uses both visual and audio together, even with quite a few labeled data, which is challenging. In addition, to maximize the information of audio and video, we propose a novel audio source localization-guided mixup method that considers inter-modal relations between video and audio modalities. In experiments on UCF-51, Kinetics-400, and VGGSound datasets, our model shows the superior performance of the proposed semi-supervised audio-visual action recognition framework and audio source localization-guided mixup.
Sound of Story: Multi-modal Storytelling with Audio
Oct 30, 2023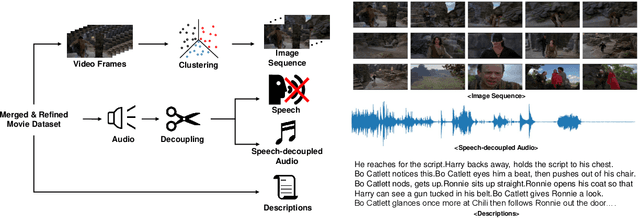



Storytelling is multi-modal in the real world. When one tells a story, one may use all of the visualizations and sounds along with the story itself. However, prior studies on storytelling datasets and tasks have paid little attention to sound even though sound also conveys meaningful semantics of the story. Therefore, we propose to extend story understanding and telling areas by establishing a new component called "background sound" which is story context-based audio without any linguistic information. For this purpose, we introduce a new dataset, called "Sound of Story (SoS)", which has paired image and text sequences with corresponding sound or background music for a story. To the best of our knowledge, this is the largest well-curated dataset for storytelling with sound. Our SoS dataset consists of 27,354 stories with 19.6 images per story and 984 hours of speech-decoupled audio such as background music and other sounds. As benchmark tasks for storytelling with sound and the dataset, we propose retrieval tasks between modalities, and audio generation tasks from image-text sequences, introducing strong baselines for them. We believe the proposed dataset and tasks may shed light on the multi-modal understanding of storytelling in terms of sound. Downloading the dataset and baseline codes for each task will be released in the link: https://github.com/Sosdatasets/SoS_Dataset.