 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Translate for Multilingual Reasoning
Jun 01, 2026Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, but still exhibit substantial multilingual reasoning gaps, largely due to language-understanding failures in non-English inputs. English translation can mitigate these failures by expressing non-English inputs in a form that RLMs can more reliably interpret, yet translating every input is unnecessary when the model can reason reliably from the original query. To address this challenge, we propose Luar, a Language Understanding Boundary-aware Reinforcement Learning framework that trains RLMs to selectively invoke translation when direct understanding is unreliable. Luar trains the model to choose between solving the original input directly and reasoning over its English translation, encouraging translation only when translator-augmented reasoning is expected to substantially outperform direct reasoning. Across multilingual reasoning benchmarks, Luar outperforms standard GRPO and other training-based baselines, with particularly large gains on low-resource languages. Further analysis shows that Luar avoids unnecessary translation in cases where direct reasoning is sufficient, while extending its translator-call behavior to unseen low-resource languages. Together, our work suggests a selective approach to multilingual reasoning: RLMs can learn to invoke translation only when their direct understanding is unreliable. The project will be made publicly available at https://github.com/deokhk/LUAR
Decompose-and-Refine: Structured Legal Question Answering with Parametric Retrieval
May 23, 2026Large language models (LLMs) have shown strong performance in the legal domain, demonstrating notable potential in Legal Question Answering (LQA). However, unlike general QA, LQA requires answers that are not only accurate but also rigorously grounded in explicit legal authority. In statutory LQA, many questions require multi-hop reasoning across multiple legal issues, substantially increasing the risk of hallucination, thereby making accurate retrieval of supporting statutory provisions a critical prerequisite. Despite recent progress in multi-hop QA, existing approaches often rely on reasoning in natural language or retrieval without explicit query reformulation, leaving the vocabulary gap between user questions and statutory text largely unaddressed. To address this challenge, we propose Decompose-and-Refine (DaR), a statute-grounded LQA framework that tightly integrates step-wise question decomposition with parametric knowledge-based query refinement. DaR progressively decomposes a complex legal question into atomic sub-questions and generates statute-aligned parametric queries for each sub-question, enabling the selection of a single most central statutory provision corresponding to each legal issue. We evaluate DaR on KoBLEX, a Korean multi-hop LQA benchmark grounded in statutory law, using Qwen3-32B and Gemma3-27B. Experimental results demonstrate that DaR consistently improves both retrieval accuracy and final answer quality over existing approaches. Moreover, by explicitly separating sub-questions and their corresponding statutory provisions, DaR facilitates transparent, issue-level verification of complex legal reasoning processes.
A Multi-Agent Framework for Feature-Constrained Difficulty Control in Reading Comprehension Item Generation
May 19, 2026Recent studies in difficulty-controlled reading comprehension item generation have leveraged large language models (LLMs) to produce items by adjusting difficulty-related features. However, existing methods typically rely on a single-agent prompting approach, which often fails to consistently satisfy specified feature constraints, resulting in items that deviate from the target difficulty level. To address this limitation, we introduce MAFIG, a Multi-agent Framework for Feature-constrained Item Generation, where multiple LLM agents and feature-specific evaluators collaborate to generate and iteratively revise items based on intended constraints. Furthermore, to verify the efficacy of MAFIG in difficulty control, we propose a method for constructing a sequence of feature constraint sets that yield items with monotonically increasing difficulty. Experimental results demonstrate that MAFIG generates items that adhere to target constraints at a significantly higher rate than baselines, achieving robust difficulty control through the difficulty-calibrated constraint sequence.
Behavior-Aware Item Modeling via Dynamic Procedural Solution Representations for Knowledge Tracing
Apr 09, 2026Knowledge Tracing (KT) aims to predict learners' future performance from past interactions. While recent KT approaches have improved via learning item representations aligned with Knowledge Components, they overlook the procedural dynamics of problem solving. We propose Behavior-Aware Item Modeling (BAIM), a framework that enriches item representations by integrating dynamic procedural solution information. BAIM leverages a reasoning language model to decompose each item's solution into four problem-solving stages (i.e., understand, plan, carry out, and look back), pedagogically grounded in Polya's framework. Specifically, it derives stage-level representations from per-stage embedding trajectories, capturing latent signals beyond surface features. To reflect learner heterogeneity, BAIM adaptively routes these stage-wise representations, introducing a context-conditioned mechanism within a KT backbone, allowing different procedural stages to be emphasized for different learners. Experiments on XES3G5M and NIPS34 show that BAIM consistently outperforms strong pretraining-based baselines, achieving particularly large gains under repeated learner interactions.
PSY-STEP: Structuring Therapeutic Targets and Action Sequences for Proactive Counseling Dialogue Systems
Apr 06, 2026Cognitive Behavioral Therapy (CBT) aims to identify and restructure automatic negative thoughts pertaining to involuntary interpretations of events, yet existing counseling agents struggle to identify and address them in dialogue settings. To bridge this gap, we introduce STEP, a dataset that models CBT counseling by explicitly reflecting automatic thoughts alongside dynamic, action-level counseling sequences. Using this dataset, we train STEPPER, a counseling agent that proactively elicits automatic thoughts and executes cognitively grounded interventions. To further enhance both decision accuracy and empathic responsiveness, we refine STEPPER through preference learning based on simulated, synthesized counseling sessions. Extensive CBT-aligned evaluations show that STEPPER delivers more clinically grounded, coherent, and personalized counseling compared to other strong baseline models, and achieves higher counselor competence without inducing emotional disruption.
Mixture-of-Experts with Intermediate CTC Supervision for Accented Speech Recognition
Feb 02, 2026Accented speech remains a persistent challenge for automatic speech recognition (ASR), as most models are trained on data dominated by a few high-resource English varieties, leading to substantial performance degradation for other accents. Accent-agnostic approaches improve robustness yet struggle with heavily accented or unseen varieties, while accent-specific methods rely on limited and often noisy labels. We introduce Moe-Ctc, a Mixture-of-Experts architecture with intermediate CTC supervision that jointly promotes expert specialization and generalization. During training, accent-aware routing encourages experts to capture accent-specific patterns, which gradually transitions to label-free routing for inference. Each expert is equipped with its own CTC head to align routing with transcription quality, and a routing-augmented loss further stabilizes optimization. Experiments on the Mcv-Accent benchmark demonstrate consistent gains across both seen and unseen accents in low- and high-resource conditions, achieving up to 29.3% relative WER reduction over strong FastConformer baselines.
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
Oct 31, 2025Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, yet they still suffer from a multilingual reasoning gap, performing better in high-resource languages than in low-resource ones. While recent efforts have reduced this gap, its underlying causes remain largely unexplored. In this paper, we address this by showing that the multilingual reasoning gap largely stems from failures in language understanding-the model's inability to represent the multilingual input meaning into the dominant language (i.e., English) within its reasoning trace. This motivates us to examine whether understanding failures can be detected, as this ability could help mitigate the multilingual reasoning gap. To this end, we evaluate a range of detection methods and find that understanding failures can indeed be identified, with supervised approaches performing best. Building on this, we propose Selective Translation, a simple yet effective strategy that translates the multilingual input into English only when an understanding failure is detected. Experimental results show that Selective Translation bridges the multilingual reasoning gap, achieving near full-translation performance while using translation for only about 20% of inputs. Together, our work demonstrates that understanding failures are the primary cause of the multilingual reasoning gap and can be detected and selectively mitigated, providing key insight into its origin and a promising path toward more equitable multilingual reasoning. Our code and data are publicly available at https://github.com/deokhk/RLM_analysis.
Self-Correcting Code Generation Using Small Language Models
May 29, 2025Self-correction has demonstrated potential in code generation by allowing language models to revise and improve their outputs through successive refinement. Recent studies have explored prompting-based strategies that incorporate verification or feedback loops using proprietary models, as well as training-based methods that leverage their strong reasoning capabilities. However, whether smaller models possess the capacity to effectively guide their outputs through self-reflection remains unexplored. Our findings reveal that smaller models struggle to exhibit reflective revision behavior across both self-correction paradigms. In response, we introduce CoCoS, an approach designed to enhance the ability of small language models for multi-turn code correction. Specifically, we propose an online reinforcement learning objective that trains the model to confidently maintain correct outputs while progressively correcting incorrect outputs as turns proceed. Our approach features an accumulated reward function that aggregates rewards across the entire trajectory and a fine-grained reward better suited to multi-turn correction scenarios. This facilitates the model in enhancing initial response quality while achieving substantial improvements through self-correction. With 1B-scale models, CoCoS achieves improvements of 35.8% on the MBPP and 27.7% on HumanEval compared to the baselines.
Response Tuning: Aligning Large Language Models without Instruction
Oct 03, 2024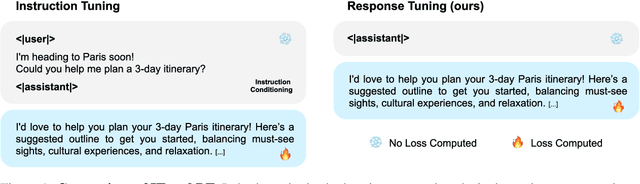
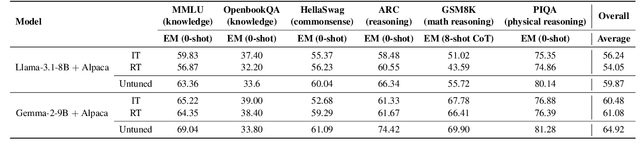
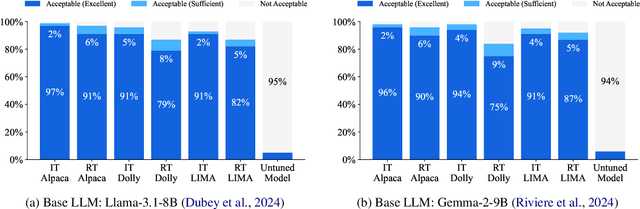

Instruction tuning-supervised fine-tuning using instruction-response pairs-is a foundational step in transitioning pre-trained Large Language Models (LLMs) into helpful and safe chat assistants. Our hypothesis is that establishing an adequate output space can enable such a transition given the capabilities inherent in pre-trained LLMs. To verify this, we propose Response Tuning (RT), which eliminates the instruction-conditioning step in instruction tuning and solely focuses on response space supervision. Our experiments demonstrate that RT models, trained only using responses, can effectively respond to a wide range of instructions and exhibit helpfulness comparable to that of their instruction-tuned counterparts. Furthermore, we observe that controlling the training response distribution can significantly improve their user preference or elicit target behaviors such as refusing assistance for unsafe queries. Our findings illuminate the role of establishing an adequate output space in alignment, highlighting the potential of the extensive inherent capabilities of pre-trained LLMs.
Mixed-Session Conversation with Egocentric Memory
Oct 03, 2024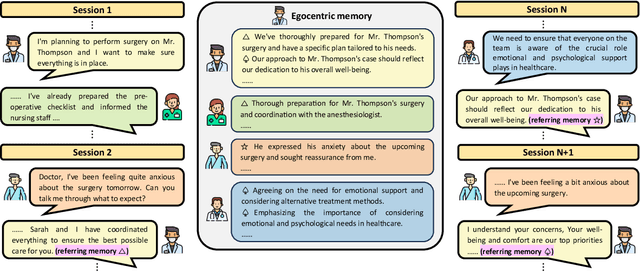


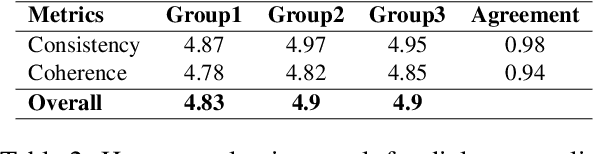
Recently introduced dialogue systems have demonstrated high usability. However, they still fall short of reflecting real-world conversation scenarios. Current dialogue systems exhibit an inability to replicate the dynamic, continuous, long-term interactions involving multiple partners. This shortfall arises because there have been limited efforts to account for both aspects of real-world dialogues: deeply layered interactions over the long-term dialogue and widely expanded conversation networks involving multiple participants. As the effort to incorporate these aspects combined, we introduce Mixed-Session Conversation, a dialogue system designed to construct conversations with various partners in a multi-session dialogue setup. We propose a new dataset called MiSC to implement this system. The dialogue episodes of MiSC consist of 6 consecutive sessions, with four speakers (one main speaker and three partners) appearing in each episode. Also, we propose a new dialogue model with a novel memory management mechanism, called Egocentric Memory Enhanced Mixed-Session Conversation Agent (EMMA). EMMA collects and retains memories from the main speaker's perspective during conversations with partners, enabling seamless continuity in subsequent interactions. Extensive human evaluations validate that the dialogues in MiSC demonstrate a seamless conversational flow, even when conversation partners change in each session. EMMA trained with MiSC is also evaluated to maintain high memorability without contradiction throughout the entire conversation.