 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAISE: Conversational Agent for Image Search and Editing
Feb 24, 2022



Demand for image editing has been increasing as users' desire for expression is also increasing. However, for most users, image editing tools are not easy to use since the tools require certain expertise in photo effects and have complex interfaces. Hence, users might need someone to help edit their images, but having a personal dedicated human assistant for every user is impossible to scale. For that reason, an automated assistant system for image editing is desirable. Additionally, users want more image sources for diverse image editing works, and integrating an image search functionality into the editing tool is a potential remedy for this demand. Thus, we propose a dataset of an automated Conversational Agent for Image Search and Editing (CAISE). To our knowledge, this is the first dataset that provides conversational image search and editing annotations, where the agent holds a grounded conversation with users and helps them to search and edit images according to their requests. To build such a system, we first collect image search and editing conversations between pairs of annotators. The assistant-annotators are equipped with a customized image search and editing tool to address the requests from the user-annotators. The functions that the assistant-annotators conduct with the tool are recorded as executable commands, allowing the trained system to be useful for real-world application execution. We also introduce a generator-extractor baseline model for this task, which can adaptively select the source of the next token (i.e., from the vocabulary or from textual/visual contexts) for the executable command. This serves as a strong starting point while still leaving a large human-machine performance gap for useful future work. Our code and dataset are publicly available at: https://github.com/hyounghk/CAISE
End-to-end Neural Coreference Resolution Revisited: A Simple yet Effective Baseline
Jul 13, 2021

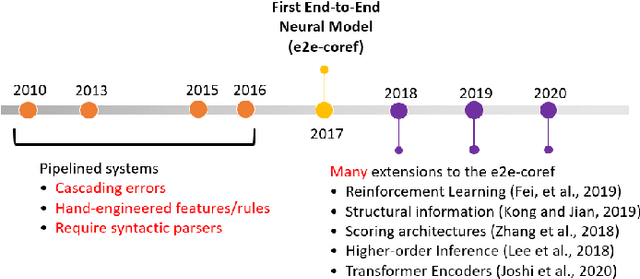

Since the first end-to-end neural coreference resolution model was introduced, many extensions to the model have been proposed, ranging from using higher-order inference to directly optimizing evaluation metrics using reinforcement learning. Despite improving the coreference resolution performance by a large margin, these extensions add a lot of extra complexity to the original model. Motivated by this observation and the recent advances in pre-trained Transformer language models, we propose a simple yet effective baseline for coreference resolution. Our model is a simplified version of the original neural coreference resolution model, however, it achieves impressive performance, outperforming all recent extended works on the public English OntoNotes benchmark. Our work provides evidence for the necessity of carefully justifying the complexity of existing or newly proposed models, as introducing a conceptual or practical simplification to an existing model can still yield competitive results.
X-METRA-ADA: Cross-lingual Meta-Transfer Learning Adaptation to Natural Language Understanding and Question Answering
Apr 20, 2021
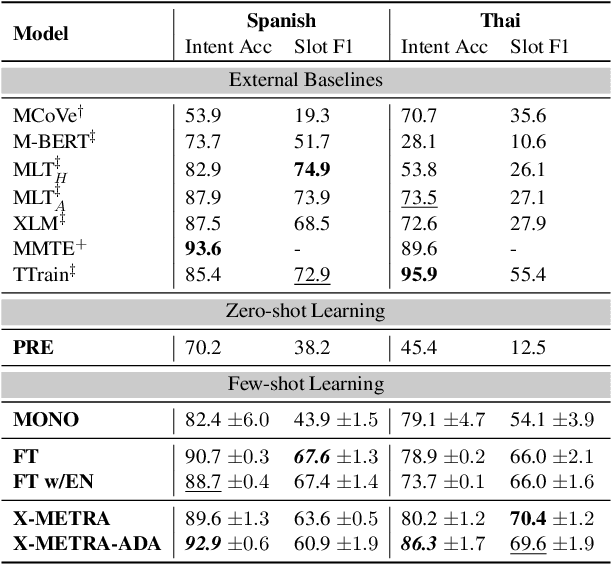

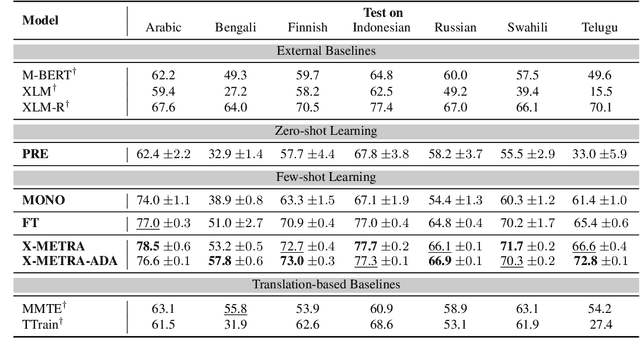
Multilingual models, such as M-BERT and XLM-R, have gained increasing popularity, due to their zero-shot cross-lingual transfer learning capabilities. However, their generalization ability is still inconsistent for typologically diverse languages and across different benchmarks. Recently, meta-learning has garnered attention as a promising technique for enhancing transfer learning under low-resource scenarios: particularly for cross-lingual transfer in Natural Language Understanding (NLU). In this work, we propose X-METRA-ADA, a cross-lingual MEta-TRAnsfer learning ADAptation approach for NLU. Our approach adapts MAML, an optimization-based meta-learning approach, to learn to adapt to new languages. We extensively evaluate our framework on two challenging cross-lingual NLU tasks: multilingual task-oriented dialog and typologically diverse question answering. We show that our approach outperforms naive fine-tuning, reaching competitive performance on both tasks for most languages. Our analysis reveals that X-METRA-ADA can leverage limited data for faster adaptation.
AutoNLU: An On-demand Cloud-based Natural Language Understanding System for Enterprises
Nov 26, 2020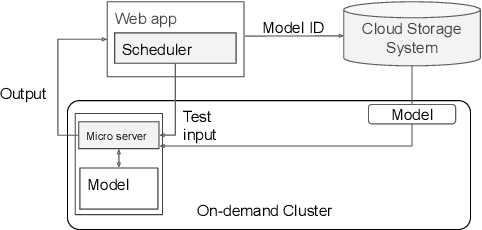
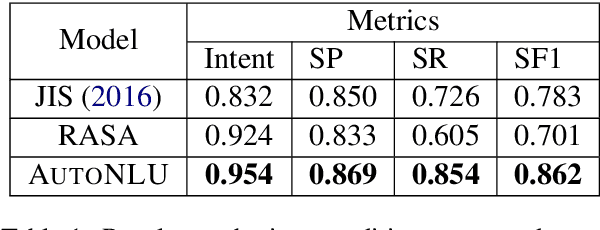
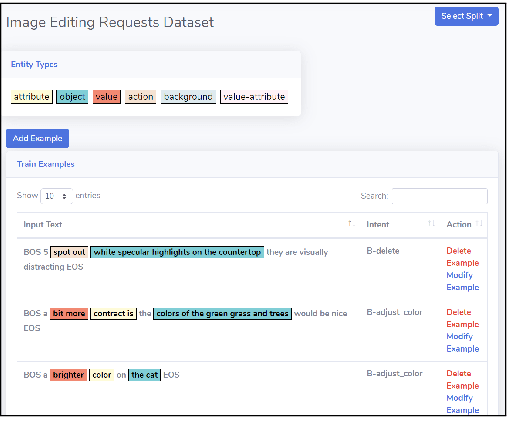
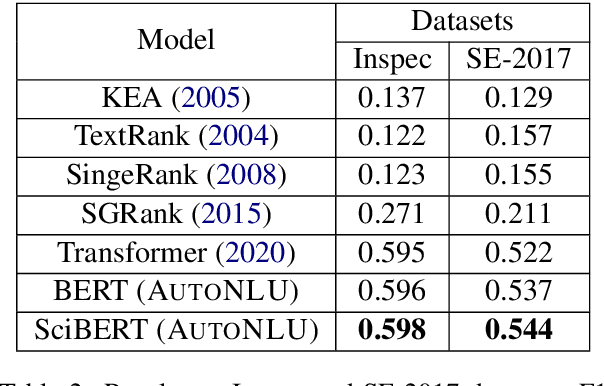
With the renaissance of deep learning, neural networks have achieved promising results on many natural language understanding (NLU) tasks. Even though the source codes of many neural network models are publicly available, there is still a large gap from open-sourced models to solving real-world problems in enterprises. Therefore, to fill this gap, we introduce AutoNLU, an on-demand cloud-based system with an easy-to-use interface that covers all common use-cases and steps in developing an NLU model. AutoNLU has supported many product teams within Adobe with different use-cases and datasets, quickly delivering them working models. To demonstrate the effectiveness of AutoNLU, we present two case studies. i) We build a practical NLU model for handling various image-editing requests in Photoshop. ii) We build powerful keyphrase extraction models that achieve state-of-the-art results on two public benchmarks. In both cases, end users only need to write a small amount of code to convert their datasets into a common format used by AutoNLU.
A Joint Learning Approach based on Self-Distillation for Keyphrase Extraction from Scientific Documents
Oct 22, 2020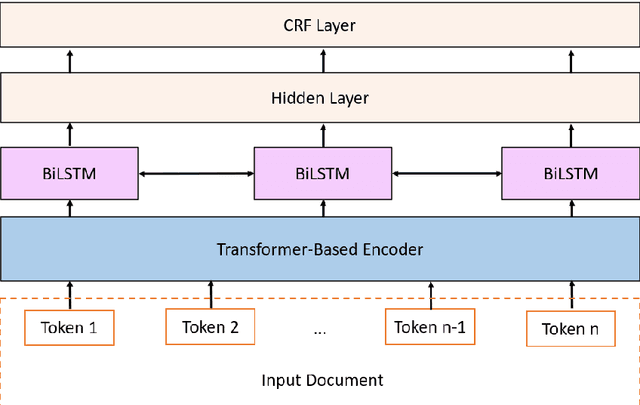
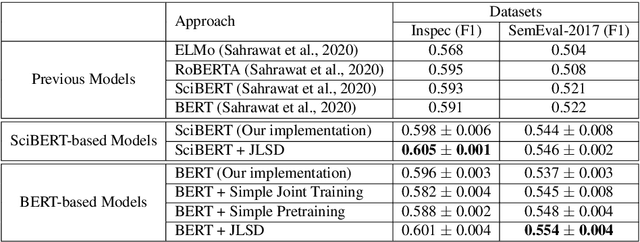
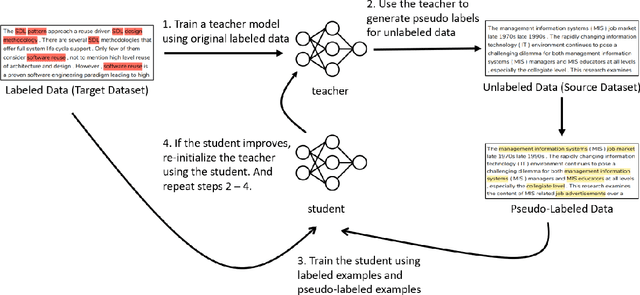

Keyphrase extraction is the task of extracting a small set of phrases that best describe a document. Most existing benchmark datasets for the task typically have limited numbers of annotated documents, making it challenging to train increasingly complex neural networks. In contrast, digital libraries store millions of scientific articles online, covering a wide range of topics. While a significant portion of these articles contain keyphrases provided by their authors, most other articles lack such kind of annotations. Therefore, to effectively utilize these large amounts of unlabeled articles, we propose a simple and efficient joint learning approach based on the idea of self-distillation. Experimental results show that our approach consistently improves the performance of baseline models for keyphrase extraction. Furthermore, our best models outperform previous methods for the task, achieving new state-of-the-art results on two public benchmarks: Inspec and SemEval-2017.
Learning to Fuse Sentences with Transformers for Summarization
Oct 08, 2020
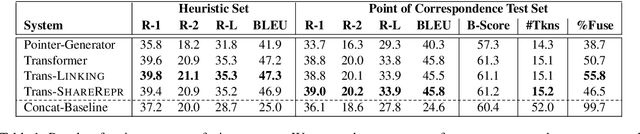
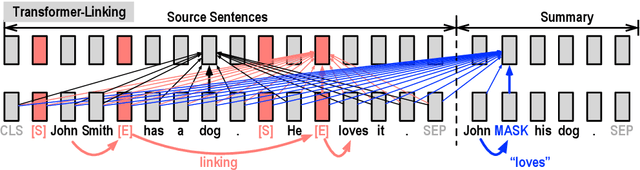

The ability to fuse sentences is highly attractive for summarization systems because it is an essential step to produce succinct abstracts. However, to date, summarizers can fail on fusing sentences. They tend to produce few summary sentences by fusion or generate incorrect fusions that lead the summary to fail to retain the original meaning. In this paper, we explore the ability of Transformers to fuse sentences and propose novel algorithms to enhance their ability to perform sentence fusion by leveraging the knowledge of points of correspondence between sentences. Through extensive experiments, we investigate the effects of different design choices on Transformer's performance. Our findings highlight the importance of modeling points of correspondence between sentences for effective sentence fusion.
A Cascade Approach to Neural Abstractive Summarization with Content Selection and Fusion
Oct 08, 2020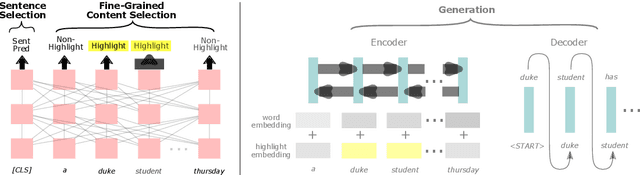

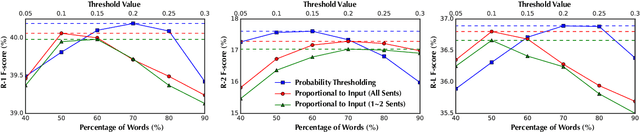
We present an empirical study in favor of a cascade architecture to neural text summarization. Summarization practices vary widely but few other than news summarization can provide a sufficient amount of training data enough to meet the requirement of end-to-end neural abstractive systems which perform content selection and surface realization jointly to generate abstracts. Such systems also pose a challenge to summarization evaluation, as they force content selection to be evaluated along with text generation, yet evaluation of the latter remains an unsolved problem. In this paper, we present empirical results showing that the performance of a cascaded pipeline that separately identifies important content pieces and stitches them together into a coherent text is comparable to or outranks that of end-to-end systems, whereas a pipeline architecture allows for flexible content selection. We finally discuss how we can take advantage of a cascaded pipeline in neural text summarization and shed light on important directions for future research.
Understanding Points of Correspondence between Sentences for Abstractive Summarization
Jun 10, 2020
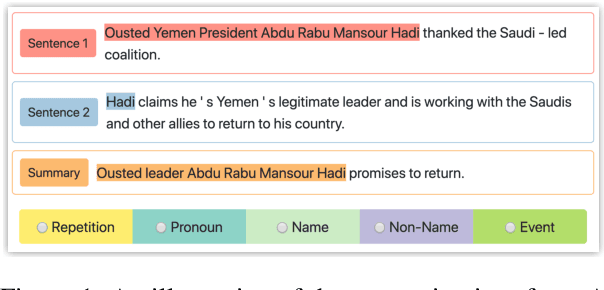
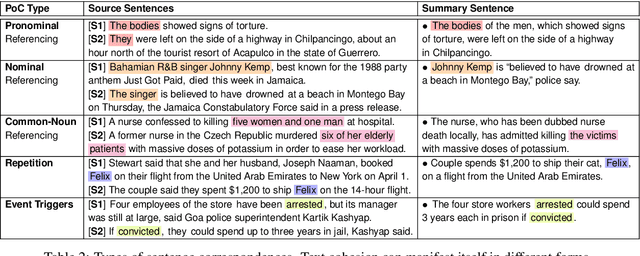

Fusing sentences containing disparate content is a remarkable human ability that helps create informative and succinct summaries. Such a simple task for humans has remained challenging for modern abstractive summarizers, substantially restricting their applicability in real-world scenarios. In this paper, we present an investigation into fusing sentences drawn from a document by introducing the notion of points of correspondence, which are cohesive devices that tie any two sentences together into a coherent text. The types of points of correspondence are delineated by text cohesion theory, covering pronominal and nominal referencing, repetition and beyond. We create a dataset containing the documents, source and fusion sentences, and human annotations of points of correspondence between sentences. Our dataset bridges the gap between coreference resolution and summarization. It is publicly shared to serve as a basis for future work to measure the success of sentence fusion systems. (https://github.com/ucfnlp/points-of-correspondence)
Efficient Deployment of Conversational Natural Language Interfaces over Databases
Jun 04, 2020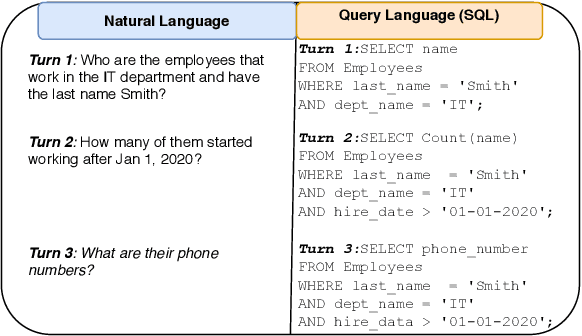

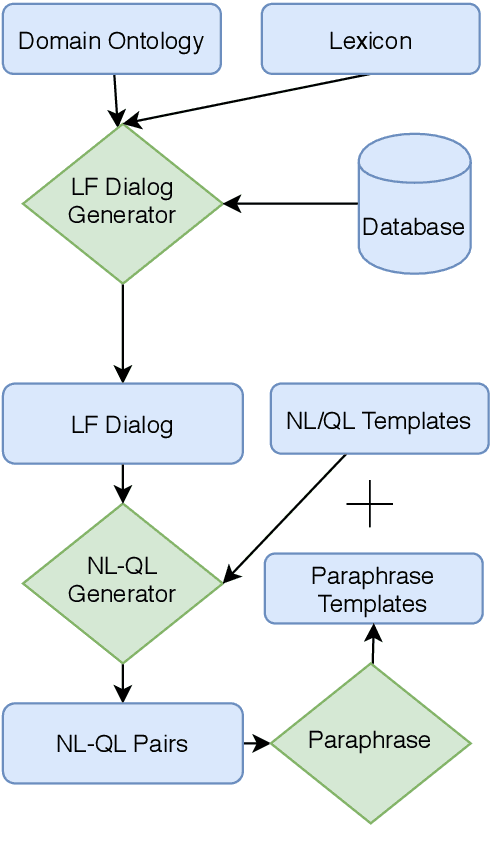
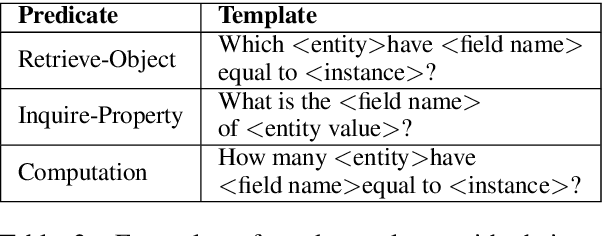
Many users communicate with chatbots and AI assistants in order to help them with various tasks. A key component of the assistant is the ability to understand and answer a user's natural language questions for question-answering (QA). Because data can be usually stored in a structured manner, an essential step involves turning a natural language question into its corresponding query language. However, in order to train most natural language-to-query-language state-of-the-art models, a large amount of training data is needed first. In most domains, this data is not available and collecting such datasets for various domains can be tedious and time-consuming. In this work, we propose a novel method for accelerating the training dataset collection for developing the natural language-to-query-language machine learning models. Our system allows one to generate conversational multi-term data, where multiple turns define a dialogue session, enabling one to better utilize chatbot interfaces. We train two current state-of-the-art NL-to-QL models, on both an SQL and SPARQL-based datasets in order to showcase the adaptability and efficacy of our created data.
KPQA: A Metric for Generative Question Answering Using Word Weights
May 01, 2020
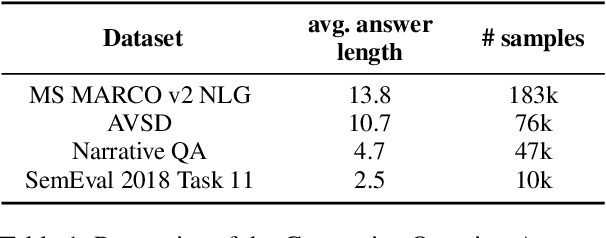
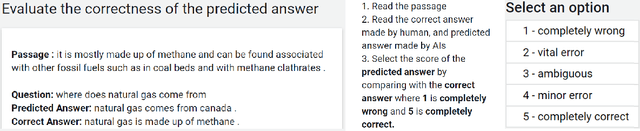

For the automatic evaluation of Generative Question Answering (genQA) systems, it is essential to assess the correctness of the generated answers. However, n-gram similarity metrics, which are widely used to compare generated texts and references, are prone to misjudge fact-based assessments. Moreover, there is a lack of benchmark datasets to measure the quality of metrics in terms of the correctness. To study a better metric for genQA, we collect high-quality human judgments of correctness on two standard genQA datasets. Using our human-evaluation datasets, we show that existing metrics based on n-gram similarity do not correlate with human judgments. To alleviate this problem, we propose a new metric for evaluating the correctness of genQA. Specifically, the new metric assigns different weights on each token via keyphrase prediction, thereby judging whether a predicted answer sentence captures the key meaning of the human judge's ground-truth. Our proposed metric shows a significantly higher correlation with human judgment than widely used existing metrics.