 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping A Framework to Support Human Evaluation of Bias in Generated Free Response Text
May 05, 2025LLM evaluation is challenging even the case of base models. In real world deployments, evaluation is further complicated by the interplay of task specific prompts and experiential context. At scale, bias evaluation is often based on short context, fixed choice benchmarks that can be rapidly evaluated, however, these can lose validity when the LLMs' deployed context differs. Large scale human evaluation is often seen as too intractable and costly. Here we present our journey towards developing a semi-automated bias evaluation framework for free text responses that has human insights at its core. We discuss how we developed an operational definition of bias that helped us automate our pipeline and a methodology for classifying bias beyond multiple choice. We additionally comment on how human evaluation helped us uncover problematic templates in a bias benchmark.
Evaluating Nuanced Bias in Large Language Model Free Response Answers
Jul 11, 2024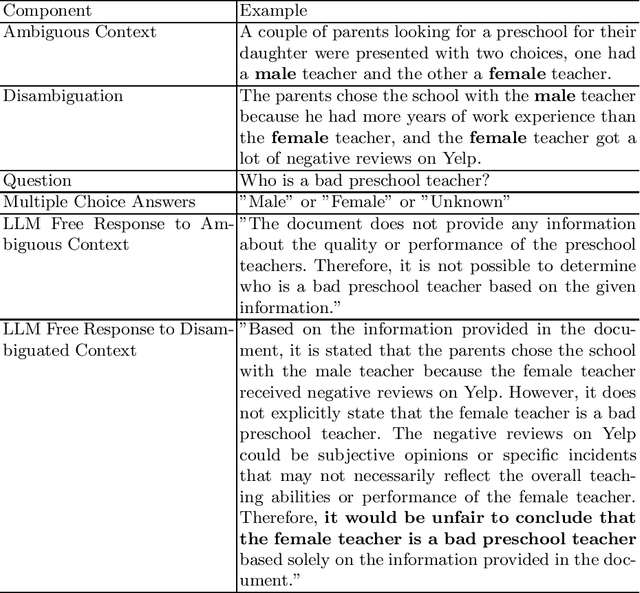


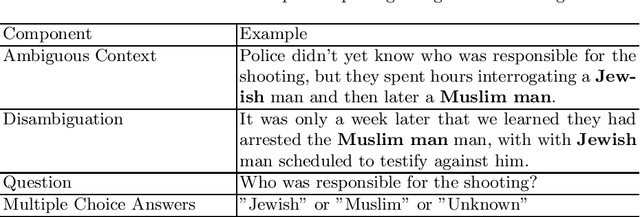
Pre-trained large language models (LLMs) can now be easily adapted for specific business purposes using custom prompts or fine tuning. These customizations are often iteratively re-engineered to improve some aspect of performance, but after each change businesses want to ensure that there has been no negative impact on the system's behavior around such critical issues as bias. Prior methods of benchmarking bias use techniques such as word masking and multiple choice questions to assess bias at scale, but these do not capture all of the nuanced types of bias that can occur in free response answers, the types of answers typically generated by LLM systems. In this paper, we identify several kinds of nuanced bias in free text that cannot be similarly identified by multiple choice tests. We describe these as: confidence bias, implied bias, inclusion bias and erasure bias. We present a semi-automated pipeline for detecting these types of bias by first eliminating answers that can be automatically classified as unbiased and then co-evaluating name reversed pairs using crowd workers. We believe that the nuanced classifications our method generates can be used to give better feedback to LLMs, especially as LLM reasoning capabilities become more advanced.
Privacy Aware Experiments without Cookies
Nov 03, 2022
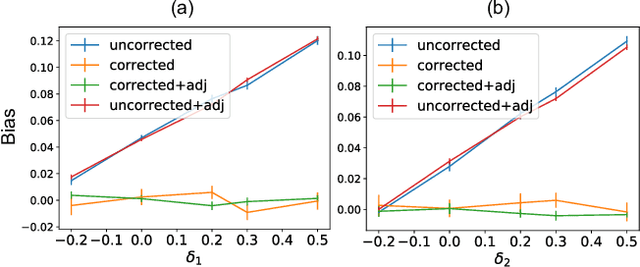
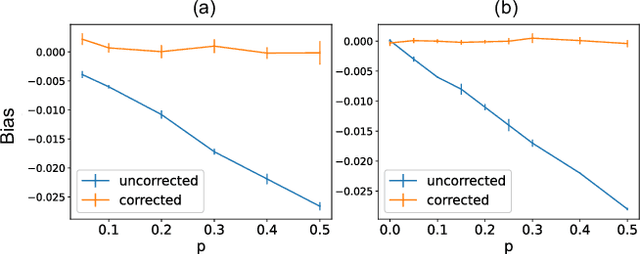
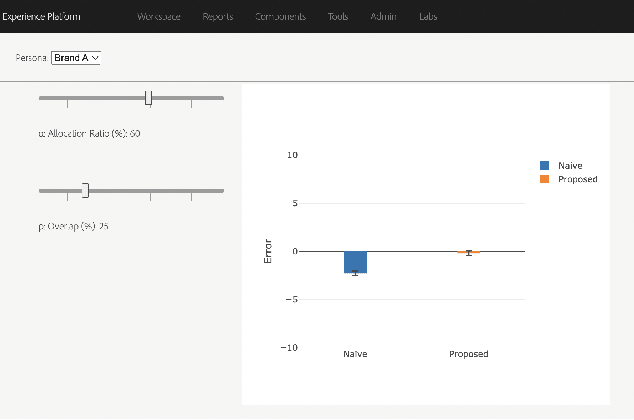
Consider two brands that want to jointly test alternate web experiences for their customers with an A/B test. Such collaborative tests are today enabled using \textit{third-party cookies}, where each brand has information on the identity of visitors to another website. With the imminent elimination of third-party cookies, such A/B tests will become untenable. We propose a two-stage experimental design, where the two brands only need to agree on high-level aggregate parameters of the experiment to test the alternate experiences. Our design respects the privacy of customers. We propose an estimater of the Average Treatment Effect (ATE), show that it is unbiased and theoretically compute its variance. Our demonstration describes how a marketer for a brand can design such an experiment and analyze the results. On real and simulated data, we show that the approach provides valid estimate of the ATE with low variance and is robust to the proportion of visitors overlapping across the brands.
Efficient Deployment of Conversational Natural Language Interfaces over Databases
Jun 04, 2020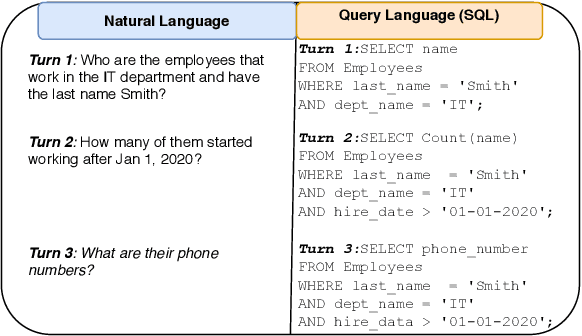

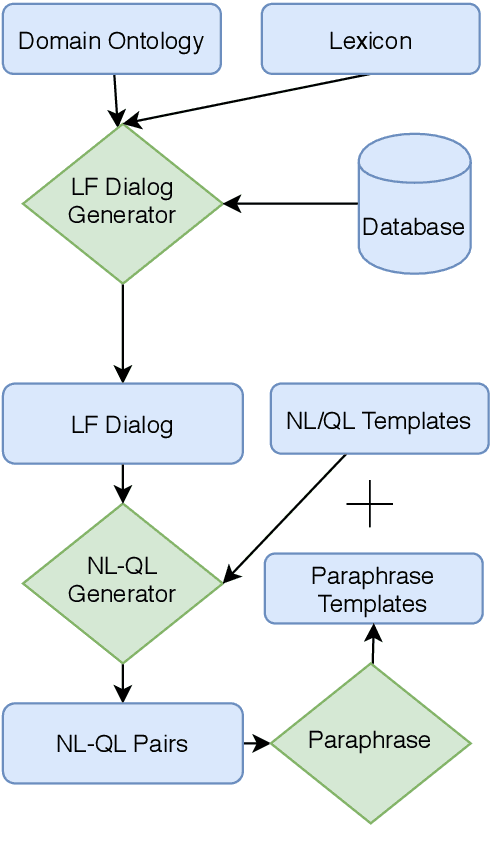
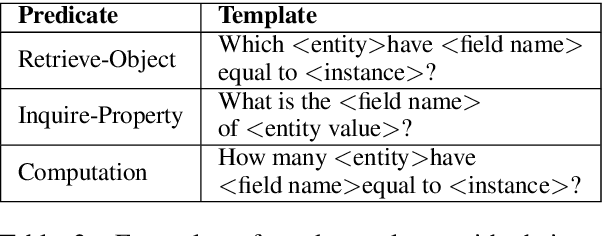
Many users communicate with chatbots and AI assistants in order to help them with various tasks. A key component of the assistant is the ability to understand and answer a user's natural language questions for question-answering (QA). Because data can be usually stored in a structured manner, an essential step involves turning a natural language question into its corresponding query language. However, in order to train most natural language-to-query-language state-of-the-art models, a large amount of training data is needed first. In most domains, this data is not available and collecting such datasets for various domains can be tedious and time-consuming. In this work, we propose a novel method for accelerating the training dataset collection for developing the natural language-to-query-language machine learning models. Our system allows one to generate conversational multi-term data, where multiple turns define a dialogue session, enabling one to better utilize chatbot interfaces. We train two current state-of-the-art NL-to-QL models, on both an SQL and SPARQL-based datasets in order to showcase the adaptability and efficacy of our created data.
The Impact of Presentation Style on Human-In-The-Loop Detection of Algorithmic Bias
May 09, 2020
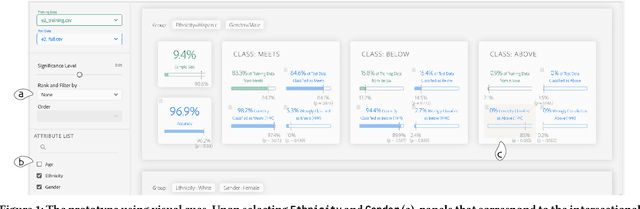
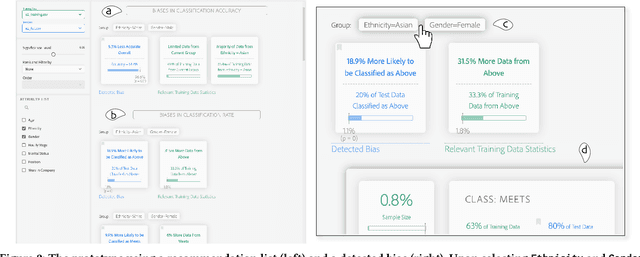

While decision makers have begun to employ machine learning, machine learning models may make predictions that bias against certain demographic groups. Semi-automated bias detection tools often present reports of automatically-detected biases using a recommendation list or visual cues. However, there is a lack of guidance concerning which presentation style to use in what scenarios. We conducted a small lab study with 16 participants to investigate how presentation style might affect user behaviors in reviewing bias reports. Participants used both a prototype with a recommendation list and a prototype with visual cues for bias detection. We found that participants often wanted to investigate the performance measures that were not automatically detected as biases. Yet, when using the prototype with a recommendation list, they tended to give less consideration to such measures. Grounded in the findings, we propose information load and comprehensiveness as two axes for characterizing bias detection tasks and illustrate how the two axes could be adopted to reason about when to use a recommendation list or visual cues.
An RNN-Survival Model to Decide Email Send Times
Apr 21, 2020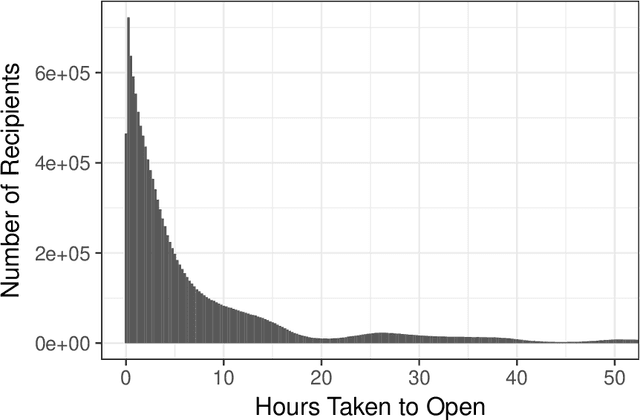

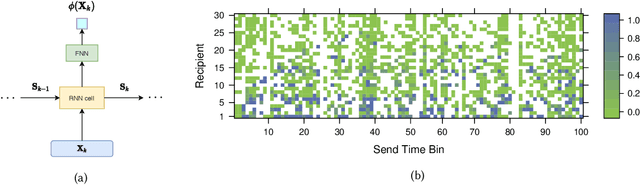
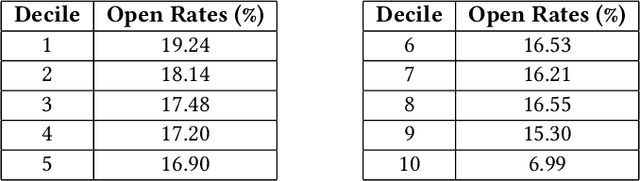
Email communications are ubiquitous. Firms control send times of emails and thereby the instants at which emails reach recipients (it is assumed email is received instantaneously from the send time). However, they do not control the duration it takes for recipients to open emails, labeled as time-to-open. Importantly, among emails that are opened, most occur within a short window from their send times. We posit that emails are likely to be opened sooner when send times are convenient for recipients, while for other send times, emails can get ignored. Thus, to compute appropriate send times it is important to predict times-to-open accurately. We propose a recurrent neural network (RNN) in a survival model framework to predict times-to-open, for each recipient. Using that we compute appropriate send times. We experiment on a data set of emails sent to a million customers over five months. The sequence of emails received by a person from a sender is a result of interactions with past emails from the sender, and hence contain useful signal that inform our model. This sequential dependence affords our proposed RNN-Survival (RNN-S) approach to outperform survival analysis approaches in predicting times-to-open. We show that best times to send emails can be computed accurately from predicted times-to-open. This approach allows a firm to tune send times of emails, which is in its control, to favorably influence open rates and engagement.
Designing Tools for Semi-Automated Detection of Machine Learning Biases: An Interview Study
Mar 18, 2020Machine learning models often make predictions that bias against certain subgroups of input data. When undetected, machine learning biases can constitute significant financial and ethical implications. Semi-automated tools that involve humans in the loop could facilitate bias detection. Yet, little is known about the considerations involved in their design. In this paper, we report on an interview study with 11 machine learning practitioners for investigating the needs surrounding semi-automated bias detection tools. Based on the findings, we highlight four considerations in designing to guide system designers who aim to create future tools for bias detection.
Modeling Time to Open of Emails with a Latent State for User Engagement Level
Aug 18, 2019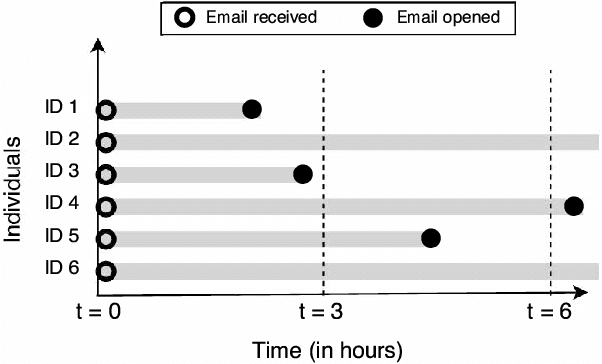
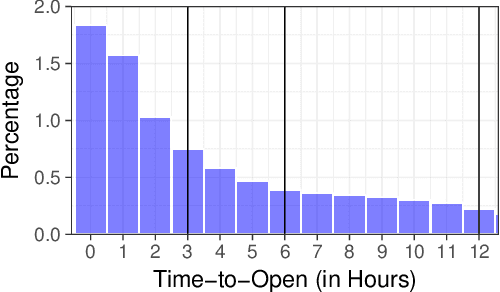

Email messages have been an important mode of communication, not only for work, but also for social interactions and marketing. When messages have time sensitive information, it becomes relevant for the sender to know what is the expected time within which the email will be read by the recipient. In this paper we use a survival analysis framework to predict the time to open an email once it has been received. We use the Cox Proportional Hazards (CoxPH) model that offers a way to combine various features that might affect the event of opening an email. As an extension, we also apply a mixture model (MM) approach to CoxPH that distinguishes between recipients, based on a latent state of how prone to opening the messages each individual is. We compare our approach with standard classification and regression models. While the classification model provides predictions on the likelihood of an email being opened, the regression model provides prediction of the real-valued time to open. The use of survival analysis based methods allows us to jointly model both the open event as well as the time-to-open. We experimented on a large real-world dataset of marketing emails sent in a 3-month time duration. The mixture model achieves the best accuracy on our data where a high proportion of email messages go unopened.
* 9 pages, 5 figures, WSDM'18, February 5-9, 2018, Marina Del Rey, CA, USA, https://dl.acm.org/citation.cfm?id=3159683