 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtom: Efficient On-Device Video-Language Pipelines Through Modular Reuse
Dec 18, 2025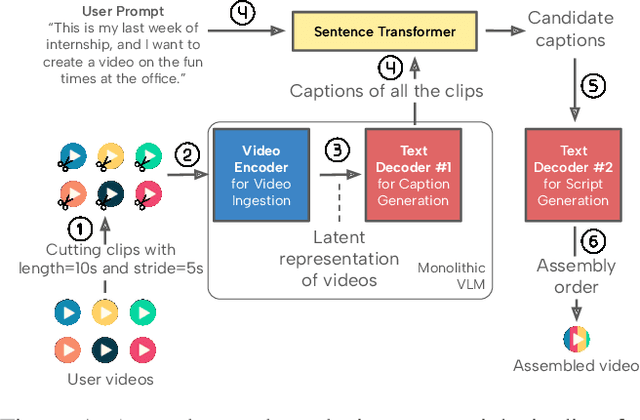
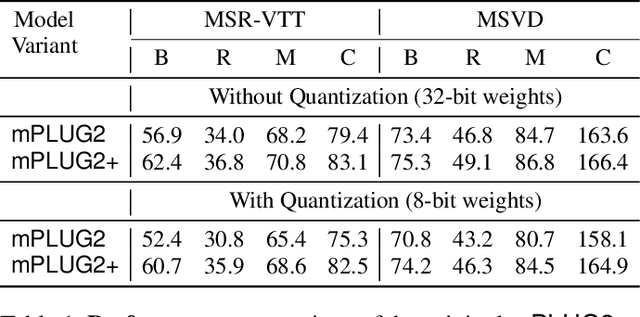
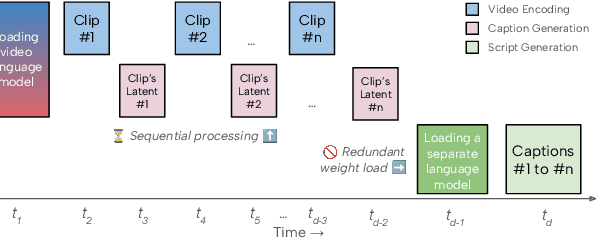
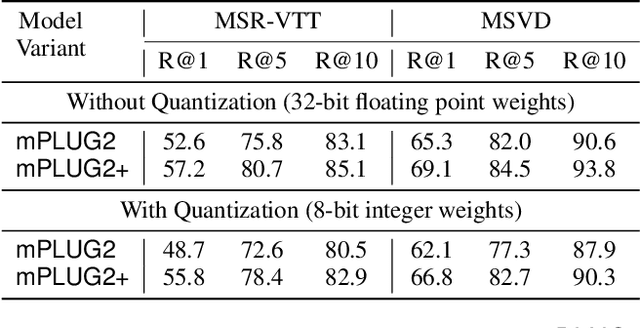
Recent advances in video-language models have enabled powerful applications like video retrieval, captioning, and assembly. However, executing such multi-stage pipelines efficiently on mobile devices remains challenging due to redundant model loads and fragmented execution. We introduce Atom, an on-device system that restructures video-language pipelines for fast and efficient execution. Atom decomposes a billion-parameter model into reusable modules, such as the visual encoder and language decoder, and reuses them across subtasks like captioning, reasoning, and indexing. This reuse-centric design eliminates repeated model loading and enables parallel execution, reducing end-to-end latency without sacrificing performance. On commodity smartphones, Atom achieves 27--33% faster execution compared to non-reuse baselines, with only marginal performance drop ($\leq$ 2.3 Recall@1 in retrieval, $\leq$ 1.5 CIDEr in captioning). These results position Atom as a practical, scalable approach for efficient video-language understanding on edge devices.
Mitigating Forgetting Between Supervised and Reinforcement Learning Yields Stronger Reasoners
Oct 06, 2025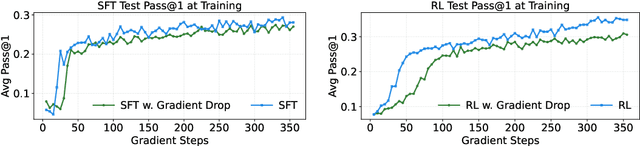
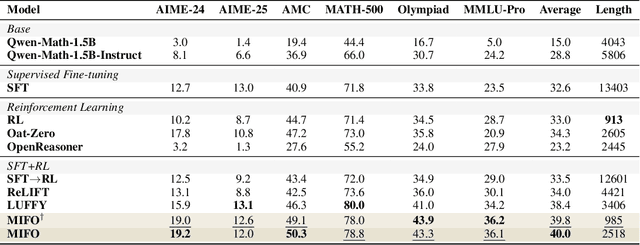
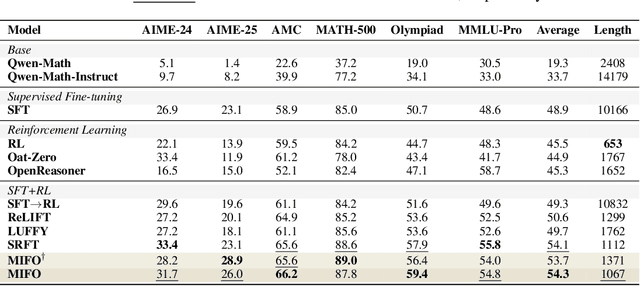

Large Language Models (LLMs) show strong reasoning abilities, often amplified by Chain-of-Thought (CoT) prompting and reinforcement learning (RL). Although RL algorithms can substantially improve reasoning, they struggle to expand reasoning boundaries because they learn from their own reasoning trajectories rather than acquiring external knowledge. Supervised fine-tuning (SFT) offers complementary benefits but typically requires large-scale data and risks overfitting. Recent attempts to combine SFT and RL face three main challenges: data inefficiency, algorithm-specific designs, and catastrophic forgetting. We propose a plug-and-play framework that dynamically integrates SFT into RL by selecting challenging examples for SFT. This approach reduces SFT data requirements and remains agnostic to the choice of RL or SFT algorithm. To mitigate catastrophic forgetting of RL-acquired skills during SFT, we select high-entropy tokens for loss calculation and freeze parameters identified as critical for RL. Our method achieves state-of-the-art (SoTA) reasoning performance using only 1.5% of the SFT data and 20.4% of the RL data used by prior SoTA, providing an efficient and plug-and-play solution for combining SFT and RL in reasoning post-training.
Shape My Moves: Text-Driven Shape-Aware Synthesis of Human Motions
Apr 04, 2025



We explore how body shapes influence human motion synthesis, an aspect often overlooked in existing text-to-motion generation methods due to the ease of learning a homogenized, canonical body shape. However, this homogenization can distort the natural correlations between different body shapes and their motion dynamics. Our method addresses this gap by generating body-shape-aware human motions from natural language prompts. We utilize a finite scalar quantization-based variational autoencoder (FSQ-VAE) to quantize motion into discrete tokens and then leverage continuous body shape information to de-quantize these tokens back into continuous, detailed motion. Additionally, we harness the capabilities of a pretrained language model to predict both continuous shape parameters and motion tokens, facilitating the synthesis of text-aligned motions and decoding them into shape-aware motions. We evaluate our method quantitatively and qualitatively, and also conduct a comprehensive perceptual study to demonstrate its efficacy in generating shape-aware motions.
SKALD: Learning-Based Shot Assembly for Coherent Multi-Shot Video Creation
Mar 11, 2025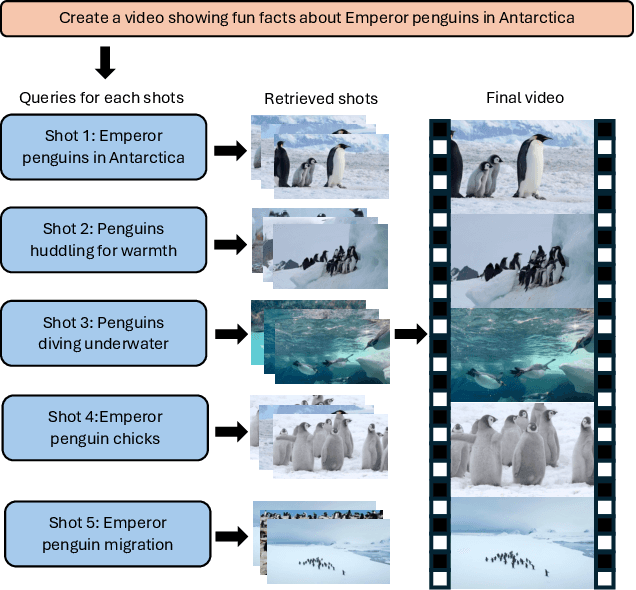
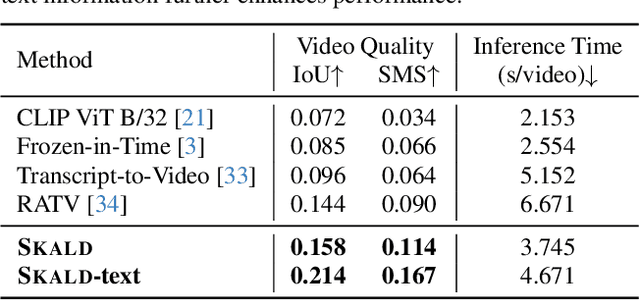

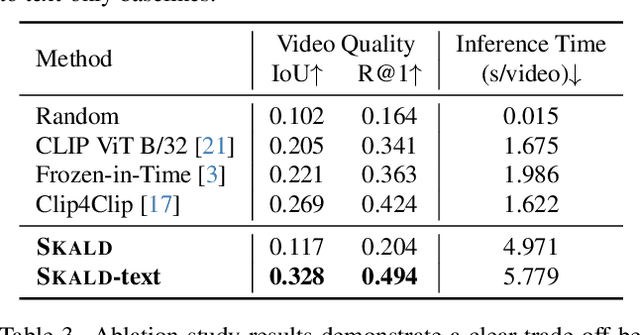
We present SKALD, a multi-shot video assembly method that constructs coherent video sequences from candidate shots with minimal reliance on text. Central to our approach is the Learned Clip Assembly (LCA) score, a learning-based metric that measures temporal and semantic relationships between shots to quantify narrative coherence. We tackle the exponential complexity of combining multiple shots with an efficient beam-search algorithm guided by the LCA score. To train our model effectively with limited human annotations, we propose two tasks for the LCA encoder: Shot Coherence Learning, which uses contrastive learning to distinguish coherent and incoherent sequences, and Feature Regression, which converts these learned representations into a real-valued coherence score. We develop two variants: a base SKALD model that relies solely on visual coherence and SKALD-text, which integrates auxiliary text information when available. Experiments on the VSPD and our curated MSV3C datasets show that SKALD achieves an improvement of up to 48.6% in IoU and a 43% speedup over the state-of-the-art methods. A user study further validates our approach, with 45% of participants favoring SKALD-assembled videos, compared to 22% preferring text-based assembly methods.
CodeLutra: Boosting LLM Code Generation via Preference-Guided Refinement
Nov 07, 2024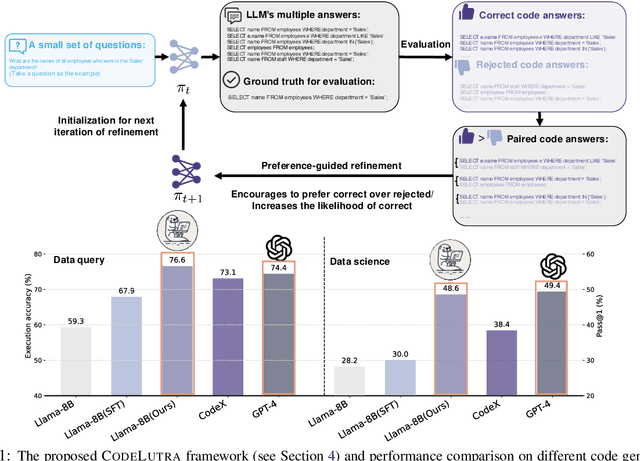



Large Language Models (LLMs) have significantly advanced code generation but often require substantial resources and tend to over-generalize, limiting their efficiency for specific tasks. Fine-tuning smaller, open-source LLMs presents a viable alternative; however, it typically lags behind cutting-edge models due to supervised fine-tuning's reliance solely on correct code examples, which restricts the model's ability to learn from its own mistakes and adapt to diverse programming challenges. To bridge this gap, we introduce CodeLutra, a novel framework that enhances low-performing LLMs by leveraging both successful and failed code generation attempts. Unlike conventional fine-tuning, CodeLutra employs an iterative preference learning mechanism to compare correct and incorrect solutions as well as maximize the likelihood of correct codes. Through continuous iterative refinement, CodeLutra enables smaller LLMs to match or surpass GPT-4's performance in various code generation tasks without relying on vast external datasets or larger auxiliary models. On a challenging data analysis task, using just 500 samples improved Llama-3-8B's accuracy from 28.2% to 48.6%, approaching GPT-4's performance. These results highlight CodeLutra's potential to close the gap between open-source and closed-source models, making it a promising approach in the field of code generation.
A/B testing under Interference with Partial Network Information
Apr 16, 2024



A/B tests are often required to be conducted on subjects that might have social connections. For e.g., experiments on social media, or medical and social interventions to control the spread of an epidemic. In such settings, the SUTVA assumption for randomized-controlled trials is violated due to network interference, or spill-over effects, as treatments to group A can potentially also affect the control group B. When the underlying social network is known exactly, prior works have demonstrated how to conduct A/B tests adequately to estimate the global average treatment effect (GATE). However, in practice, it is often impossible to obtain knowledge about the exact underlying network. In this paper, we present UNITE: a novel estimator that relax this assumption and can identify GATE while only relying on knowledge of the superset of neighbors for any subject in the graph. Through theoretical analysis and extensive experiments, we show that the proposed approach performs better in comparison to standard estimators.
HanDiffuser: Text-to-Image Generation With Realistic Hand Appearances
Mar 04, 2024



Text-to-image generative models can generate high-quality humans, but realism is lost when generating hands. Common artifacts include irregular hand poses, shapes, incorrect numbers of fingers, and physically implausible finger orientations. To generate images with realistic hands, we propose a novel diffusion-based architecture called HanDiffuser that achieves realism by injecting hand embeddings in the generative process. HanDiffuser consists of two components: a Text-to-Hand-Params diffusion model to generate SMPL-Body and MANO-Hand parameters from input text prompts, and a Text-Guided Hand-Params-to-Image diffusion model to synthesize images by conditioning on the prompts and hand parameters generated by the previous component. We incorporate multiple aspects of hand representation, including 3D shapes and joint-level finger positions, orientations and articulations, for robust learning and reliable performance during inference. We conduct extensive quantitative and qualitative experiments and perform user studies to demonstrate the efficacy of our method in generating images with high-quality hands.
SODA: Protecting Proprietary Information in On-Device Machine Learning Models
Dec 22, 2023The growth of low-end hardware has led to a proliferation of machine learning-based services in edge applications. These applications gather contextual information about users and provide some services, such as personalized offers, through a machine learning (ML) model. A growing practice has been to deploy such ML models on the user's device to reduce latency, maintain user privacy, and minimize continuous reliance on a centralized source. However, deploying ML models on the user's edge device can leak proprietary information about the service provider. In this work, we investigate on-device ML models that are used to provide mobile services and demonstrate how simple attacks can leak proprietary information of the service provider. We show that different adversaries can easily exploit such models to maximize their profit and accomplish content theft. Motivated by the need to thwart such attacks, we present an end-to-end framework, SODA, for deploying and serving on edge devices while defending against adversarial usage. Our results demonstrate that SODA can detect adversarial usage with 89% accuracy in less than 50 queries with minimal impact on service performance, latency, and storage.
Token-Level Adversarial Prompt Detection Based on Perplexity Measures and Contextual Information
Nov 27, 2023In recent years, Large Language Models (LLM) have emerged as pivotal tools in various applications. However, these models are susceptible to adversarial prompt attacks, where attackers can carefully curate input strings that lead to undesirable outputs. The inherent vulnerability of LLMs stems from their input-output mechanisms, especially when presented with intensely out-of-distribution (OOD) inputs. This paper proposes a token-level detection method to identify adversarial prompts, leveraging the LLM's capability to predict the next token's probability. We measure the degree of the model's perplexity and incorporate neighboring token information to encourage the detection of contiguous adversarial prompt sequences. As a result, we propose two methods: one that identifies each token as either being part of an adversarial prompt or not, and another that estimates the probability of each token being part of an adversarial prompt.
Fast Heavy Inner Product Identification Between Weights and Inputs in Neural Network Training
Nov 19, 2023
In this paper, we consider a heavy inner product identification problem, which generalizes the Light Bulb problem~(\cite{prr89}): Given two sets $A \subset \{-1,+1\}^d$ and $B \subset \{-1,+1\}^d$ with $|A|=|B| = n$, if there are exact $k$ pairs whose inner product passes a certain threshold, i.e., $\{(a_1, b_1), \cdots, (a_k, b_k)\} \subset A \times B$ such that $\forall i \in [k], \langle a_i,b_i \rangle \geq \rho \cdot d$, for a threshold $\rho \in (0,1)$, the goal is to identify those $k$ heavy inner products. We provide an algorithm that runs in $O(n^{2 \omega / 3+ o(1)})$ time to find the $k$ inner product pairs that surpass $\rho \cdot d$ threshold with high probability, where $\omega$ is the current matrix multiplication exponent. By solving this problem, our method speed up the training of neural networks with ReLU activation function.