 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Diffusion Models and 3D Representations: A 3D Consistent Super-Resolution Framework
Aug 06, 2025We propose 3D Super Resolution (3DSR), a novel 3D Gaussian-splatting-based super-resolution framework that leverages off-the-shelf diffusion-based 2D super-resolution models. 3DSR encourages 3D consistency across views via the use of an explicit 3D Gaussian-splatting-based scene representation. This makes the proposed 3DSR different from prior work, such as image upsampling or the use of video super-resolution, which either don't consider 3D consistency or aim to incorporate 3D consistency implicitly. Notably, our method enhances visual quality without additional fine-tuning, ensuring spatial coherence within the reconstructed scene. We evaluate 3DSR on MipNeRF360 and LLFF data, demonstrating that it produces high-resolution results that are visually compelling, while maintaining structural consistency in 3D reconstructions. Code will be released.
Shape My Moves: Text-Driven Shape-Aware Synthesis of Human Motions
Apr 04, 2025



We explore how body shapes influence human motion synthesis, an aspect often overlooked in existing text-to-motion generation methods due to the ease of learning a homogenized, canonical body shape. However, this homogenization can distort the natural correlations between different body shapes and their motion dynamics. Our method addresses this gap by generating body-shape-aware human motions from natural language prompts. We utilize a finite scalar quantization-based variational autoencoder (FSQ-VAE) to quantize motion into discrete tokens and then leverage continuous body shape information to de-quantize these tokens back into continuous, detailed motion. Additionally, we harness the capabilities of a pretrained language model to predict both continuous shape parameters and motion tokens, facilitating the synthesis of text-aligned motions and decoding them into shape-aware motions. We evaluate our method quantitatively and qualitatively, and also conduct a comprehensive perceptual study to demonstrate its efficacy in generating shape-aware motions.
VividDream: Generating 3D Scene with Ambient Dynamics
May 30, 2024We introduce VividDream, a method for generating explorable 4D scenes with ambient dynamics from a single input image or text prompt. VividDream first expands an input image into a static 3D point cloud through iterative inpainting and geometry merging. An ensemble of animated videos is then generated using video diffusion models with quality refinement techniques and conditioned on renderings of the static 3D scene from the sampled camera trajectories. We then optimize a canonical 4D scene representation using an animated video ensemble, with per-video motion embeddings and visibility masks to mitigate inconsistencies. The resulting 4D scene enables free-view exploration of a 3D scene with plausible ambient scene dynamics. Experiments demonstrate that VividDream can provide human viewers with compelling 4D experiences generated based on diverse real images and text prompts.
Text-driven Visual Synthesis with Latent Diffusion Prior
Feb 16, 2023



There has been tremendous progress in large-scale text-to-image synthesis driven by diffusion models enabling versatile downstream applications such as 3D object synthesis from texts, image editing, and customized generation. We present a generic approach using latent diffusion models as powerful image priors for various visual synthesis tasks. Existing methods that utilize such priors fail to use these models' full capabilities. To improve this, our core ideas are 1) a feature matching loss between features from different layers of the decoder to provide detailed guidance and 2) a KL divergence loss to regularize the predicted latent features and stabilize the training. We demonstrate the efficacy of our approach on three different applications, text-to-3D, StyleGAN adaptation, and layered image editing. Extensive results show our method compares favorably against baselines.
ELDA: Using Edges to Have an Edge on Semantic Segmentation Based UDA
Nov 16, 2022



Many unsupervised domain adaptation (UDA) methods have been proposed to bridge the domain gap by utilizing domain invariant information. Most approaches have chosen depth as such information and achieved remarkable success. Despite their effectiveness, using depth as domain invariant information in UDA tasks may lead to multiple issues, such as excessively high extraction costs and difficulties in achieving a reliable prediction quality. As a result, we introduce Edge Learning based Domain Adaptation (ELDA), a framework which incorporates edge information into its training process to serve as a type of domain invariant information. In our experiments, we quantitatively and qualitatively demonstrate that the incorporation of edge information is indeed beneficial and effective and enables ELDA to outperform the contemporary state-of-the-art methods on two commonly adopted benchmarks for semantic segmentation based UDA tasks. In addition, we show that ELDA is able to better separate the feature distributions of different classes. We further provide an ablation analysis to justify our design decisions.
Pixel-Wise Prediction based Visual Odometry via Uncertainty Estimation
Aug 18, 2022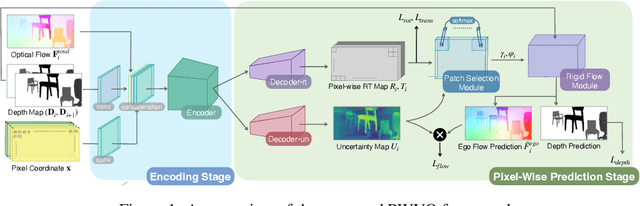

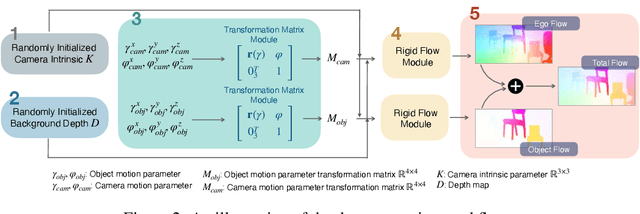
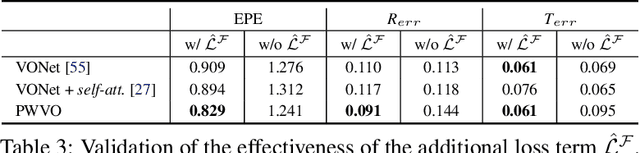
This paper introduces pixel-wise prediction based visual odometry (PWVO), which is a dense prediction task that evaluates the values of translation and rotation for every pixel in its input observations. PWVO employs uncertainty estimation to identify the noisy regions in the input observations, and adopts a selection mechanism to integrate pixel-wise predictions based on the estimated uncertainty maps to derive the final translation and rotation. In order to train PWVO in a comprehensive fashion, we further develop a data generation workflow for generating synthetic training data. The experimental results show that PWVO is able to deliver favorable results. In addition, our analyses validate the effectiveness of the designs adopted in PWVO, and demonstrate that the uncertainty maps estimated by PWVO is capable of capturing the noises in its input observations.
Investigation of Factorized Optical Flows as Mid-Level Representations
Mar 10, 2022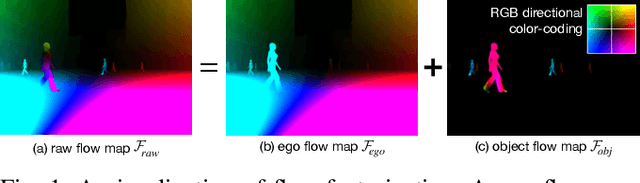
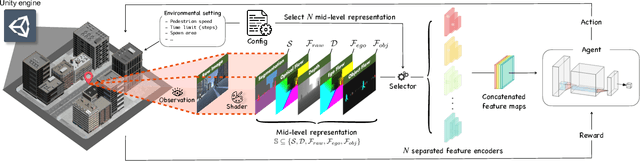
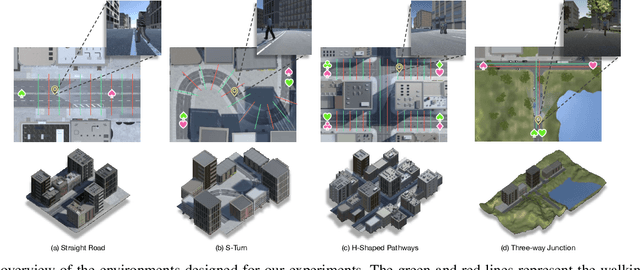
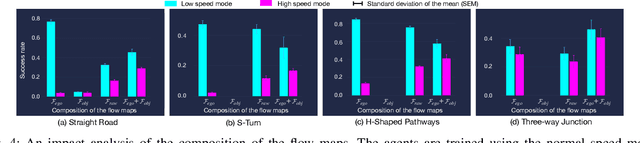
In this paper, we introduce a new concept of incorporating factorized flow maps as mid-level representations, for bridging the perception and the control modules in modular learning based robotic frameworks. To investigate the advantages of factorized flow maps and examine their interplay with the other types of mid-level representations, we further develop a configurable framework, along with four different environments that contain both static and dynamic objects, for analyzing the impacts of factorized optical flow maps on the performance of deep reinforcement learning agents. Based on this framework, we report our experimental results on various scenarios, and offer a set of analyses to justify our hypothesis. Finally, we validate flow factorization in real world scenarios.