 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELDA: Using Edges to Have an Edge on Semantic Segmentation Based UDA
Nov 16, 2022



Many unsupervised domain adaptation (UDA) methods have been proposed to bridge the domain gap by utilizing domain invariant information. Most approaches have chosen depth as such information and achieved remarkable success. Despite their effectiveness, using depth as domain invariant information in UDA tasks may lead to multiple issues, such as excessively high extraction costs and difficulties in achieving a reliable prediction quality. As a result, we introduce Edge Learning based Domain Adaptation (ELDA), a framework which incorporates edge information into its training process to serve as a type of domain invariant information. In our experiments, we quantitatively and qualitatively demonstrate that the incorporation of edge information is indeed beneficial and effective and enables ELDA to outperform the contemporary state-of-the-art methods on two commonly adopted benchmarks for semantic segmentation based UDA tasks. In addition, we show that ELDA is able to better separate the feature distributions of different classes. We further provide an ablation analysis to justify our design decisions.
Quasi-Conservative Score-based Generative Models
Sep 26, 2022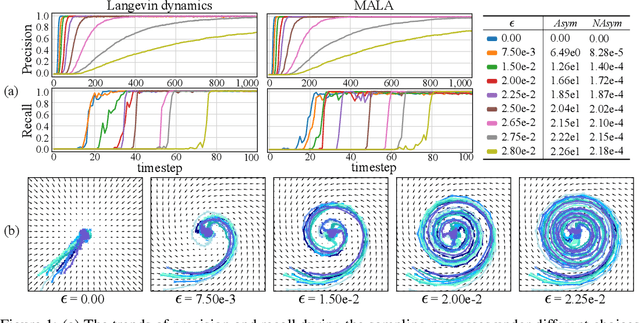
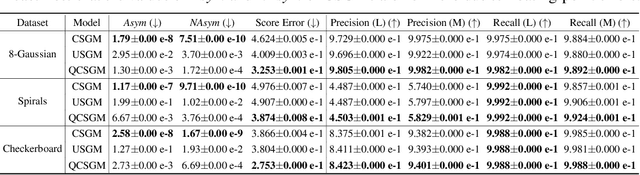
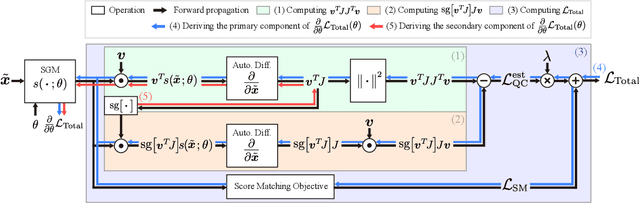
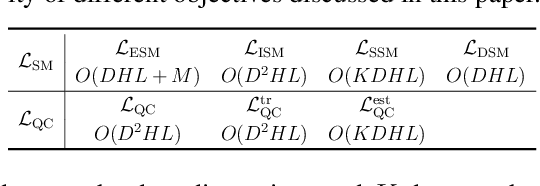
Existing Score-based Generative Models (SGMs) can be categorized into constrained SGMs (CSGMs) or unconstrained SGMs (USGMs) according to their parameterization approaches. CSGMs model the probability density functions as Boltzmann distributions, and assign their predictions as the negative gradients of some scalar-valued energy functions. On the other hand, USGMs employ flexible architectures capable of directly estimating scores without the need to explicitly model energy functions. In this paper, we demonstrate that the architectural constraints of CSGMs may limit their score-matching ability. In addition, we show that USGMs' inability to preserve the property of conservativeness may lead to serious sampling inefficiency and degraded sampling performance in practice. To address the above issues, we propose Quasi-Conservative Score-based Generative Models (QCSGMs) for keeping the advantages of both CSGMs and USGMs. Our theoretical derivations demonstrate that the training objective of QCSGMs can be efficiently integrated into the training processes by leveraging the Hutchinson trace estimator. In addition, our experimental results on the Cifar-10, Cifar-100, ImageNet, and SVHN datasets validate the effectiveness of QCSGMs. Finally, we justify the advantage of QCSGMs using an example of a one-layered autoencoder.
Denoising Likelihood Score Matching for Conditional Score-based Data Generation
Mar 27, 2022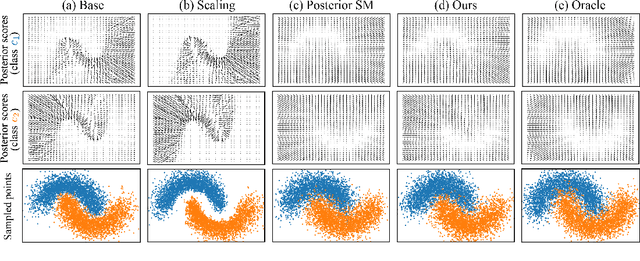
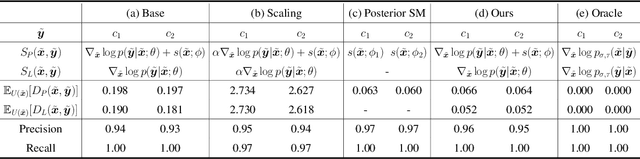

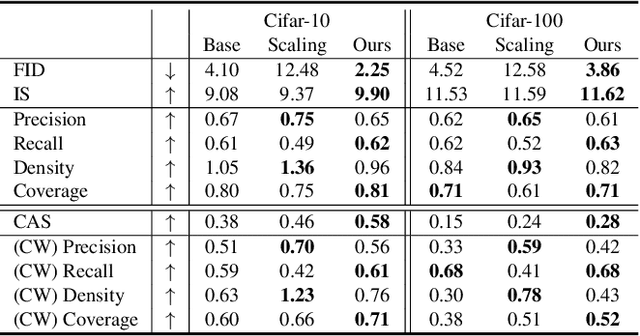
Many existing conditional score-based data generation methods utilize Bayes' theorem to decompose the gradients of a log posterior density into a mixture of scores. These methods facilitate the training procedure of conditional score models, as a mixture of scores can be separately estimated using a score model and a classifier. However, our analysis indicates that the training objectives for the classifier in these methods may lead to a serious score mismatch issue, which corresponds to the situation that the estimated scores deviate from the true ones. Such an issue causes the samples to be misled by the deviated scores during the diffusion process, resulting in a degraded sampling quality. To resolve it, we formulate a novel training objective, called Denoising Likelihood Score Matching (DLSM) loss, for the classifier to match the gradients of the true log likelihood density. Our experimental evidence shows that the proposed method outperforms the previous methods on both Cifar-10 and Cifar-100 benchmarks noticeably in terms of several key evaluation metrics. We thus conclude that, by adopting DLSM, the conditional scores can be accurately modeled, and the effect of the score mismatch issue is alleviated.
Rethinking Ensemble-Distillation for Semantic Segmentation Based Unsupervised Domain Adaptation
Apr 29, 2021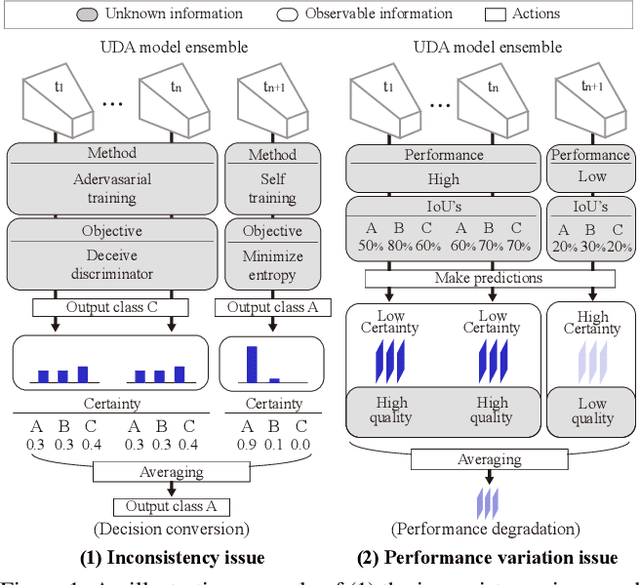
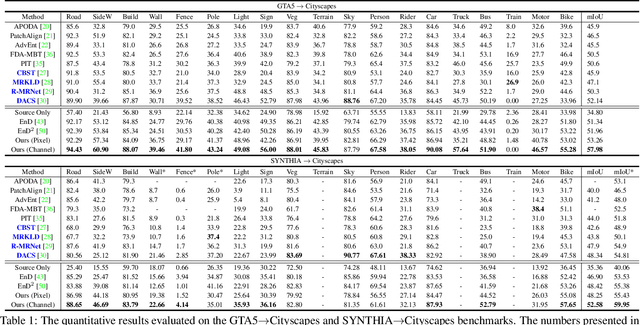
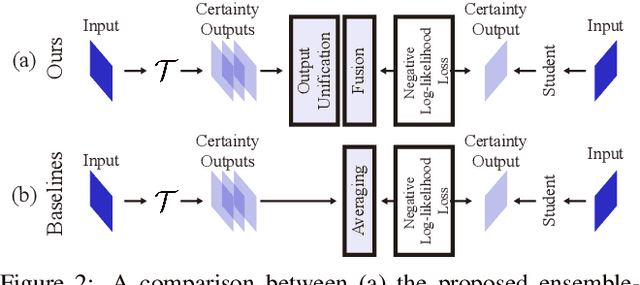
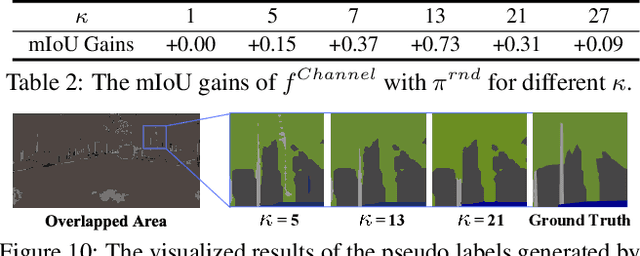
Recent researches on unsupervised domain adaptation (UDA) have demonstrated that end-to-end ensemble learning frameworks serve as a compelling option for UDA tasks. Nevertheless, these end-to-end ensemble learning methods often lack flexibility as any modification to the ensemble requires retraining of their frameworks. To address this problem, we propose a flexible ensemble-distillation framework for performing semantic segmentation based UDA, allowing any arbitrary composition of the members in the ensemble while still maintaining its superior performance. To achieve such flexibility, our framework is designed to be robust against the output inconsistency and the performance variation of the members within the ensemble. To examine the effectiveness and the robustness of our method, we perform an extensive set of experiments on both GTA5 to Cityscapes and SYNTHIA to Cityscapes benchmarks to quantitatively inspect the improvements achievable by our method. We further provide detailed analyses to validate that our design choices are practical and beneficial. The experimental evidence validates that the proposed method indeed offer superior performance, robustness and flexibility in semantic segmentation based UDA tasks against contemporary baseline methods.