 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDM-Prime-v2: Binary Encoding and Index Shuffling Enable Compute-optimal Scaling of Diffusion Language Models
Mar 17, 2026Masked diffusion models (MDM) exhibit superior generalization when learned using a Partial masking scheme (Prime). This approach converts tokens into sub-tokens and models the diffusion process at the sub-token level. We identify two limitations of the MDM-Prime framework. First, we lack tools to guide the hyperparameter choice of the token granularity in the subtokenizer. Second, we find that the function form of the subtokenizer significantly degrades likelihood estimation when paired with commonly used Byte-Pair-Encoding (BPE) tokenizers. To address these limitations, we study the tightness of the variational bound in MDM-Prime and develop MDM-Prime-v2, a masked diffusion language model which incorporates Binary Encoding and Index Shuffling. Our scaling analysis reveals that MDM-Prime-v2 is 21.8$\times$ more compute-efficient than autoregressive models (ARM). In compute-optimal comparisons, MDM-Prime-v2 achieves 7.77 perplexity on OpenWebText, outperforming ARM (12.99), MDM (18.94), and MDM-Prime (13.41). When extending the model size to 1.1B parameters, our model further demonstrates superior zero-shot accuracy on various commonsense reasoning tasks.
LOBE-GS: Load-Balanced and Efficient 3D Gaussian Splatting for Large-Scale Scene Reconstruction
Oct 02, 20253D Gaussian Splatting (3DGS) has established itself as an efficient representation for real-time, high-fidelity 3D scene reconstruction. However, scaling 3DGS to large and unbounded scenes such as city blocks remains difficult. Existing divide-and-conquer methods alleviate memory pressure by partitioning the scene into blocks, but introduce new bottlenecks: (i) partitions suffer from severe load imbalance since uniform or heuristic splits do not reflect actual computational demands, and (ii) coarse-to-fine pipelines fail to exploit the coarse stage efficiently, often reloading the entire model and incurring high overhead. In this work, we introduce LoBE-GS, a novel Load-Balanced and Efficient 3D Gaussian Splatting framework, that re-engineers the large-scale 3DGS pipeline. LoBE-GS introduces a depth-aware partitioning method that reduces preprocessing from hours to minutes, an optimization-based strategy that balances visible Gaussians -- a strong proxy for computational load -- across blocks, and two lightweight techniques, visibility cropping and selective densification, to further reduce training cost. Evaluations on large-scale urban and outdoor datasets show that LoBE-GS consistently achieves up to $2\times$ faster end-to-end training time than state-of-the-art baselines, while maintaining reconstruction quality and enabling scalability to scenes infeasible with vanilla 3DGS.
Beyond Masked and Unmasked: Discrete Diffusion Models via Partial Masking
May 24, 2025Masked diffusion models (MDM) are powerful generative models for discrete data that generate samples by progressively unmasking tokens in a sequence. Each token can take one of two states: masked or unmasked. We observe that token sequences often remain unchanged between consecutive sampling steps; consequently, the model repeatedly processes identical inputs, leading to redundant computation. To address this inefficiency, we propose the Partial masking scheme (Prime), which augments MDM by allowing tokens to take intermediate states interpolated between the masked and unmasked states. This design enables the model to make predictions based on partially observed token information, and facilitates a fine-grained denoising process. We derive a variational training objective and introduce a simple architectural design to accommodate intermediate-state inputs. Our method demonstrates superior performance across a diverse set of generative modeling tasks. On text data, it achieves a perplexity of 15.36 on OpenWebText, outperforming previous MDM (21.52), autoregressive models (17.54), and their hybrid variants (17.58), without relying on an autoregressive formulation. On image data, it attains competitive FID scores of 3.26 on CIFAR-10 and 6.98 on ImageNet-32, comparable to leading continuous generative models.
Retraining-Free Merging of Sparse Mixture-of-Experts via Hierarchical Clustering
Oct 11, 2024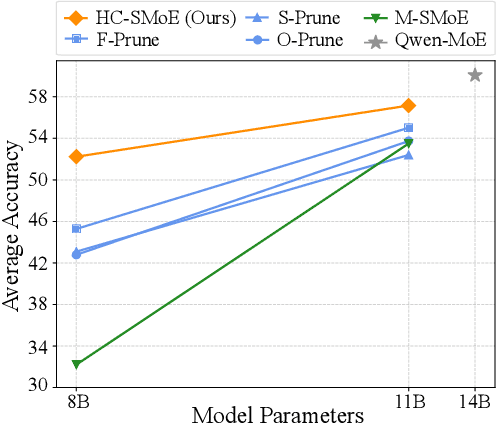

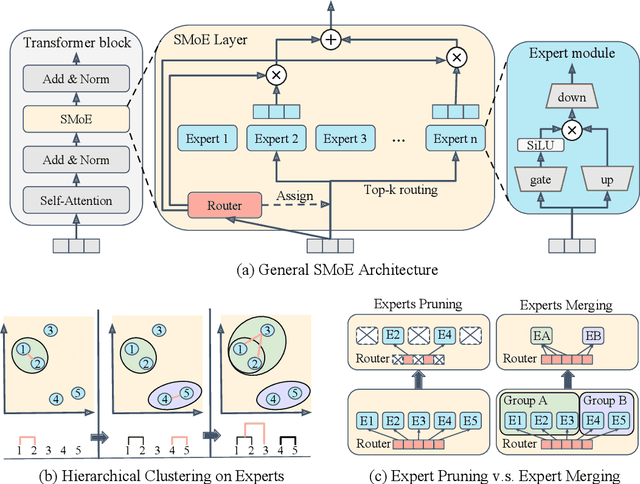
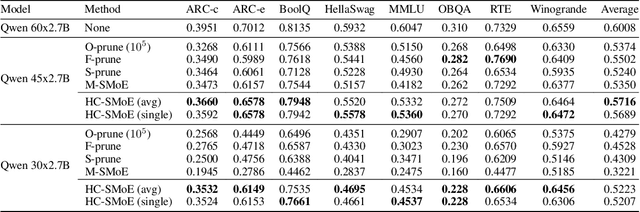
Sparse Mixture-of-Experts (SMoE) models represent a significant breakthrough in large language model development. These models enable performance improvements without a proportional increase in inference costs. By selectively activating a small set of parameters during task execution, SMoEs enhance model capacity. However, their deployment remains challenging due to the substantial memory footprint required to accommodate the growing number of experts. This constraint renders them less feasible in environments with limited hardware resources. To address this challenge, we propose Hierarchical Clustering for Sparsely activated Mixture of Experts (HC-SMoE), a task-agnostic expert merging framework that reduces SMoE model parameters without retraining. Unlike previous methods, HC-SMoE employs hierarchical clustering based on expert outputs. This approach ensures that the merging process remains unaffected by routing decisions. The output-based clustering strategy captures functional similarities between experts, offering an adaptable solution for models with numerous experts. We validate our approach through extensive experiments on eight zero-shot language tasks and demonstrate its effectiveness in large-scale SMoE models such as Qwen and Mixtral. Our comprehensive results demonstrate that HC-SMoE consistently achieves strong performance, which highlights its potential for real-world deployment.
Maximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow
May 22, 2024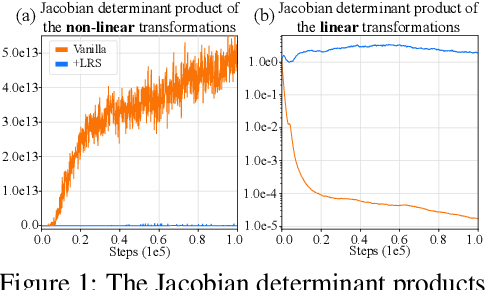
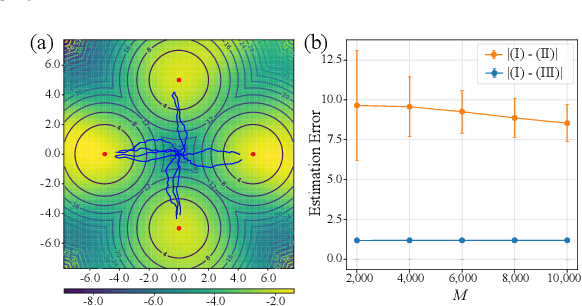
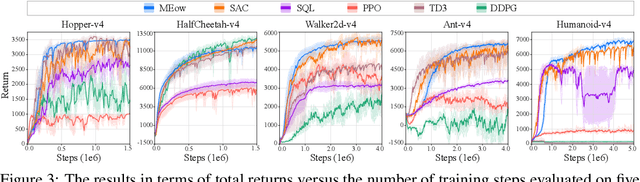
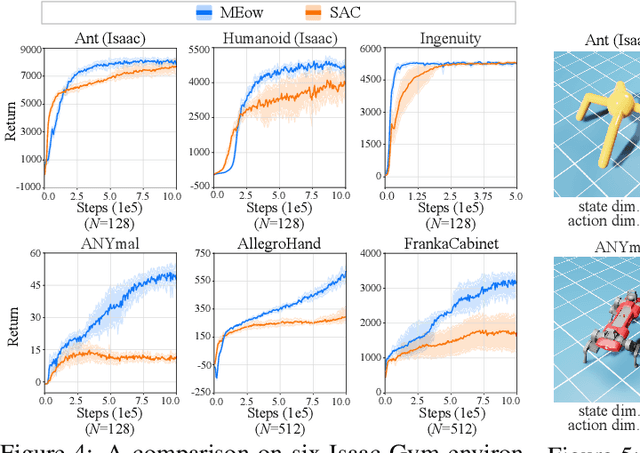
Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
DriveEnv-NeRF: Exploration of A NeRF-Based Autonomous Driving Environment for Real-World Performance Validation
Mar 23, 2024
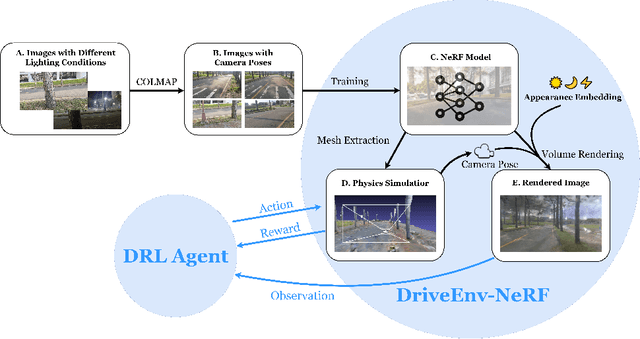


In this study, we introduce the DriveEnv-NeRF framework, which leverages Neural Radiance Fields (NeRF) to enable the validation and faithful forecasting of the efficacy of autonomous driving agents in a targeted real-world scene. Standard simulator-based rendering often fails to accurately reflect real-world performance due to the sim-to-real gap, which represents the disparity between virtual simulations and real-world conditions. To mitigate this gap, we propose a workflow for building a high-fidelity simulation environment of the targeted real-world scene using NeRF. This approach is capable of rendering realistic images from novel viewpoints and constructing 3D meshes for emulating collisions. The validation of these capabilities through the comparison of success rates in both simulated and real environments demonstrates the benefits of using DriveEnv-NeRF as a real-world performance indicator. Furthermore, the DriveEnv-NeRF framework can serve as a training environment for autonomous driving agents under various lighting conditions. This approach enhances the robustness of the agents and reduces performance degradation when deployed to the target real scene, compared to agents fully trained using the standard simulator rendering pipeline.
Expert Proximity as Surrogate Rewards for Single Demonstration Imitation Learning
Feb 01, 2024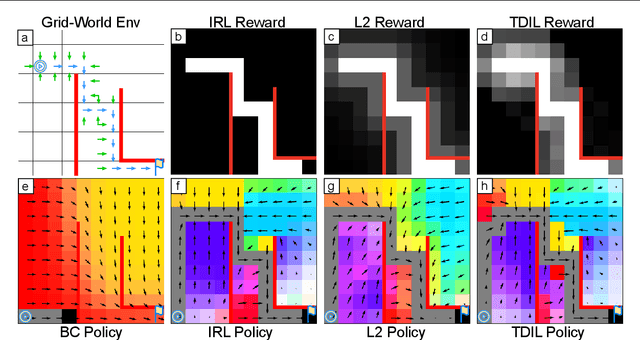
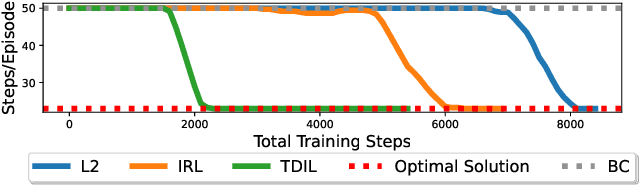
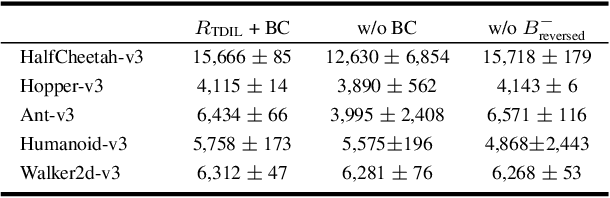
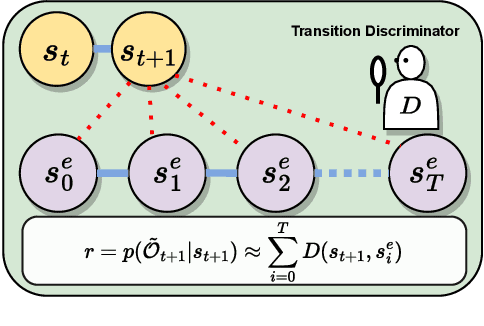
In this paper, we focus on single-demonstration imitation learning (IL), a practical approach for real-world applications where obtaining numerous expert demonstrations is costly or infeasible. In contrast to typical IL settings with multiple demonstrations, single-demonstration IL involves an agent having access to only one expert trajectory. We highlight the issue of sparse reward signals in this setting and propose to mitigate this issue through our proposed Transition Discriminator-based IL (TDIL) method. TDIL is an IRL method designed to address reward sparsity by introducing a denser surrogate reward function that considers environmental dynamics. This surrogate reward function encourages the agent to navigate towards states that are proximal to expert states. In practice, TDIL trains a transition discriminator to differentiate between valid and non-valid transitions in a given environment to compute the surrogate rewards. The experiments demonstrate that TDIL outperforms existing IL approaches and achieves expert-level performance in the single-demonstration IL setting across five widely adopted MuJoCo benchmarks as well as the "Adroit Door" environment.
A Unified Framework for Factorizing Distributional Value Functions for Multi-Agent Reinforcement Learning
Jun 04, 2023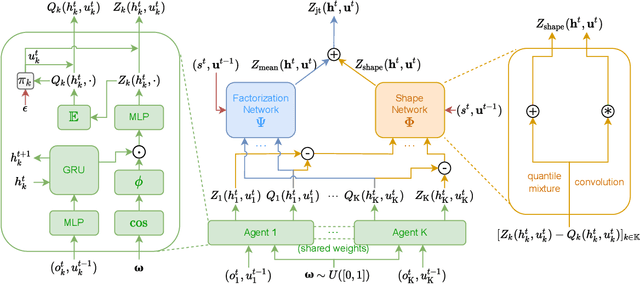

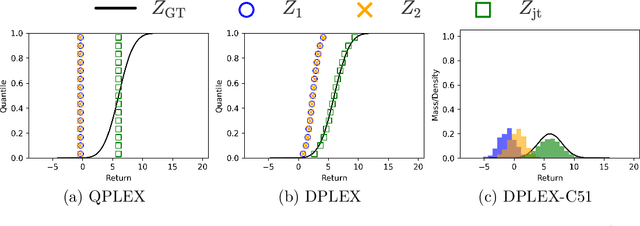
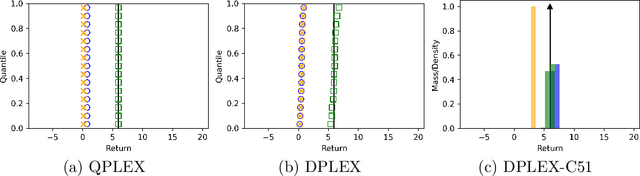
In fully cooperative multi-agent reinforcement learning (MARL) settings, environments are highly stochastic due to the partial observability of each agent and the continuously changing policies of other agents. To address the above issues, we proposed a unified framework, called DFAC, for integrating distributional RL with value function factorization methods. This framework generalizes expected value function factorization methods to enable the factorization of return distributions. To validate DFAC, we first demonstrate its ability to factorize the value functions of a simple matrix game with stochastic rewards. Then, we perform experiments on all Super Hard maps of the StarCraft Multi-Agent Challenge and six self-designed Ultra Hard maps, showing that DFAC is able to outperform a number of baselines.
Training Energy-Based Normalizing Flow with Score-Matching Objectives
May 24, 2023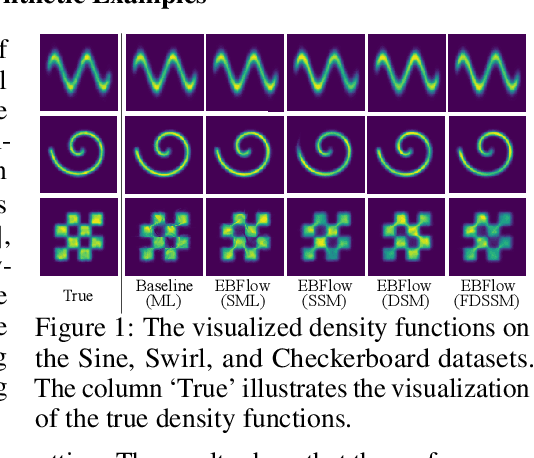

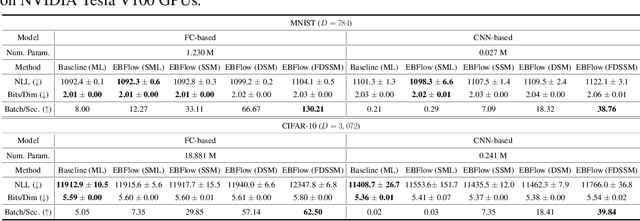
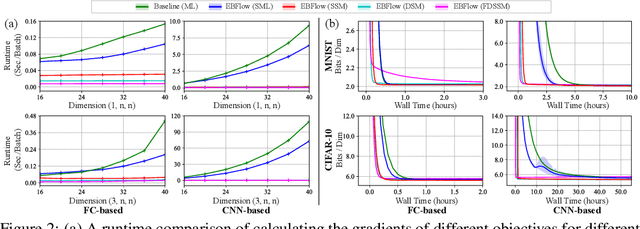
In this paper, we establish a connection between the parameterization of flow-based and energy-based generative models, and present a new flow-based modeling approach called energy-based normalizing flow (EBFlow). We demonstrate that by optimizing EBFlow with score-matching objectives, the computation of Jacobian determinants for linear transformations can be entirely bypassed. This feature enables the use of arbitrary linear layers in the construction of flow-based models without increasing the computational time complexity of each training iteration from $\mathcal{O}(D^2L)$ to $\mathcal{O}(D^3L)$ for an $L$-layered model that accepts $D$-dimensional inputs. This makes the training of EBFlow more efficient than the commonly-adopted maximum likelihood training method. In addition to the reduction in runtime, we enhance the training stability and empirical performance of EBFlow through a number of techniques developed based on our analysis on the score-matching methods. The experimental results demonstrate that our approach achieves a significant speedup compared to maximum likelihood estimation, while outperforming prior efficient training techniques with a noticeable margin in terms of negative log-likelihood (NLL).
Quasi-Conservative Score-based Generative Models
Sep 26, 2022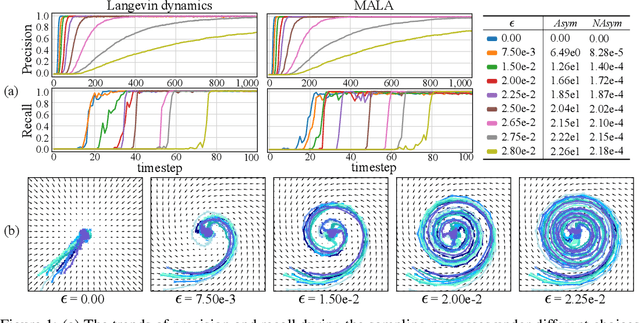
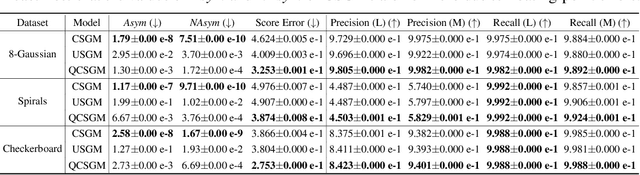
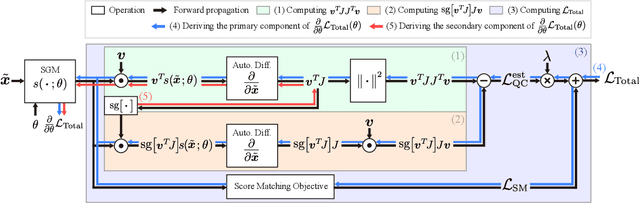
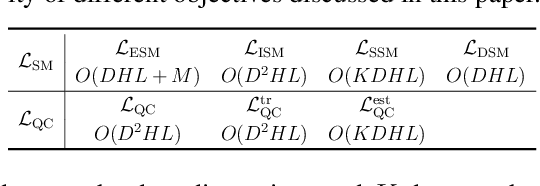
Existing Score-based Generative Models (SGMs) can be categorized into constrained SGMs (CSGMs) or unconstrained SGMs (USGMs) according to their parameterization approaches. CSGMs model the probability density functions as Boltzmann distributions, and assign their predictions as the negative gradients of some scalar-valued energy functions. On the other hand, USGMs employ flexible architectures capable of directly estimating scores without the need to explicitly model energy functions. In this paper, we demonstrate that the architectural constraints of CSGMs may limit their score-matching ability. In addition, we show that USGMs' inability to preserve the property of conservativeness may lead to serious sampling inefficiency and degraded sampling performance in practice. To address the above issues, we propose Quasi-Conservative Score-based Generative Models (QCSGMs) for keeping the advantages of both CSGMs and USGMs. Our theoretical derivations demonstrate that the training objective of QCSGMs can be efficiently integrated into the training processes by leveraging the Hutchinson trace estimator. In addition, our experimental results on the Cifar-10, Cifar-100, ImageNet, and SVHN datasets validate the effectiveness of QCSGMs. Finally, we justify the advantage of QCSGMs using an example of a one-layered autoencoder.