 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCC: Generative Color Constancy via Diffusing a Color Checker
Feb 24, 2025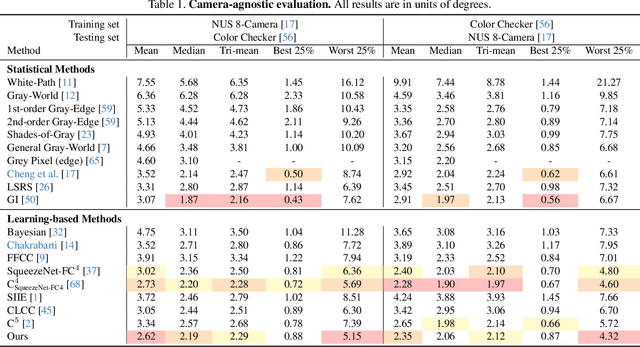



Color constancy methods often struggle to generalize across different camera sensors due to varying spectral sensitivities. We present GCC, which leverages diffusion models to inpaint color checkers into images for illumination estimation. Our key innovations include (1) a single-step deterministic inference approach that inpaints color checkers reflecting scene illumination, (2) a Laplacian decomposition technique that preserves checker structure while allowing illumination-dependent color adaptation, and (3) a mask-based data augmentation strategy for handling imprecise color checker annotations. GCC demonstrates superior robustness in cross-camera scenarios, achieving state-of-the-art worst-25% error rates of 5.15{\deg} and 4.32{\deg} in bi-directional evaluations. These results highlight our method's stability and generalization capability across different camera characteristics without requiring sensor-specific training, making it a versatile solution for real-world applications.
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Mar 30, 2024



Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/FlowSR-LP
DriveEnv-NeRF: Exploration of A NeRF-Based Autonomous Driving Environment for Real-World Performance Validation
Mar 23, 2024
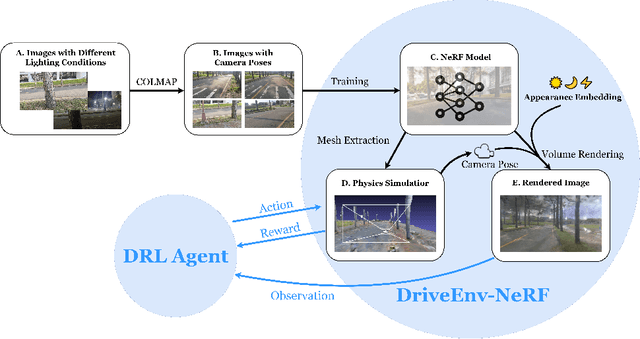


In this study, we introduce the DriveEnv-NeRF framework, which leverages Neural Radiance Fields (NeRF) to enable the validation and faithful forecasting of the efficacy of autonomous driving agents in a targeted real-world scene. Standard simulator-based rendering often fails to accurately reflect real-world performance due to the sim-to-real gap, which represents the disparity between virtual simulations and real-world conditions. To mitigate this gap, we propose a workflow for building a high-fidelity simulation environment of the targeted real-world scene using NeRF. This approach is capable of rendering realistic images from novel viewpoints and constructing 3D meshes for emulating collisions. The validation of these capabilities through the comparison of success rates in both simulated and real environments demonstrates the benefits of using DriveEnv-NeRF as a real-world performance indicator. Furthermore, the DriveEnv-NeRF framework can serve as a training environment for autonomous driving agents under various lighting conditions. This approach enhances the robustness of the agents and reduces performance degradation when deployed to the target real scene, compared to agents fully trained using the standard simulator rendering pipeline.
Local Implicit Normalizing Flow for Arbitrary-Scale Image Super-Resolution
Mar 09, 2023



Flow-based methods have demonstrated promising results in addressing the ill-posed nature of super-resolution (SR) by learning the distribution of high-resolution (HR) images with the normalizing flow. However, these methods can only perform a predefined fixed-scale SR, limiting their potential in real-world applications. Meanwhile, arbitrary-scale SR has gained more attention and achieved great progress. Nonetheless, previous arbitrary-scale SR methods ignore the ill-posed problem and train the model with per-pixel L1 loss, leading to blurry SR outputs. In this work, we propose "Local Implicit Normalizing Flow" (LINF) as a unified solution to the above problems. LINF models the distribution of texture details under different scaling factors with normalizing flow. Thus, LINF can generate photo-realistic HR images with rich texture details in arbitrary scale factors. We evaluate LINF with extensive experiments and show that LINF achieves the state-of-the-art perceptual quality compared with prior arbitrary-scale SR methods.
ELDA: Using Edges to Have an Edge on Semantic Segmentation Based UDA
Nov 16, 2022



Many unsupervised domain adaptation (UDA) methods have been proposed to bridge the domain gap by utilizing domain invariant information. Most approaches have chosen depth as such information and achieved remarkable success. Despite their effectiveness, using depth as domain invariant information in UDA tasks may lead to multiple issues, such as excessively high extraction costs and difficulties in achieving a reliable prediction quality. As a result, we introduce Edge Learning based Domain Adaptation (ELDA), a framework which incorporates edge information into its training process to serve as a type of domain invariant information. In our experiments, we quantitatively and qualitatively demonstrate that the incorporation of edge information is indeed beneficial and effective and enables ELDA to outperform the contemporary state-of-the-art methods on two commonly adopted benchmarks for semantic segmentation based UDA tasks. In addition, we show that ELDA is able to better separate the feature distributions of different classes. We further provide an ablation analysis to justify our design decisions.
Denoising Likelihood Score Matching for Conditional Score-based Data Generation
Mar 27, 2022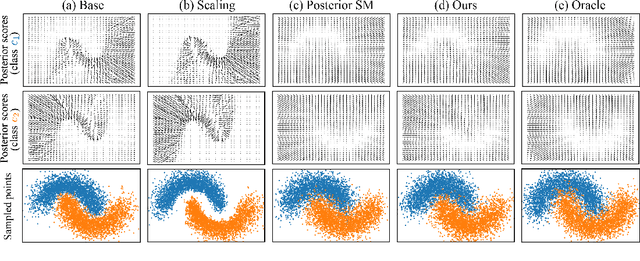
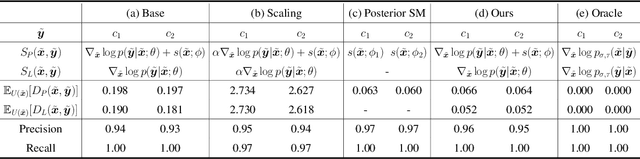

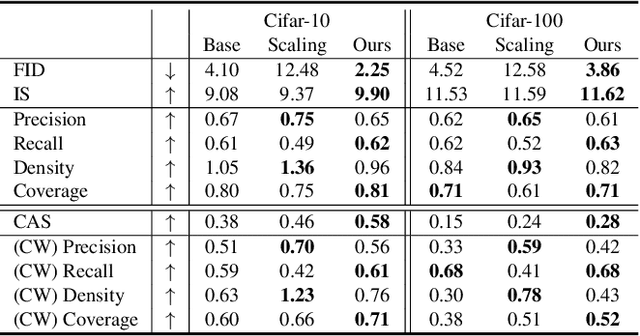
Many existing conditional score-based data generation methods utilize Bayes' theorem to decompose the gradients of a log posterior density into a mixture of scores. These methods facilitate the training procedure of conditional score models, as a mixture of scores can be separately estimated using a score model and a classifier. However, our analysis indicates that the training objectives for the classifier in these methods may lead to a serious score mismatch issue, which corresponds to the situation that the estimated scores deviate from the true ones. Such an issue causes the samples to be misled by the deviated scores during the diffusion process, resulting in a degraded sampling quality. To resolve it, we formulate a novel training objective, called Denoising Likelihood Score Matching (DLSM) loss, for the classifier to match the gradients of the true log likelihood density. Our experimental evidence shows that the proposed method outperforms the previous methods on both Cifar-10 and Cifar-100 benchmarks noticeably in terms of several key evaluation metrics. We thus conclude that, by adopting DLSM, the conditional scores can be accurately modeled, and the effect of the score mismatch issue is alleviated.
CLCC: Contrastive Learning for Color Constancy
Jun 09, 2021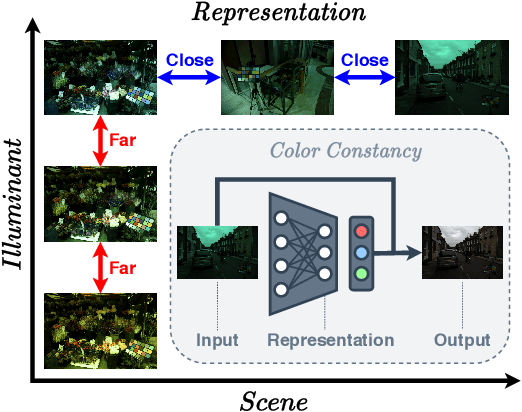
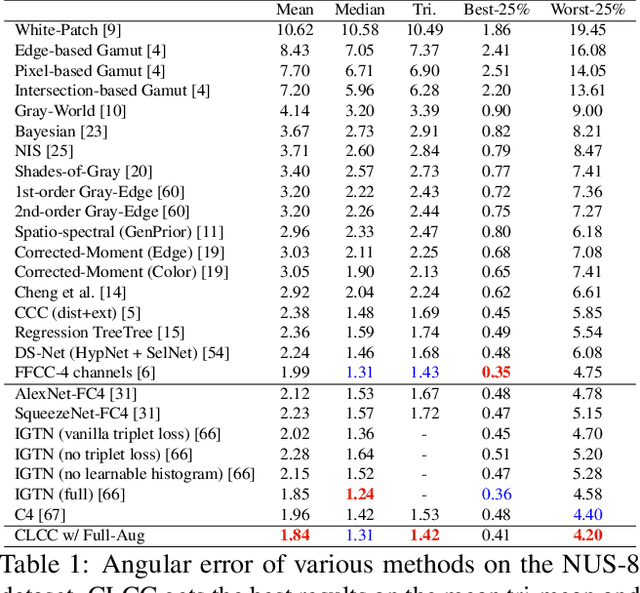
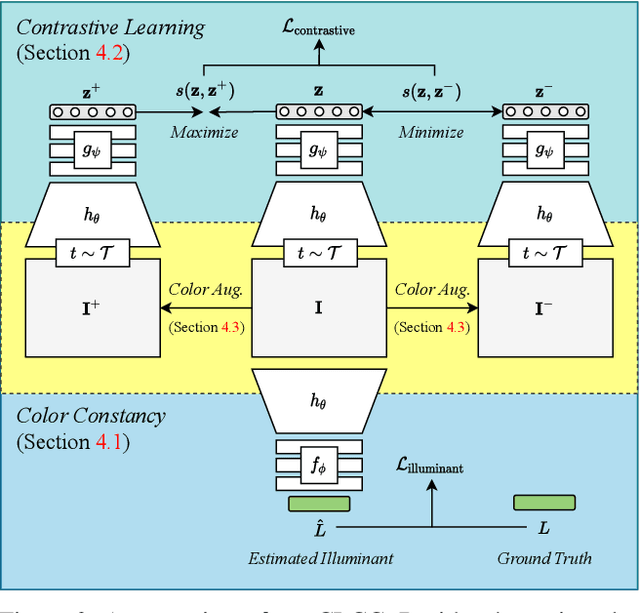
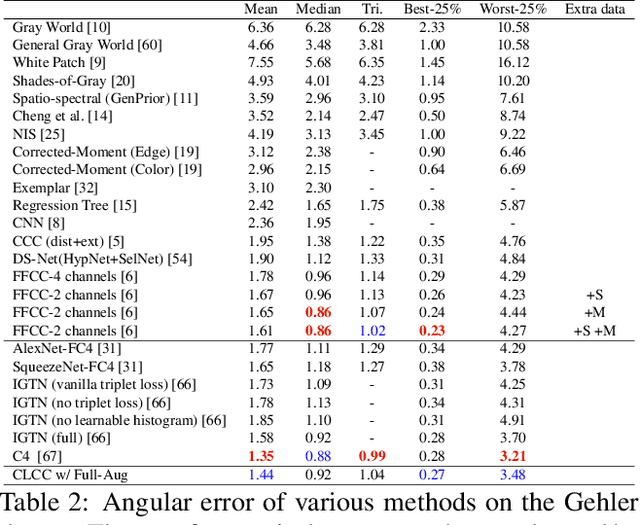
In this paper, we present CLCC, a novel contrastive learning framework for color constancy. Contrastive learning has been applied for learning high-quality visual representations for image classification. One key aspect to yield useful representations for image classification is to design illuminant invariant augmentations. However, the illuminant invariant assumption conflicts with the nature of the color constancy task, which aims to estimate the illuminant given a raw image. Therefore, we construct effective contrastive pairs for learning better illuminant-dependent features via a novel raw-domain color augmentation. On the NUS-8 dataset, our method provides $17.5\%$ relative improvements over a strong baseline, reaching state-of-the-art performance without increasing model complexity. Furthermore, our method achieves competitive performance on the Gehler dataset with $3\times$ fewer parameters compared to top-ranking deep learning methods. More importantly, we show that our model is more robust to different scenes under close proximity of illuminants, significantly reducing $28.7\%$ worst-case error in data-sparse regions.
COCO-GAN: Generation by Parts via Conditional Coordinating
Apr 16, 2019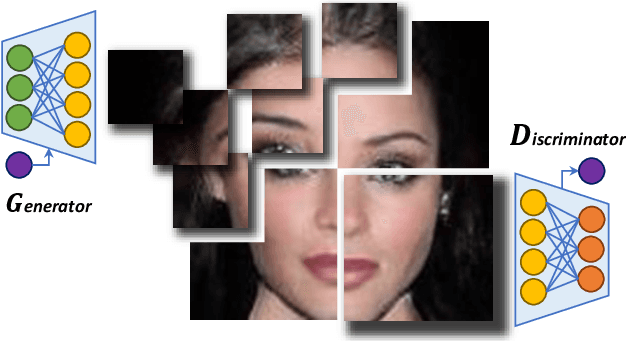
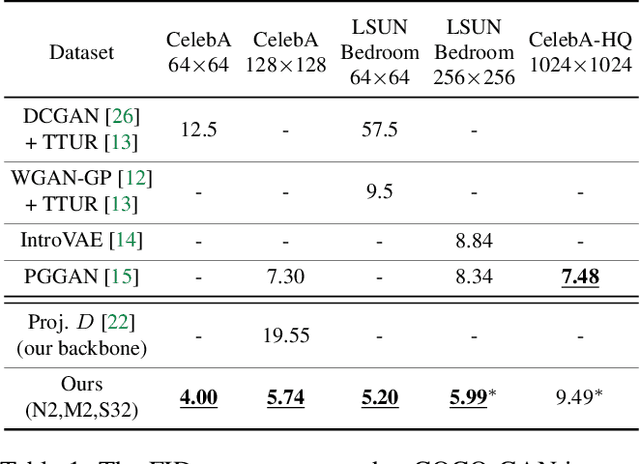
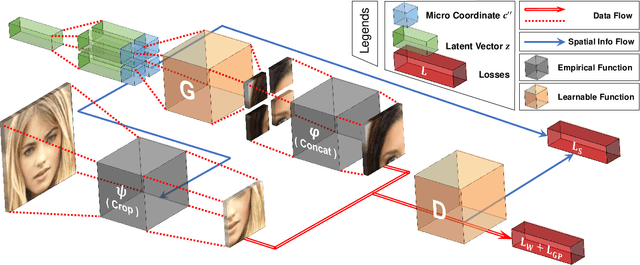

Humans can only interact with part of the surrounding environment due to biological restrictions. Therefore, we learn to reason the spatial relationships across a series of observations to piece together the surrounding environment. Inspired by such behavior and the fact that machines also have computational constraints, we propose \underline{CO}nditional \underline{CO}ordinate GAN (COCO-GAN) of which the generator generates images by parts based on their spatial coordinates as the condition. On the other hand, the discriminator learns to justify realism across multiple assembled patches by global coherence, local appearance, and edge-crossing continuity. Despite the full images are never generated during training, we show that COCO-GAN can produce \textbf{state-of-the-art-quality} full images during inference. We further demonstrate a variety of novel applications enabled by teaching the network to be aware of coordinates. First, we perform extrapolation to the learned coordinate manifold and generate off-the-boundary patches. Combining with the originally generated full image, COCO-GAN can produce images that are larger than training samples, which we called "beyond-boundary generation". We then showcase panorama generation within a cylindrical coordinate system that inherently preserves horizontally cyclic topology. On the computation side, COCO-GAN has a built-in divide-and-conquer paradigm that reduces memory requisition during training and inference, provides high-parallelism, and can generate parts of images on-demand.
Knowledge Distillation with Feature Maps for Image Classification
Dec 03, 2018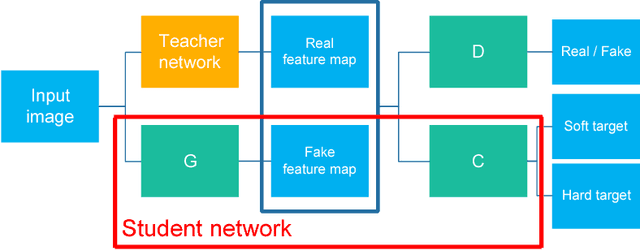


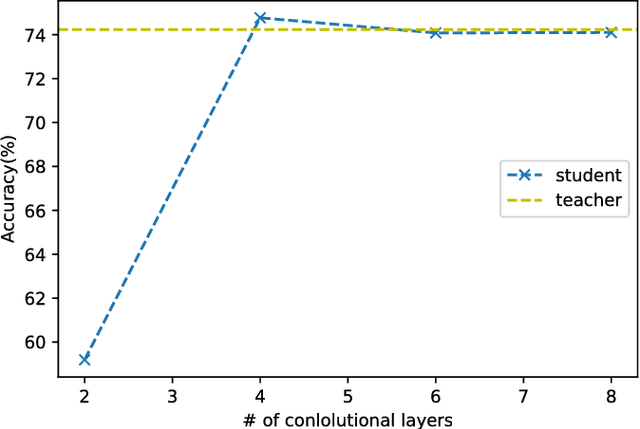
The model reduction problem that eases the computation costs and latency of complex deep learning architectures has received an increasing number of investigations owing to its importance in model deployment. One promising method is knowledge distillation (KD), which creates a fast-to-execute student model to mimic a large teacher network. In this paper, we propose a method, called KDFM (Knowledge Distillation with Feature Maps), which improves the effectiveness of KD by learning the feature maps from the teacher network. Two major techniques used in KDFM are shared classifier and generative adversarial network. Experimental results show that KDFM can use a four layers CNN to mimic DenseNet-40 and use MobileNet to mimic DenseNet-100. Both student networks have less than 1\% accuracy loss comparing to their teacher models for CIFAR-100 datasets. The student networks are 2-6 times faster than their teacher models for inference, and the model size of MobileNet is less than half of DenseNet-100's.
Escaping from Collapsing Modes in a Constrained Space
Aug 22, 2018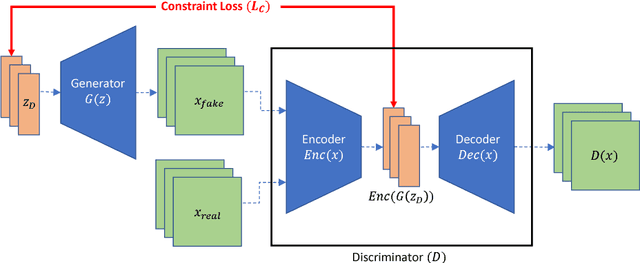

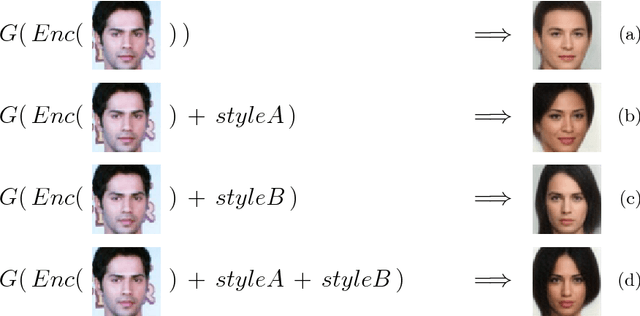
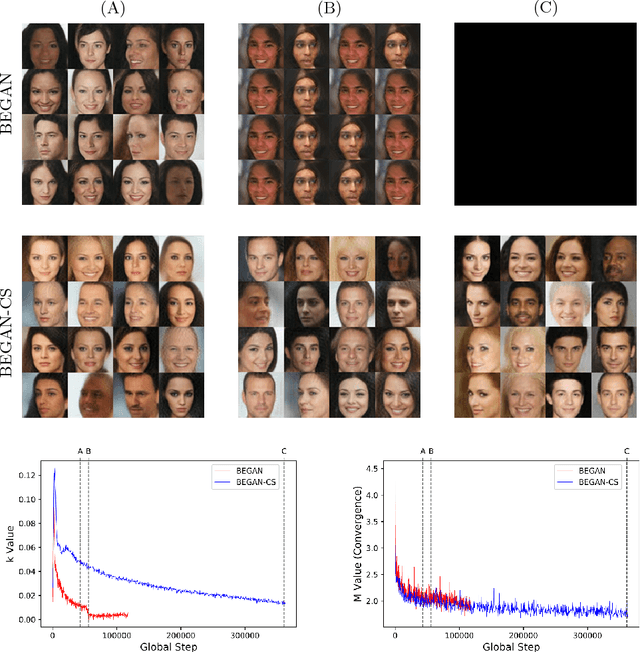
Generative adversarial networks (GANs) often suffer from unpredictable mode-collapsing during training. We study the issue of mode collapse of Boundary Equilibrium Generative Adversarial Network (BEGAN), which is one of the state-of-the-art generative models. Despite its potential of generating high-quality images, we find that BEGAN tends to collapse at some modes after a period of training. We propose a new model, called \emph{BEGAN with a Constrained Space} (BEGAN-CS), which includes a latent-space constraint in the loss function. We show that BEGAN-CS can significantly improve training stability and suppress mode collapse without either increasing the model complexity or degrading the image quality. Further, we visualize the distribution of latent vectors to elucidate the effect of latent-space constraint. The experimental results show that our method has additional advantages of being able to train on small datasets and to generate images similar to a given real image yet with variations of designated attributes on-the-fly.