 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliSDiP: Image Super-Resolution via Holistic Semantics and Diffusion Prior
Nov 27, 2024Text-to-image diffusion models have emerged as powerful priors for real-world image super-resolution (Real-ISR). However, existing methods may produce unintended results due to noisy text prompts and their lack of spatial information. In this paper, we present HoliSDiP, a framework that leverages semantic segmentation to provide both precise textual and spatial guidance for diffusion-based Real-ISR. Our method employs semantic labels as concise text prompts while introducing dense semantic guidance through segmentation masks and our proposed Segmentation-CLIP Map. Extensive experiments demonstrate that HoliSDiP achieves significant improvement in image quality across various Real-ISR scenarios through reduced prompt noise and enhanced spatial control.
AdaIR: Exploiting Underlying Similarities of Image Restoration Tasks with Adapters
Apr 17, 2024Existing image restoration approaches typically employ extensive networks specifically trained for designated degradations. Despite being effective, such methods inevitably entail considerable storage costs and computational overheads due to the reliance on task-specific networks. In this work, we go beyond this well-established framework and exploit the inherent commonalities among image restoration tasks. The primary objective is to identify components that are shareable across restoration tasks and augment the shared components with modules specifically trained for individual tasks. Towards this goal, we propose AdaIR, a novel framework that enables low storage cost and efficient training without sacrificing performance. Specifically, a generic restoration network is first constructed through self-supervised pre-training using synthetic degradations. Subsequent to the pre-training phase, adapters are trained to adapt the pre-trained network to specific degradations. AdaIR requires solely the training of lightweight, task-specific modules, ensuring a more efficient storage and training regimen. We have conducted extensive experiments to validate the effectiveness of AdaIR and analyze the influence of the pre-training strategy on discovering shareable components. Extensive experimental results show that AdaIR achieves outstanding results on multi-task restoration while utilizing significantly fewer parameters (1.9 MB) and less training time (7 hours) for each restoration task. The source codes and trained models will be released.
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Mar 30, 2024



Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/FlowSR-LP
Confronting Ambiguity in 6D Object Pose Estimation via Score-Based Diffusion on SE(3)
May 25, 2023



Addressing accuracy limitations and pose ambiguity in 6D object pose estimation from single RGB images presents a significant challenge, particularly due to object symmetries or occlusions. In response, we introduce a novel score-based diffusion method applied to the $SE(3)$ group, marking the first application of diffusion models to $SE(3)$ within the image domain, specifically tailored for pose estimation tasks. Extensive evaluations demonstrate the method's efficacy in handling pose ambiguity, mitigating perspective-induced ambiguity, and showcasing the robustness of our surrogate Stein score formulation on $SE(3)$. This formulation not only improves the convergence of Langevin dynamics but also enhances computational efficiency. Thus, we pioneer a promising strategy for 6D object pose estimation.
Cascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution
Mar 29, 2023Implicit neural representation has recently shown a promising ability in representing images with arbitrary resolutions. In this paper, we present a Local Implicit Transformer (LIT), which integrates the attention mechanism and frequency encoding technique into a local implicit image function. We design a cross-scale local attention block to effectively aggregate local features. To further improve representative power, we propose a Cascaded LIT (CLIT) that exploits multi-scale features, along with a cumulative training strategy that gradually increases the upsampling scales during training. We have conducted extensive experiments to validate the effectiveness of these components and analyze various training strategies. The qualitative and quantitative results demonstrate that LIT and CLIT achieve favorable results and outperform the prior works in arbitrary super-resolution tasks.
Pixel-Wise Prediction based Visual Odometry via Uncertainty Estimation
Aug 18, 2022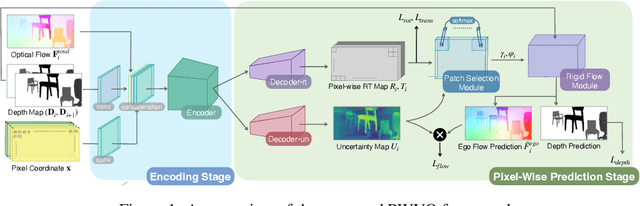

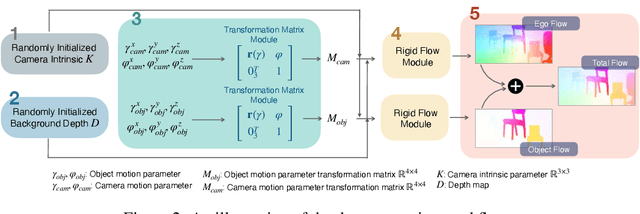
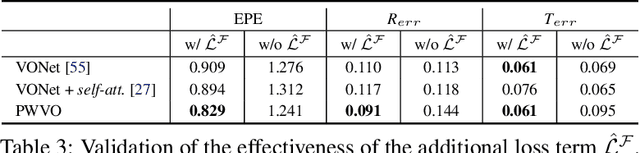
This paper introduces pixel-wise prediction based visual odometry (PWVO), which is a dense prediction task that evaluates the values of translation and rotation for every pixel in its input observations. PWVO employs uncertainty estimation to identify the noisy regions in the input observations, and adopts a selection mechanism to integrate pixel-wise predictions based on the estimated uncertainty maps to derive the final translation and rotation. In order to train PWVO in a comprehensive fashion, we further develop a data generation workflow for generating synthetic training data. The experimental results show that PWVO is able to deliver favorable results. In addition, our analyses validate the effectiveness of the designs adopted in PWVO, and demonstrate that the uncertainty maps estimated by PWVO is capable of capturing the noises in its input observations.