 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReprojection Errors as Prompts for Efficient Scene Coordinate Regression
Sep 06, 2024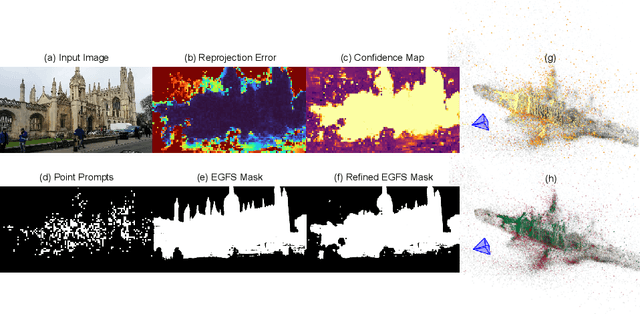
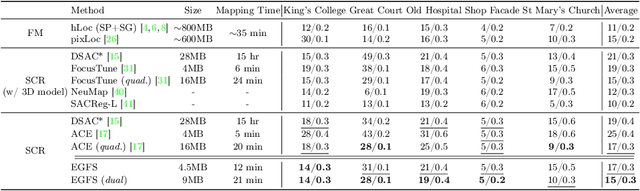
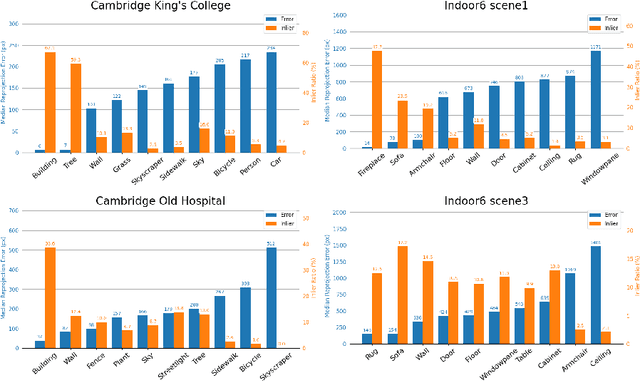
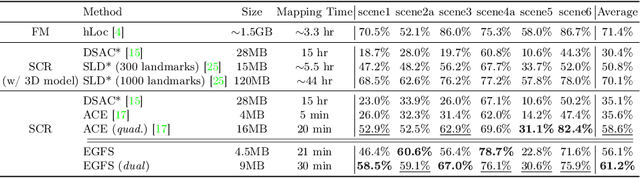
Scene coordinate regression (SCR) methods have emerged as a promising area of research due to their potential for accurate visual localization. However, many existing SCR approaches train on samples from all image regions, including dynamic objects and texture-less areas. Utilizing these areas for optimization during training can potentially hamper the overall performance and efficiency of the model. In this study, we first perform an in-depth analysis to validate the adverse impacts of these areas. Drawing inspiration from our analysis, we then introduce an error-guided feature selection (EGFS) mechanism, in tandem with the use of the Segment Anything Model (SAM). This mechanism seeds low reprojection areas as prompts and expands them into error-guided masks, and then utilizes these masks to sample points and filter out problematic areas in an iterative manner. The experiments demonstrate that our method outperforms existing SCR approaches that do not rely on 3D information on the Cambridge Landmarks and Indoor6 datasets.
Confronting Ambiguity in 6D Object Pose Estimation via Score-Based Diffusion on SE(3)
May 25, 2023



Addressing accuracy limitations and pose ambiguity in 6D object pose estimation from single RGB images presents a significant challenge, particularly due to object symmetries or occlusions. In response, we introduce a novel score-based diffusion method applied to the $SE(3)$ group, marking the first application of diffusion models to $SE(3)$ within the image domain, specifically tailored for pose estimation tasks. Extensive evaluations demonstrate the method's efficacy in handling pose ambiguity, mitigating perspective-induced ambiguity, and showcasing the robustness of our surrogate Stein score formulation on $SE(3)$. This formulation not only improves the convergence of Langevin dynamics but also enhances computational efficiency. Thus, we pioneer a promising strategy for 6D object pose estimation.
Vision based Virtual Guidance for Navigation
Mar 05, 2023



This paper explores the impact of virtual guidance on mid-level representation-based navigation, where an agent performs navigation tasks based solely on visual observations. Instead of providing distance measures or numerical directions to guide the agent, which may be difficult for it to interpret visually, the paper investigates the potential of different forms of virtual guidance schemes on navigation performance. Three schemes of virtual guidance signals are explored: virtual navigation path, virtual waypoints, and a combination of both. The experiments were conducted using a virtual city built with the Unity engine to train the agents while avoiding obstacles. The results show that virtual guidance provides the agent with more meaningful navigation information and achieves better performance in terms of path completion rates and navigation efficiency. In addition, a set of analyses were provided to investigate the failure cases and the navigated trajectories, and a pilot study was conducted for the real-world scenarios.
Pixel-Wise Prediction based Visual Odometry via Uncertainty Estimation
Aug 18, 2022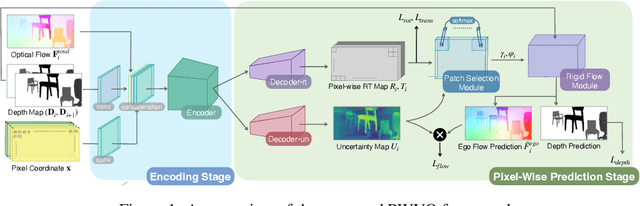

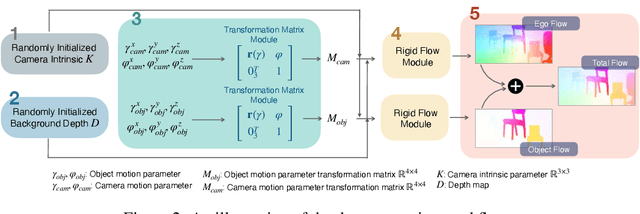
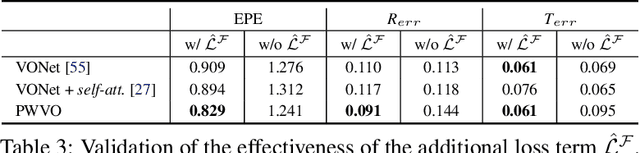
This paper introduces pixel-wise prediction based visual odometry (PWVO), which is a dense prediction task that evaluates the values of translation and rotation for every pixel in its input observations. PWVO employs uncertainty estimation to identify the noisy regions in the input observations, and adopts a selection mechanism to integrate pixel-wise predictions based on the estimated uncertainty maps to derive the final translation and rotation. In order to train PWVO in a comprehensive fashion, we further develop a data generation workflow for generating synthetic training data. The experimental results show that PWVO is able to deliver favorable results. In addition, our analyses validate the effectiveness of the designs adopted in PWVO, and demonstrate that the uncertainty maps estimated by PWVO is capable of capturing the noises in its input observations.
Investigation of Factorized Optical Flows as Mid-Level Representations
Mar 10, 2022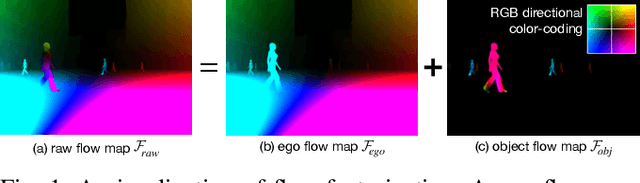
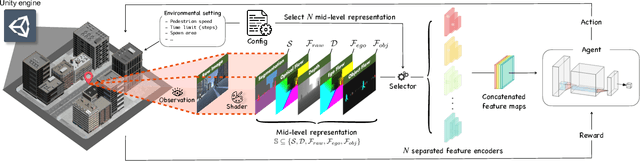
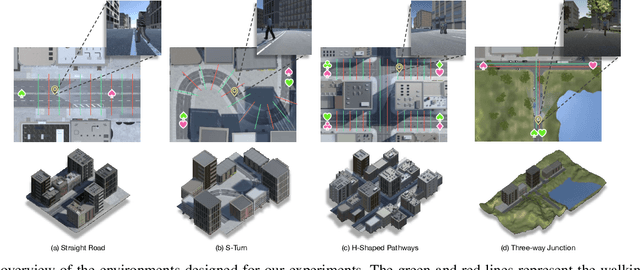
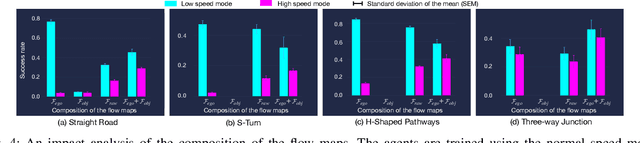
In this paper, we introduce a new concept of incorporating factorized flow maps as mid-level representations, for bridging the perception and the control modules in modular learning based robotic frameworks. To investigate the advantages of factorized flow maps and examine their interplay with the other types of mid-level representations, we further develop a configurable framework, along with four different environments that contain both static and dynamic objects, for analyzing the impacts of factorized optical flow maps on the performance of deep reinforcement learning agents. Based on this framework, we report our experimental results on various scenarios, and offer a set of analyses to justify our hypothesis. Finally, we validate flow factorization in real world scenarios.
Mixture of Step Returns in Bootstrapped DQN
Jul 16, 2020



The concept of utilizing multi-step returns for updating value functions has been adopted in deep reinforcement learning (DRL) for a number of years. Updating value functions with different backup lengths provides advantages in different aspects, including bias and variance of value estimates, convergence speed, and exploration behavior of the agent. Conventional methods such as TD-lambda leverage these advantages by using a target value equivalent to an exponential average of different step returns. Nevertheless, integrating step returns into a single target sacrifices the diversity of the advantages offered by different step return targets. To address this issue, we propose Mixture Bootstrapped DQN (MB-DQN) built on top of bootstrapped DQN, and uses different backup lengths for different bootstrapped heads. MB-DQN enables heterogeneity of the target values that is unavailable in approaches relying only on a single target value. As a result, it is able to maintain the advantages offered by different backup lengths. In this paper, we first discuss the motivational insights through a simple maze environment. In order to validate the effectiveness of MB-DQN, we perform experiments on the Atari 2600 benchmark environments, and demonstrate the performance improvement of MB-DQN over a number of baseline methods. We further provide a set of ablation studies to examine the impacts of different design configurations of MB-DQN.
Exploration via Flow-Based Intrinsic Rewards
May 24, 2019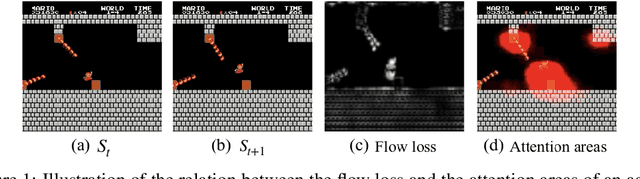
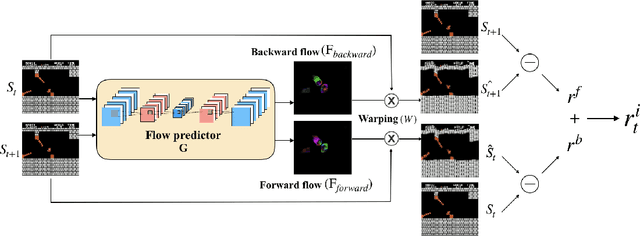
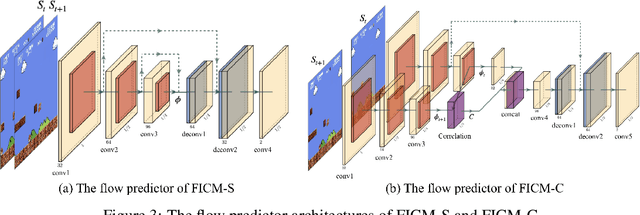
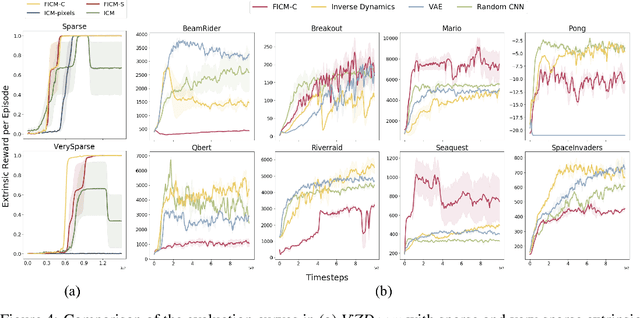
Exploration bonuses derived from the novelty of observations in an environment have become a popular approach to motivate exploration for reinforcement learning (RL) agents in the past few years. Recent methods such as curiosity-driven exploration usually estimate the novelty of new observations by the prediction errors of their system dynamics models. In this paper, we introduce the concept of optical flow estimation from the field of computer vision to the RL domain and utilize the errors from optical flow estimation to evaluate the novelty of new observations. We introduce a flow-based intrinsic curiosity module (FICM) capable of learning the motion features and understanding the observations in a more comprehensive and efficient fashion. We evaluate our method and compare it with a number of baselines on several benchmark environments, including Atari games, Super Mario Bros., and ViZDoom. Our results show that the proposed method is superior to the baselines in certain environments, especially for those featuring sophisticated moving patterns or with high-dimensional observation spaces. We further analyze the hyper-parameters used in the training phase and discuss our insights into them.
Never Forget: Balancing Exploration and Exploitation via Learning Optical Flow
Jan 24, 2019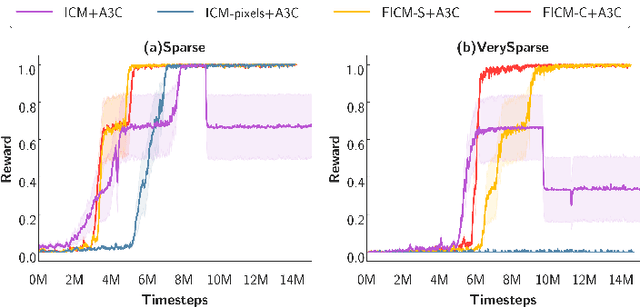

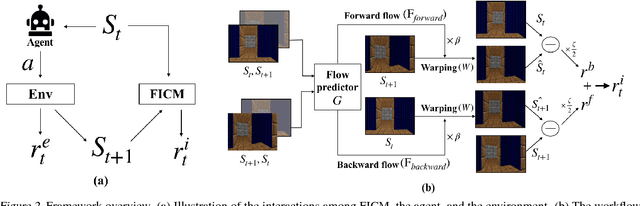
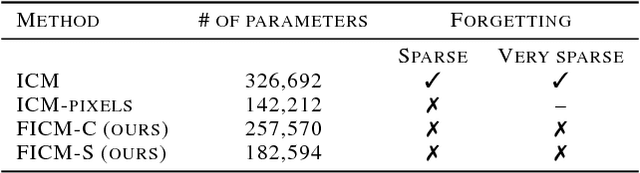
Exploration bonus derived from the novelty of the states in an environment has become a popular approach to motivate exploration for deep reinforcement learning agents in the past few years. Recent methods such as curiosity-driven exploration usually estimate the novelty of new observations by the prediction errors of their system dynamics models. Due to the capacity limitation of the models and difficulty of performing next-frame prediction, however, these methods typically fail to balance between exploration and exploitation in high-dimensional observation tasks, resulting in the agents forgetting the visited paths and exploring those states repeatedly. Such inefficient exploration behavior causes significant performance drops, especially in large environments with sparse reward signals. In this paper, we propose to introduce the concept of optical flow estimation from the field of computer vision to deal with the above issue. We propose to employ optical flow estimation errors to examine the novelty of new observations, such that agents are able to memorize and understand the visited states in a more comprehensive fashion. We compare our method against the previous approaches in a number of experimental experiments. Our results indicate that the proposed method appears to deliver superior and long-lasting performance than the previous methods. We further provide a set of comprehensive ablative analysis of the proposed method, and investigate the impact of optical flow estimation on the learning curves of the DRL agents.
Virtual-to-Real: Learning to Control in Visual Semantic Segmentation
Oct 28, 2018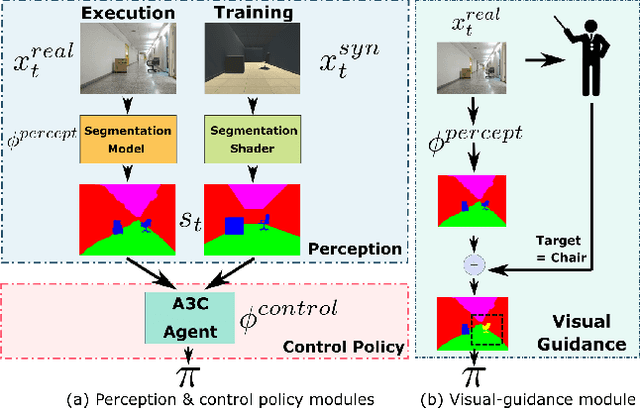



Collecting training data from the physical world is usually time-consuming and even dangerous for fragile robots, and thus, recent advances in robot learning advocate the use of simulators as the training platform. Unfortunately, the reality gap between synthetic and real visual data prohibits direct migration of the models trained in virtual worlds to the real world. This paper proposes a modular architecture for tackling the virtual-to-real problem. The proposed architecture separates the learning model into a perception module and a control policy module, and uses semantic image segmentation as the meta representation for relating these two modules. The perception module translates the perceived RGB image to semantic image segmentation. The control policy module is implemented as a deep reinforcement learning agent, which performs actions based on the translated image segmentation. Our architecture is evaluated in an obstacle avoidance task and a target following task. Experimental results show that our architecture significantly outperforms all of the baseline methods in both virtual and real environments, and demonstrates a faster learning curve than them. We also present a detailed analysis for a variety of variant configurations, and validate the transferability of our modular architecture.
Visual Relationship Prediction via Label Clustering and Incorporation of Depth Information
Sep 09, 2018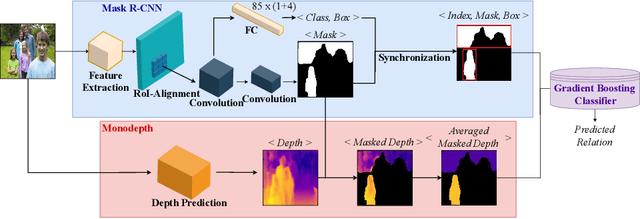
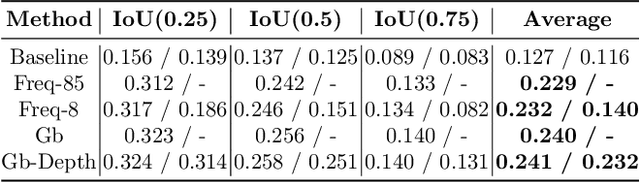
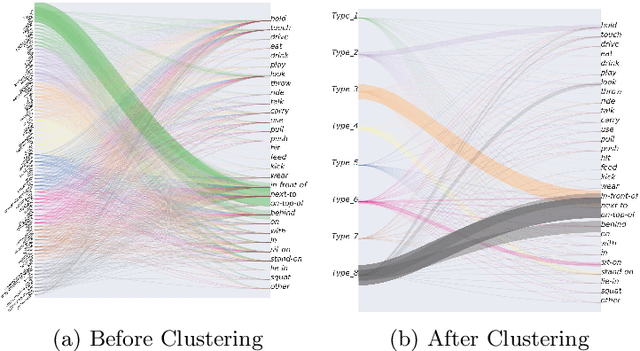
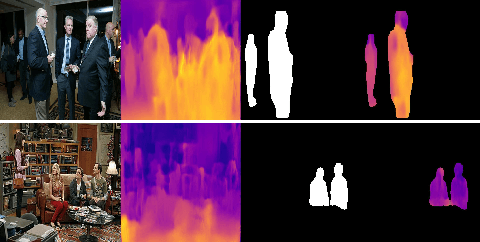
In this paper, we investigate the use of an unsupervised label clustering technique and demonstrate that it enables substantial improvements in visual relationship prediction accuracy on the Person in Context (PIC) dataset. We propose to group object labels with similar patterns of relationship distribution in the dataset into fewer categories. Label clustering not only mitigates both the large classification space and class imbalance issues, but also potentially increases data samples for each clustered category. We further propose to incorporate depth information as an additional feature into the instance segmentation model. The additional depth prediction path supplements the relationship prediction model in a way that bounding boxes or segmentation masks are unable to deliver. We have rigorously evaluated the proposed techniques and performed various ablation analysis to validate the benefits of them.