 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction of Macro Actions for Deep Reinforcement Learning
Aug 05, 2019
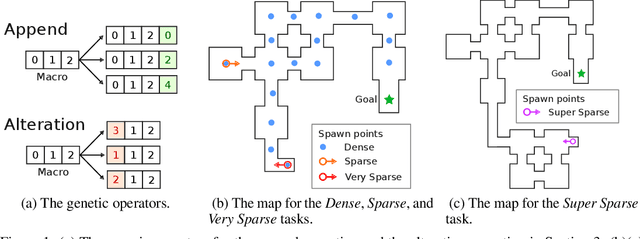
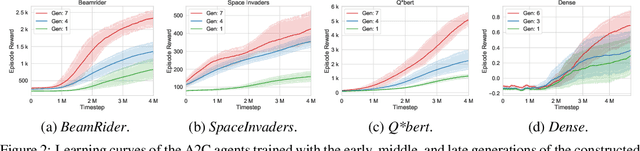
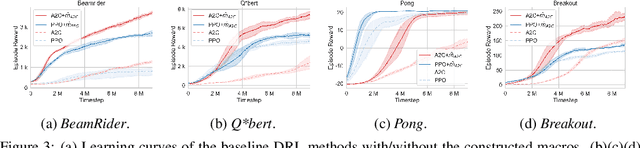
Conventional deep reinforcement learning typically determines an appropriate primitive action at each timestep, which requires enormous amount of time and effort for learning an effective policy, especially in large and complex environments. To deal with the issue fundamentally, we incorporate macro actions, defined as sequences of primitive actions, into the primitive action space to form an augmented action space. The problem lies in how to find an appropriate macro action to augment the primitive action space. The agent using a proper augmented action space is able to jump to a farther state and thus speed up the exploration process as well as facilitate the learning procedure. In previous researches, macro actions are developed by mining the most frequently used action sequences or repeating previous actions. However, the most frequently used action sequences are extracted from a past policy, which may only reinforce the original behavior of that policy. On the other hand, repeating actions may limit the diversity of behaviors of the agent. Instead, we propose to construct macro actions by a genetic algorithm, which eliminates the dependency of the macro action derivation procedure from the past policies of the agent. Our approach appends a macro action to the primitive action space once at a time and evaluates whether the augmented action space leads to promising performance or not. We perform extensive experiments and show that the constructed macro actions are able to speed up the learning process for a variety of deep reinforcement learning methods. Our experimental results also demonstrate that the macro actions suggested by our approach are transferable among deep reinforcement learning methods and similar environments. We further provide a comprehensive set of ablation analysis to validate the proposed methodology.
Virtual-to-Real: Learning to Control in Visual Semantic Segmentation
Oct 28, 2018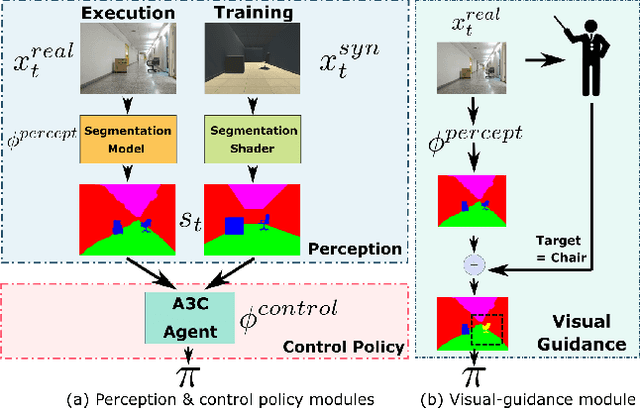



Collecting training data from the physical world is usually time-consuming and even dangerous for fragile robots, and thus, recent advances in robot learning advocate the use of simulators as the training platform. Unfortunately, the reality gap between synthetic and real visual data prohibits direct migration of the models trained in virtual worlds to the real world. This paper proposes a modular architecture for tackling the virtual-to-real problem. The proposed architecture separates the learning model into a perception module and a control policy module, and uses semantic image segmentation as the meta representation for relating these two modules. The perception module translates the perceived RGB image to semantic image segmentation. The control policy module is implemented as a deep reinforcement learning agent, which performs actions based on the translated image segmentation. Our architecture is evaluated in an obstacle avoidance task and a target following task. Experimental results show that our architecture significantly outperforms all of the baseline methods in both virtual and real environments, and demonstrates a faster learning curve than them. We also present a detailed analysis for a variety of variant configurations, and validate the transferability of our modular architecture.
Diversity-Driven Exploration Strategy for Deep Reinforcement Learning
Oct 28, 2018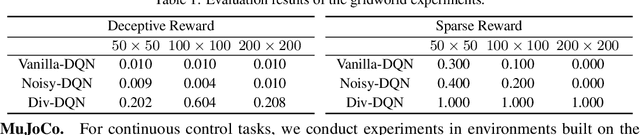


Efficient exploration remains a challenging research problem in reinforcement learning, especially when an environment contains large state spaces, deceptive local optima, or sparse rewards. To tackle this problem, we present a diversity-driven approach for exploration, which can be easily combined with both off- and on-policy reinforcement learning algorithms. We show that by simply adding a distance measure to the loss function, the proposed methodology significantly enhances an agent's exploratory behaviors, and thus preventing the policy from being trapped in local optima. We further propose an adaptive scaling method for stabilizing the learning process. Our experimental results in Atari 2600 show that our method outperforms baseline approaches in several tasks in terms of mean scores and exploration efficiency.
Adversarial Exploration Strategy for Self-Supervised Imitation Learning
Jun 26, 2018
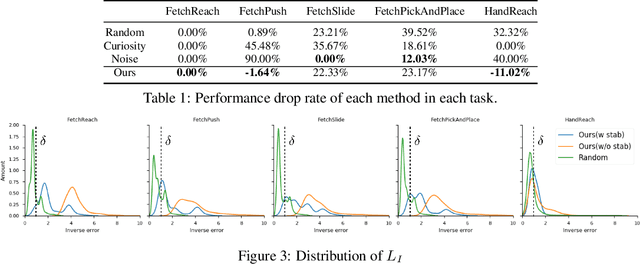


We present an adversarial exploration strategy, a simple yet effective imitation learning scheme that incentivizes exploration of an environment without any extrinsic reward or human demonstration. Our framework consists of a deep reinforcement learning (DRL) agent and an inverse dynamics model contesting with each other. The former collects training samples for the latter, and its objective is to maximize the error of the latter. The latter is trained with samples collected by the former, and generates rewards for the former when it fails to predict the actual action taken by the former. In such a competitive setting, the DRL agent learns to generate samples that the inverse dynamics model fails to predict correctly, and the inverse dynamics model learns to adapt to the challenging samples. We further propose a reward structure that ensures the DRL agent collects only moderately hard samples and not overly hard ones that prevent the inverse model from imitating effectively. We evaluate the effectiveness of our method on several OpenAI gym robotic arm and hand manipulation tasks against a number of baseline models. Experimental results show that our method is comparable to that directly trained with expert demonstrations, and superior to the other baselines even without any human priors.
A Deep Policy Inference Q-Network for Multi-Agent Systems
Apr 09, 2018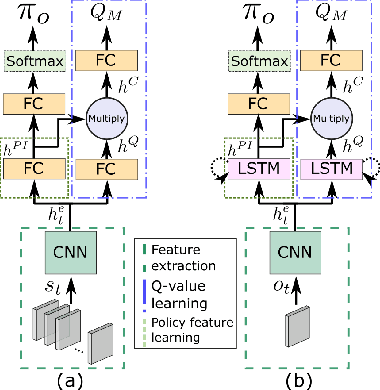
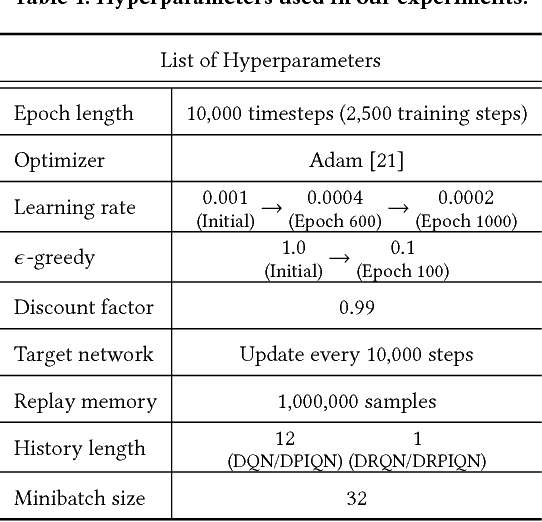
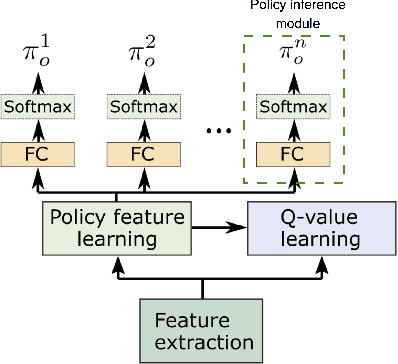
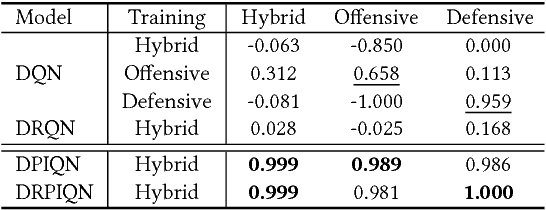
We present DPIQN, a deep policy inference Q-network that targets multi-agent systems composed of controllable agents, collaborators, and opponents that interact with each other. We focus on one challenging issue in such systems---modeling agents with varying strategies---and propose to employ "policy features" learned from raw observations (e.g., raw images) of collaborators and opponents by inferring their policies. DPIQN incorporates the learned policy features as a hidden vector into its own deep Q-network (DQN), such that it is able to predict better Q values for the controllable agents than the state-of-the-art deep reinforcement learning models. We further propose an enhanced version of DPIQN, called deep recurrent policy inference Q-network (DRPIQN), for handling partial observability. Both DPIQN and DRPIQN are trained by an adaptive training procedure, which adjusts the network's attention to learn the policy features and its own Q-values at different phases of the training process. We present a comprehensive analysis of DPIQN and DRPIQN, and highlight their effectiveness and generalizability in various multi-agent settings. Our models are evaluated in a classic soccer game involving both competitive and collaborative scenarios. Experimental results performed on 1 vs. 1 and 2 vs. 2 games show that DPIQN and DRPIQN demonstrate superior performance to the baseline DQN and deep recurrent Q-network (DRQN) models. We also explore scenarios in which collaborators or opponents dynamically change their policies, and show that DPIQN and DRPIQN do lead to better overall performance in terms of stability and mean scores.