 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Shadow Casting for Neural Characters
Jan 11, 2024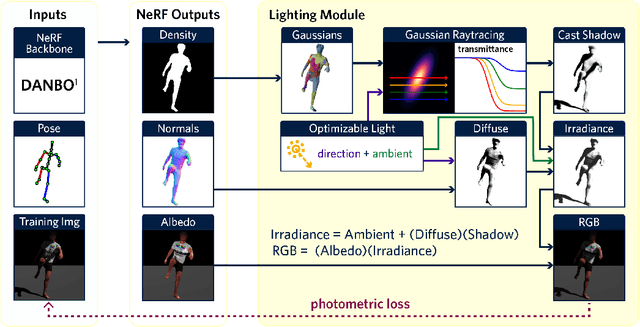

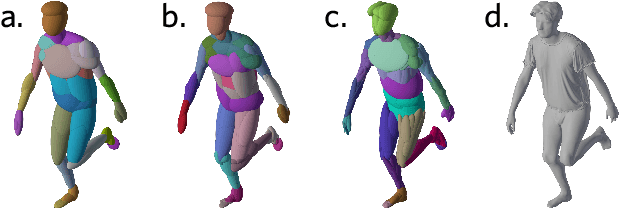

Neural character models can now reconstruct detailed geometry and texture from video, but they lack explicit shadows and shading, leading to artifacts when generating novel views and poses or during relighting. It is particularly difficult to include shadows as they are a global effect and the required casting of secondary rays is costly. We propose a new shadow model using a Gaussian density proxy that replaces sampling with a simple analytic formula. It supports dynamic motion and is tailored for shadow computation, thereby avoiding the affine projection approximation and sorting required by the closely related Gaussian splatting. Combined with a deferred neural rendering model, our Gaussian shadows enable Lambertian shading and shadow casting with minimal overhead. We demonstrate improved reconstructions, with better separation of albedo, shading, and shadows in challenging outdoor scenes with direct sun light and hard shadows. Our method is able to optimize the light direction without any input from the user. As a result, novel poses have fewer shadow artifacts and relighting in novel scenes is more realistic compared to the state-of-the-art methods, providing new ways to pose neural characters in novel environments, increasing their applicability.
Mirror-Aware Neural Humans
Sep 09, 2023Human motion capture either requires multi-camera systems or is unreliable using single-view input due to depth ambiguities. Meanwhile, mirrors are readily available in urban environments and form an affordable alternative by recording two views with only a single camera. However, the mirror setting poses the additional challenge of handling occlusions of real and mirror image. Going beyond existing mirror approaches for 3D human pose estimation, we utilize mirrors for learning a complete body model, including shape and dense appearance. Our main contributions are extending articulated neural radiance fields to include a notion of a mirror, making it sample-efficient over potential occlusion regions. Together, our contributions realize a consumer-level 3D motion capture system that starts from off-the-shelf 2D poses by automatically calibrating the camera, estimating mirror orientation, and subsequently lifting 2D keypoint detections to 3D skeleton pose that is used to condition the mirror-aware NeRF. We empirically demonstrate the benefit of learning a body model and accounting for occlusion in challenging mirror scenes.
NPC: Neural Point Characters from Video
Apr 04, 2023High-fidelity human 3D models can now be learned directly from videos, typically by combining a template-based surface model with neural representations. However, obtaining a template surface requires expensive multi-view capture systems, laser scans, or strictly controlled conditions. Previous methods avoid using a template but rely on a costly or ill-posed mapping from observation to canonical space. We propose a hybrid point-based representation for reconstructing animatable characters that does not require an explicit surface model, while being generalizable to novel poses. For a given video, our method automatically produces an explicit set of 3D points representing approximate canonical geometry, and learns an articulated deformation model that produces pose-dependent point transformations. The points serve both as a scaffold for high-frequency neural features and an anchor for efficiently mapping between observation and canonical space. We demonstrate on established benchmarks that our representation overcomes limitations of prior work operating in either canonical or in observation space. Moreover, our automatic point extraction approach enables learning models of human and animal characters alike, matching the performance of the methods using rigged surface templates despite being more general. Project website: https://lemonatsu.github.io/npc/
DANBO: Disentangled Articulated Neural Body Representations via Graph Neural Networks
May 03, 2022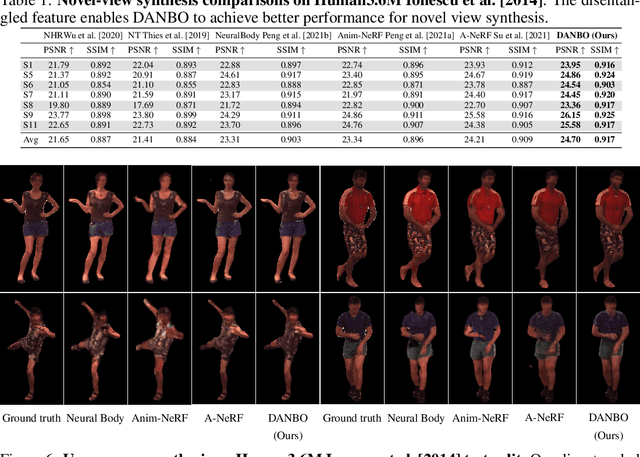
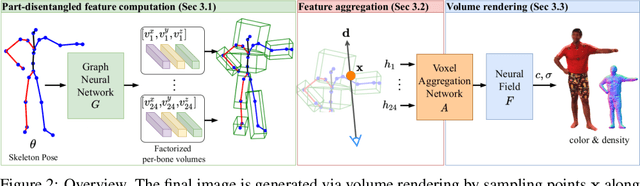
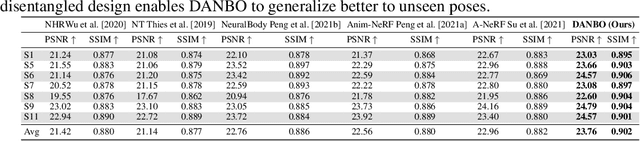

Deep learning greatly improved the realism of animatable human models by learning geometry and appearance from collections of 3D scans, template meshes, and multi-view imagery. High-resolution models enable photo-realistic avatars but at the cost of requiring studio settings not available to end users. Our goal is to create avatars directly from raw images without relying on expensive studio setups and surface tracking. While a few such approaches exist, those have limited generalization capabilities and are prone to learning spurious (chance) correlations between irrelevant body parts, resulting in implausible deformations and missing body parts on unseen poses. We introduce a three-stage method that induces two inductive biases to better disentangled pose-dependent deformation. First, we model correlations of body parts explicitly with a graph neural network. Second, to further reduce the effect of chance correlations, we introduce localized per-bone features that use a factorized volumetric representation and a new aggregation function. We demonstrate that our model produces realistic body shapes under challenging unseen poses and shows high-quality image synthesis. Our proposed representation strikes a better trade-off between model capacity, expressiveness, and robustness than competing methods. Project website: https://lemonatsu.github.io/danbo.
A-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering
Feb 11, 2021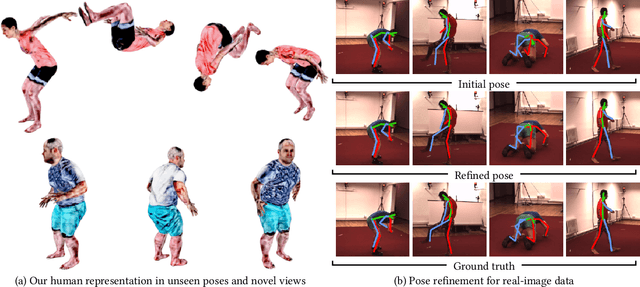
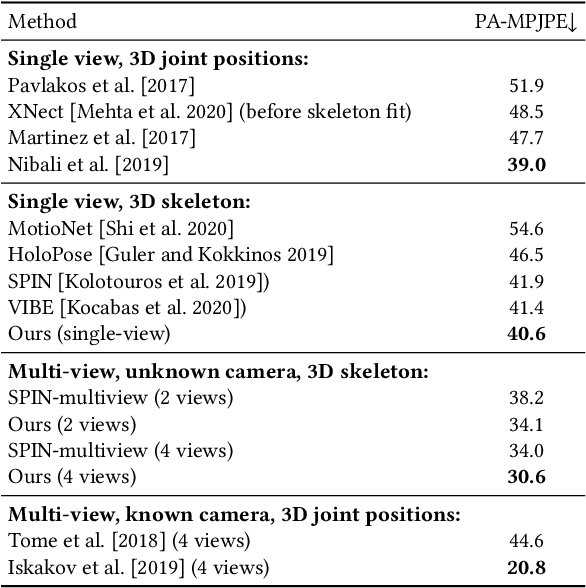

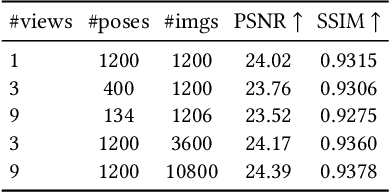
While deep learning has reshaped the classical motion capture pipeline, generative, analysis-by-synthesis elements are still in use to recover fine details if a high-quality 3D model of the user is available. Unfortunately, obtaining such a model for every user a priori is challenging, time-consuming, and limits the application scenarios. We propose a novel test-time optimization approach for monocular motion capture that learns a volumetric body model of the user in a self-supervised manner. To this end, our approach combines the advantages of neural radiance fields with an articulated skeleton representation. Our proposed skeleton embedding serves as a common reference that links constraints across time, thereby reducing the number of required camera views from traditionally dozens of calibrated cameras, down to a single uncalibrated one. As a starting point, we employ the output of an off-the-shelf model that predicts the 3D skeleton pose. The volumetric body shape and appearance is then learned from scratch, while jointly refining the initial pose estimate. Our approach is self-supervised and does not require any additional ground truth labels for appearance, pose, or 3D shape. We demonstrate that our novel combination of a discriminative pose estimation technique with surface-free analysis-by-synthesis outperforms purely discriminative monocular pose estimation approaches and generalizes well to multiple views.
3D Photography using Context-aware Layered Depth Inpainting
Apr 14, 2020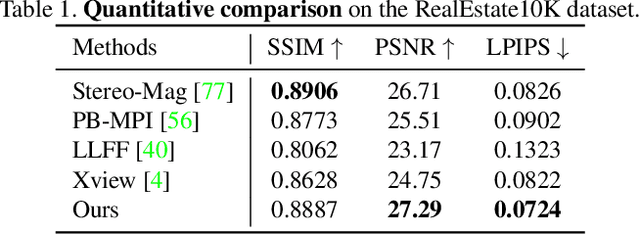
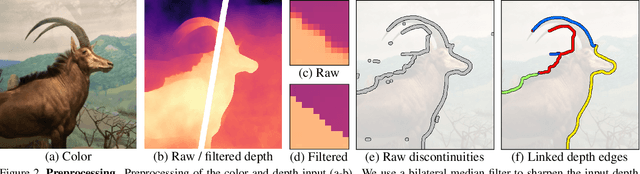

We propose a method for converting a single RGB-D input image into a 3D photo - a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts compared with the state of the arts.
Graph Generation with Variational Recurrent Neural Network
Oct 02, 2019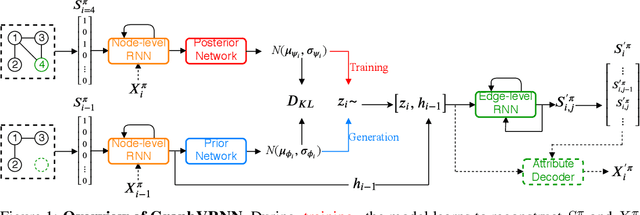
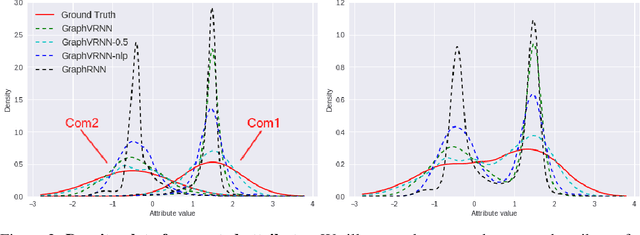
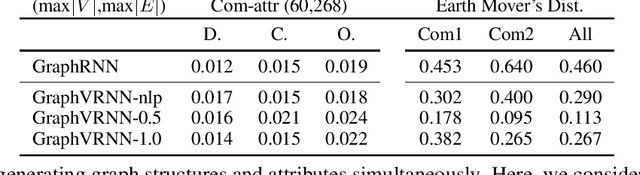

Generating graph structures is a challenging problem due to the diverse representations and complex dependencies among nodes. In this paper, we introduce Graph Variational Recurrent Neural Network (GraphVRNN), a probabilistic autoregressive model for graph generation. Through modeling the latent variables of graph data, GraphVRNN can capture the joint distributions of graph structures and the underlying node attributes. We conduct experiments on the proposed GraphVRNN in both graph structure learning and attribute generation tasks. The evaluation results show that the variational component allows our network to model complicated distributions, as well as generate plausible structures and node attributes.
Virtual-to-Real: Learning to Control in Visual Semantic Segmentation
Oct 28, 2018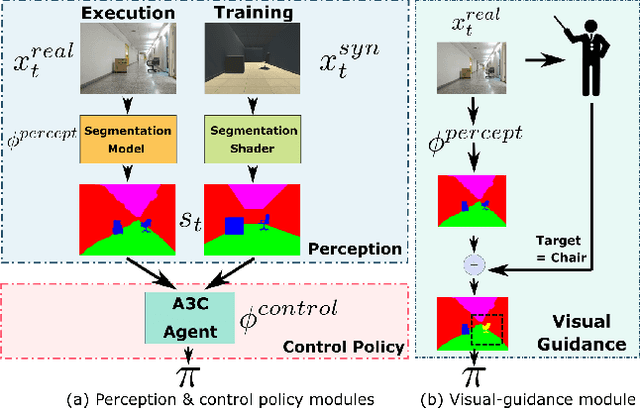



Collecting training data from the physical world is usually time-consuming and even dangerous for fragile robots, and thus, recent advances in robot learning advocate the use of simulators as the training platform. Unfortunately, the reality gap between synthetic and real visual data prohibits direct migration of the models trained in virtual worlds to the real world. This paper proposes a modular architecture for tackling the virtual-to-real problem. The proposed architecture separates the learning model into a perception module and a control policy module, and uses semantic image segmentation as the meta representation for relating these two modules. The perception module translates the perceived RGB image to semantic image segmentation. The control policy module is implemented as a deep reinforcement learning agent, which performs actions based on the translated image segmentation. Our architecture is evaluated in an obstacle avoidance task and a target following task. Experimental results show that our architecture significantly outperforms all of the baseline methods in both virtual and real environments, and demonstrates a faster learning curve than them. We also present a detailed analysis for a variety of variant configurations, and validate the transferability of our modular architecture.
Diversity-Driven Exploration Strategy for Deep Reinforcement Learning
Oct 28, 2018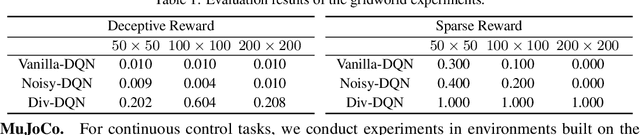


Efficient exploration remains a challenging research problem in reinforcement learning, especially when an environment contains large state spaces, deceptive local optima, or sparse rewards. To tackle this problem, we present a diversity-driven approach for exploration, which can be easily combined with both off- and on-policy reinforcement learning algorithms. We show that by simply adding a distance measure to the loss function, the proposed methodology significantly enhances an agent's exploratory behaviors, and thus preventing the policy from being trapped in local optima. We further propose an adaptive scaling method for stabilizing the learning process. Our experimental results in Atari 2600 show that our method outperforms baseline approaches in several tasks in terms of mean scores and exploration efficiency.
A Deep Policy Inference Q-Network for Multi-Agent Systems
Apr 09, 2018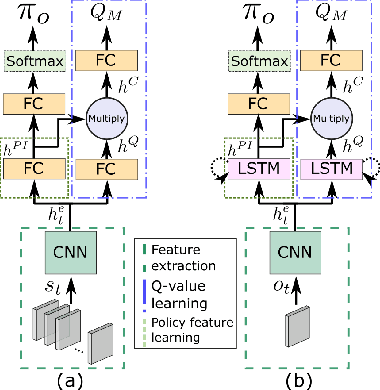
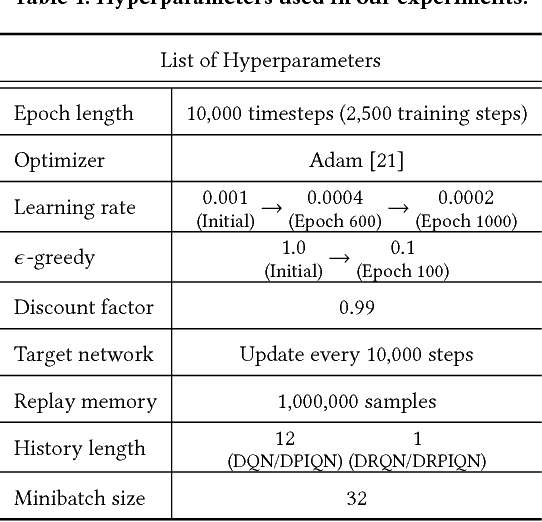
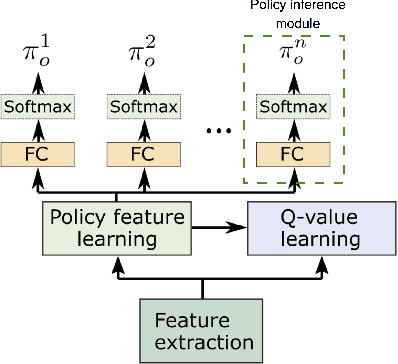
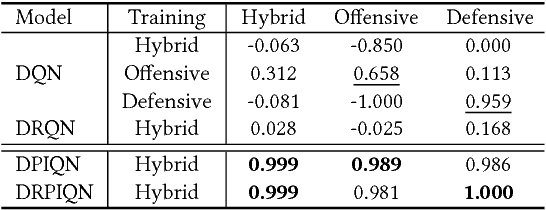
We present DPIQN, a deep policy inference Q-network that targets multi-agent systems composed of controllable agents, collaborators, and opponents that interact with each other. We focus on one challenging issue in such systems---modeling agents with varying strategies---and propose to employ "policy features" learned from raw observations (e.g., raw images) of collaborators and opponents by inferring their policies. DPIQN incorporates the learned policy features as a hidden vector into its own deep Q-network (DQN), such that it is able to predict better Q values for the controllable agents than the state-of-the-art deep reinforcement learning models. We further propose an enhanced version of DPIQN, called deep recurrent policy inference Q-network (DRPIQN), for handling partial observability. Both DPIQN and DRPIQN are trained by an adaptive training procedure, which adjusts the network's attention to learn the policy features and its own Q-values at different phases of the training process. We present a comprehensive analysis of DPIQN and DRPIQN, and highlight their effectiveness and generalizability in various multi-agent settings. Our models are evaluated in a classic soccer game involving both competitive and collaborative scenarios. Experimental results performed on 1 vs. 1 and 2 vs. 2 games show that DPIQN and DRPIQN demonstrate superior performance to the baseline DQN and deep recurrent Q-network (DRQN) models. We also explore scenarios in which collaborators or opponents dynamically change their policies, and show that DPIQN and DRPIQN do lead to better overall performance in terms of stability and mean scores.