 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering
Paper and Code
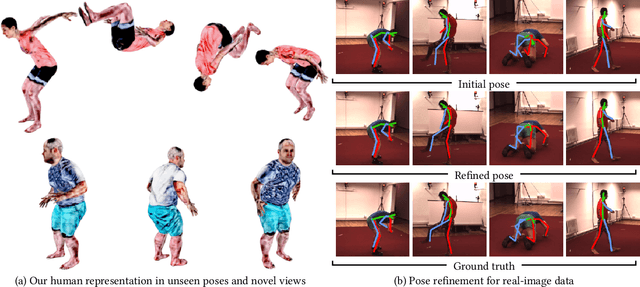
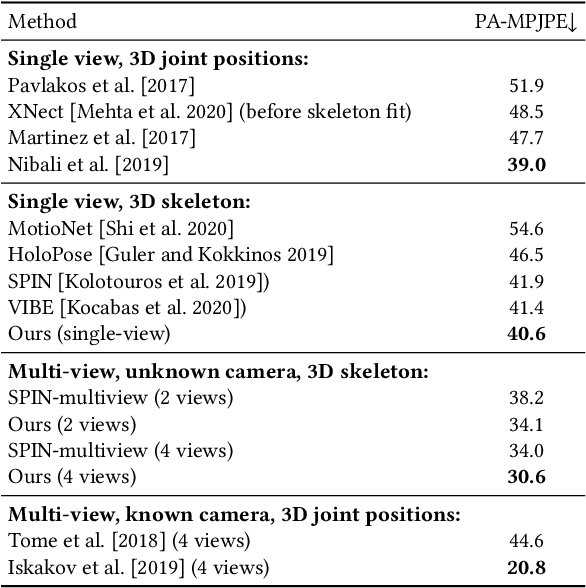

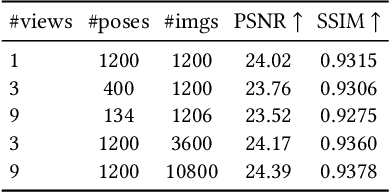
While deep learning has reshaped the classical motion capture pipeline, generative, analysis-by-synthesis elements are still in use to recover fine details if a high-quality 3D model of the user is available. Unfortunately, obtaining such a model for every user a priori is challenging, time-consuming, and limits the application scenarios. We propose a novel test-time optimization approach for monocular motion capture that learns a volumetric body model of the user in a self-supervised manner. To this end, our approach combines the advantages of neural radiance fields with an articulated skeleton representation. Our proposed skeleton embedding serves as a common reference that links constraints across time, thereby reducing the number of required camera views from traditionally dozens of calibrated cameras, down to a single uncalibrated one. As a starting point, we employ the output of an off-the-shelf model that predicts the 3D skeleton pose. The volumetric body shape and appearance is then learned from scratch, while jointly refining the initial pose estimate. Our approach is self-supervised and does not require any additional ground truth labels for appearance, pose, or 3D shape. We demonstrate that our novel combination of a discriminative pose estimation technique with surface-free analysis-by-synthesis outperforms purely discriminative monocular pose estimation approaches and generalizes well to multiple views.