 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinauralFlow: A Causal and Streamable Approach for High-Quality Binaural Speech Synthesis with Flow Matching Models
May 28, 2025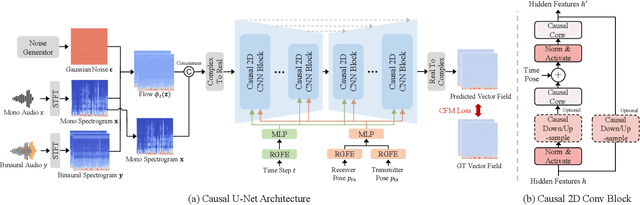
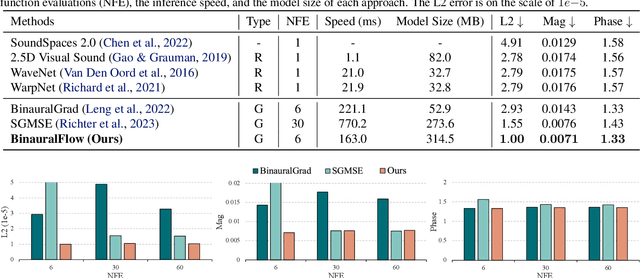
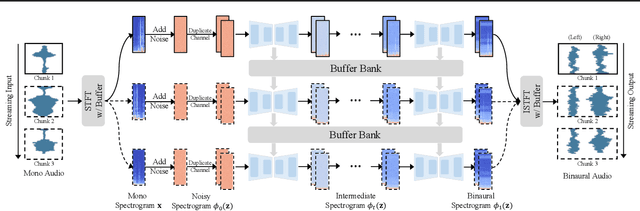
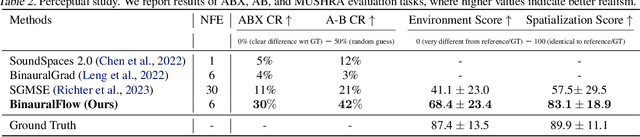
Binaural rendering aims to synthesize binaural audio that mimics natural hearing based on a mono audio and the locations of the speaker and listener. Although many methods have been proposed to solve this problem, they struggle with rendering quality and streamable inference. Synthesizing high-quality binaural audio that is indistinguishable from real-world recordings requires precise modeling of binaural cues, room reverb, and ambient sounds. Additionally, real-world applications demand streaming inference. To address these challenges, we propose a flow matching based streaming binaural speech synthesis framework called BinauralFlow. We consider binaural rendering to be a generation problem rather than a regression problem and design a conditional flow matching model to render high-quality audio. Moreover, we design a causal U-Net architecture that estimates the current audio frame solely based on past information to tailor generative models for streaming inference. Finally, we introduce a continuous inference pipeline incorporating streaming STFT/ISTFT operations, a buffer bank, a midpoint solver, and an early skip schedule to improve rendering continuity and speed. Quantitative and qualitative evaluations demonstrate the superiority of our method over SOTA approaches. A perceptual study further reveals that our model is nearly indistinguishable from real-world recordings, with a $42\%$ confusion rate.
SqueezeMe: Efficient Gaussian Avatars for VR
Dec 19, 2024



Gaussian Splatting has enabled real-time 3D human avatars with unprecedented levels of visual quality. While previous methods require a desktop GPU for real-time inference of a single avatar, we aim to squeeze multiple Gaussian avatars onto a portable virtual reality headset with real-time drivable inference. We begin by training a previous work, Animatable Gaussians, on a high quality dataset captured with 512 cameras. The Gaussians are animated by controlling base set of Gaussians with linear blend skinning (LBS) motion and then further adjusting the Gaussians with a neural network decoder to correct their appearance. When deploying the model on a Meta Quest 3 VR headset, we find two major computational bottlenecks: the decoder and the rendering. To accelerate the decoder, we train the Gaussians in UV-space instead of pixel-space, and we distill the decoder to a single neural network layer. Further, we discover that neighborhoods of Gaussians can share a single corrective from the decoder, which provides an additional speedup. To accelerate the rendering, we develop a custom pipeline in Vulkan that runs on the mobile GPU. Putting it all together, we run 3 Gaussian avatars concurrently at 72 FPS on a VR headset. Demo videos are at https://forresti.github.io/squeezeme.
Scaling Neural Face Synthesis to High FPS and Low Latency by Neural Caching
Nov 10, 2022Recent neural rendering approaches greatly improve image quality, reaching near photorealism. However, the underlying neural networks have high runtime, precluding telepresence and virtual reality applications that require high resolution at low latency. The sequential dependency of layers in deep networks makes their optimization difficult. We break this dependency by caching information from the previous frame to speed up the processing of the current one with an implicit warp. The warping with a shallow network reduces latency and the caching operations can further be parallelized to improve the frame rate. In contrast to existing temporal neural networks, ours is tailored for the task of rendering novel views of faces by conditioning on the change of the underlying surface mesh. We test the approach on view-dependent rendering of 3D portrait avatars, as needed for telepresence, on established benchmark sequences. Warping reduces latency by 70$\%$ (from 49.4ms to 14.9ms on commodity GPUs) and scales frame rates accordingly over multiple GPUs while reducing image quality by only 1$\%$, making it suitable as part of end-to-end view-dependent 3D teleconferencing applications. Our project page can be found at: https://yu-frank.github.io/lowlatency/.
A-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering
Feb 11, 2021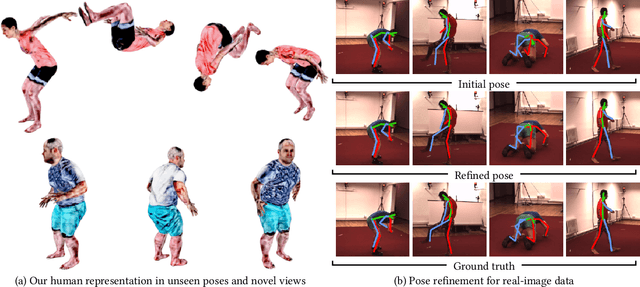
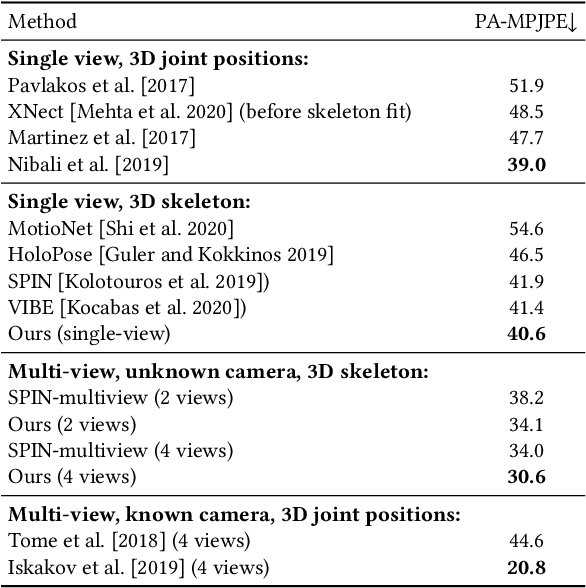

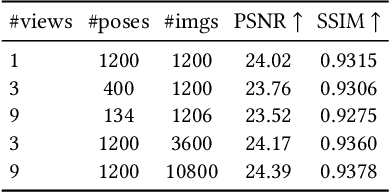
While deep learning has reshaped the classical motion capture pipeline, generative, analysis-by-synthesis elements are still in use to recover fine details if a high-quality 3D model of the user is available. Unfortunately, obtaining such a model for every user a priori is challenging, time-consuming, and limits the application scenarios. We propose a novel test-time optimization approach for monocular motion capture that learns a volumetric body model of the user in a self-supervised manner. To this end, our approach combines the advantages of neural radiance fields with an articulated skeleton representation. Our proposed skeleton embedding serves as a common reference that links constraints across time, thereby reducing the number of required camera views from traditionally dozens of calibrated cameras, down to a single uncalibrated one. As a starting point, we employ the output of an off-the-shelf model that predicts the 3D skeleton pose. The volumetric body shape and appearance is then learned from scratch, while jointly refining the initial pose estimate. Our approach is self-supervised and does not require any additional ground truth labels for appearance, pose, or 3D shape. We demonstrate that our novel combination of a discriminative pose estimation technique with surface-free analysis-by-synthesis outperforms purely discriminative monocular pose estimation approaches and generalizes well to multiple views.
PCLs: Geometry-aware Neural Reconstruction of 3D Pose with Perspective Crop Layers
Nov 27, 2020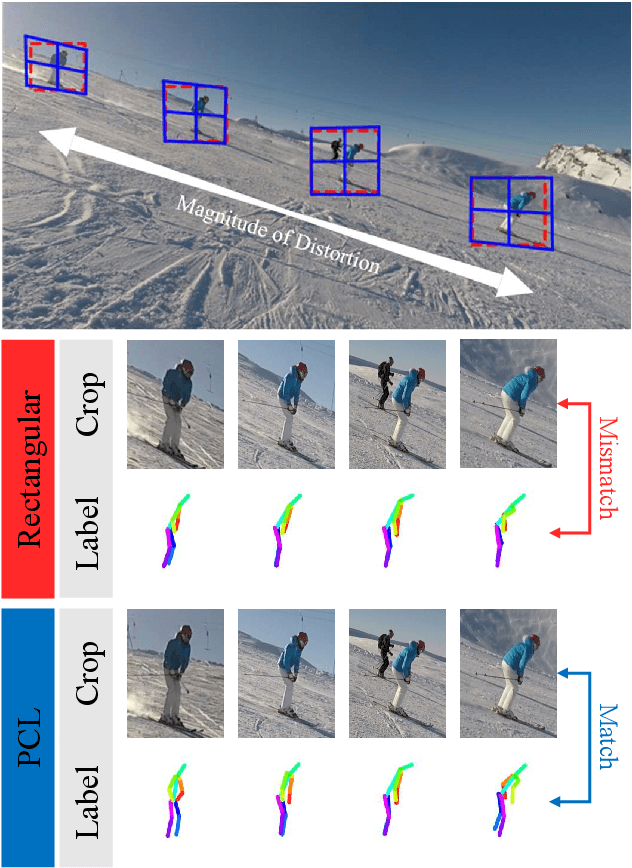
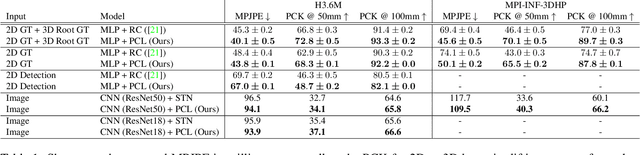


Local processing is an essential feature of CNNs and other neural network architectures - it is one of the reasons why they work so well on images where relevant information is, to a large extent, local. However, perspective effects stemming from the projection in a conventional camera vary for different global positions in the image. We introduce Perspective Crop Layers (PCLs) - a form of perspective crop of the region of interest based on the camera geometry - and show that accounting for the perspective consistently improves the accuracy of state-of-the-art 3D pose reconstruction methods. PCLs are modular neural network layers, which, when inserted into existing CNN and MLP architectures, deterministically remove the location-dependent perspective effects while leaving end-to-end training and the number of parameters of the underlying neural network unchanged. We demonstrate that PCL leads to improved 3D human pose reconstruction accuracy for CNN architectures that use cropping operations, such as spatial transformer networks (STN), and, somewhat surprisingly, MLPs used for 2D-to-3D keypoint lifting. Our conclusion is that it is important to utilize camera calibration information when available, for classical and deep-learning-based computer vision alike. PCL offers an easy way to improve the accuracy of existing 3D reconstruction networks by making them geometry-aware.
Few-shot Scene-adaptive Anomaly Detection
Jul 15, 2020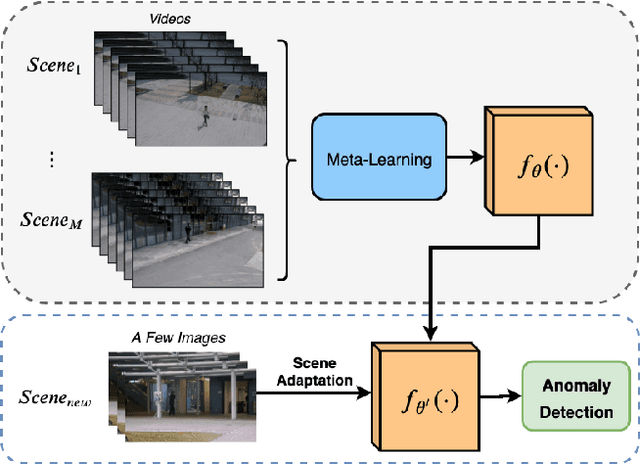
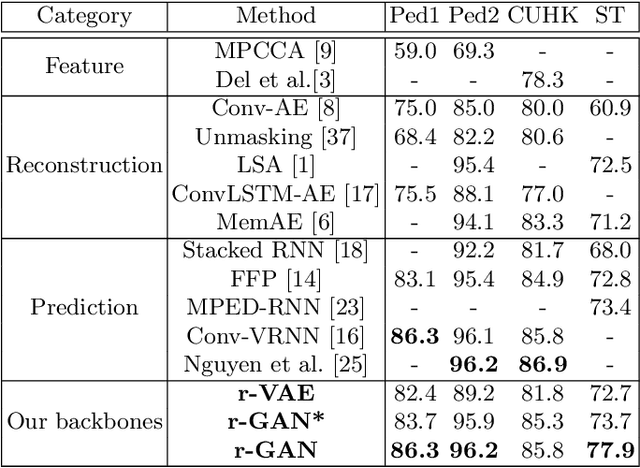
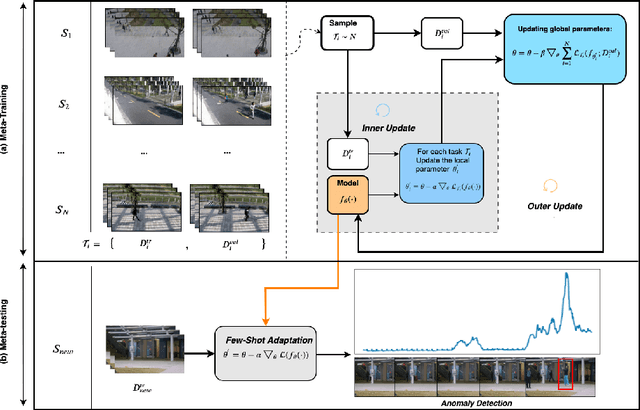
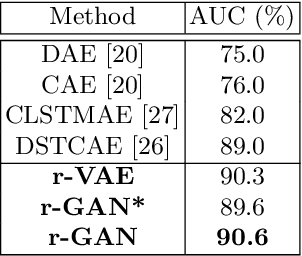
We address the problem of anomaly detection in videos. The goal is to identify unusual behaviours automatically by learning exclusively from normal videos. Most existing approaches are usually data-hungry and have limited generalization abilities. They usually need to be trained on a large number of videos from a target scene to achieve good results in that scene. In this paper, we propose a novel few-shot scene-adaptive anomaly detection problem to address the limitations of previous approaches. Our goal is to learn to detect anomalies in a previously unseen scene with only a few frames. A reliable solution for this new problem will have huge potential in real-world applications since it is expensive to collect a massive amount of data for each target scene. We propose a meta-learning based approach for solving this new problem; extensive experimental results demonstrate the effectiveness of our proposed method.