 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCrowd: Unlabeled Scene Adaptation for Crowd Counting
Oct 23, 2020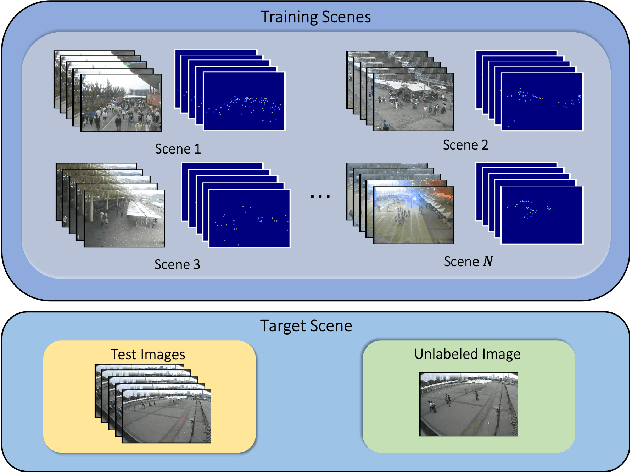
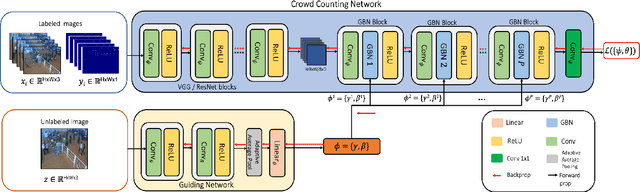
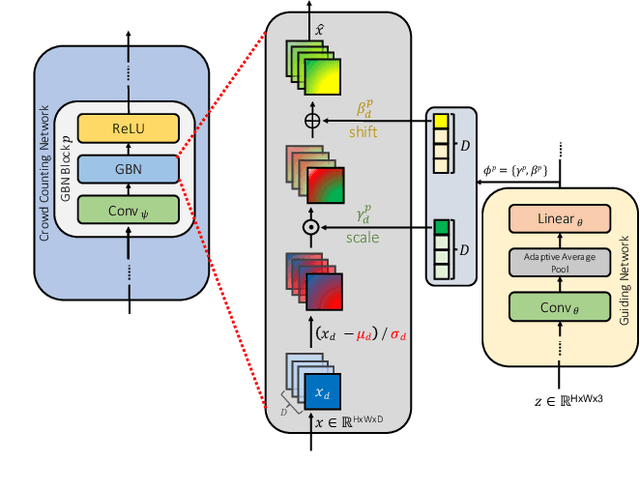

We address the problem of image-based crowd counting. In particular, we propose a new problem called unlabeled scene adaptive crowd counting. Given a new target scene, we would like to have a crowd counting model specifically adapted to this particular scene based on the target data that capture some information about the new scene. In this paper, we propose to use one or more unlabeled images from the target scene to perform the adaptation. In comparison with the existing problem setups (e.g. fully supervised), our proposed problem setup is closer to the real-world applications of crowd counting systems. We introduce a novel AdaCrowd framework to solve this problem. Our framework consists of a crowd counting network and a guiding network. The guiding network predicts some parameters in the crowd counting network based on the unlabeled images from a particular scene. This allows our model to adapt to different target scenes. The experimental results on several challenging benchmark datasets demonstrate the effectiveness of our proposed approach compared with other alternative methods.
Sentence Guided Temporal Modulation for Dynamic Video Thumbnail Generation
Aug 31, 2020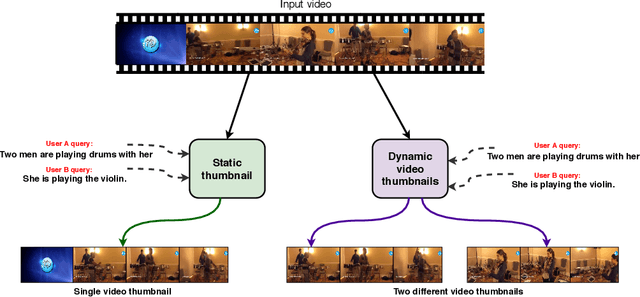
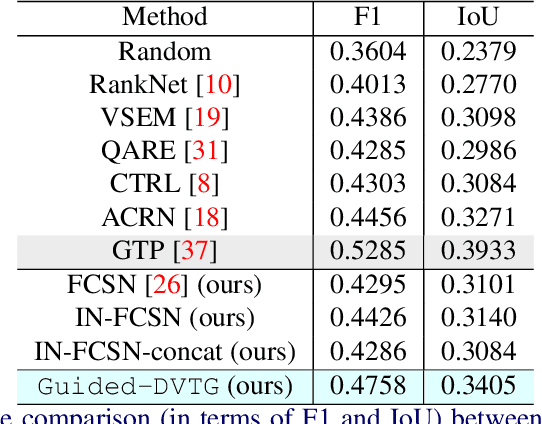
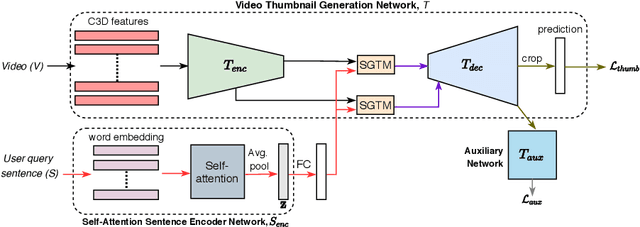

We consider the problem of sentence specified dynamic video thumbnail generation. Given an input video and a user query sentence, the goal is to generate a video thumbnail that not only provides the preview of the video content, but also semantically corresponds to the sentence. In this paper, we propose a sentence guided temporal modulation (SGTM) mechanism that utilizes the sentence embedding to modulate the normalized temporal activations of the video thumbnail generation network. Unlike the existing state-of-the-art method that uses recurrent architectures, we propose a non-recurrent framework that is simple and allows much more parallelization. Extensive experiments and analysis on a large-scale dataset demonstrate the effectiveness of our framework.
Adaptive Video Highlight Detection by Learning from User History
Jul 19, 2020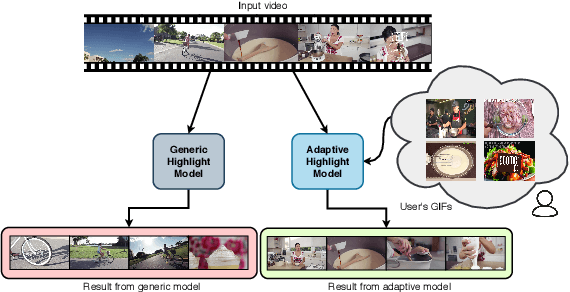
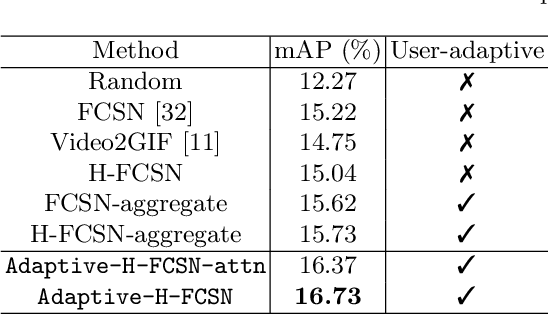
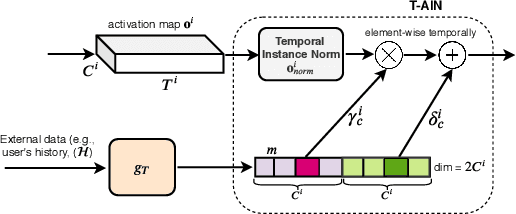

Recently, there is an increasing interest in highlight detection research where the goal is to create a short duration video from a longer video by extracting its interesting moments. However, most existing methods ignore the fact that the definition of video highlight is highly subjective. Different users may have different preferences of highlight for the same input video. In this paper, we propose a simple yet effective framework that learns to adapt highlight detection to a user by exploiting the user's history in the form of highlights that the user has previously created. Our framework consists of two sub-networks: a fully temporal convolutional highlight detection network $H$ that predicts highlight for an input video and a history encoder network $M$ for user history. We introduce a newly designed temporal-adaptive instance normalization (T-AIN) layer to $H$ where the two sub-networks interact with each other. T-AIN has affine parameters that are predicted from $M$ based on the user history and is responsible for the user-adaptive signal to $H$. Extensive experiments on a large-scale dataset show that our framework can make more accurate and user-specific highlight predictions.
Few-shot Scene-adaptive Anomaly Detection
Jul 15, 2020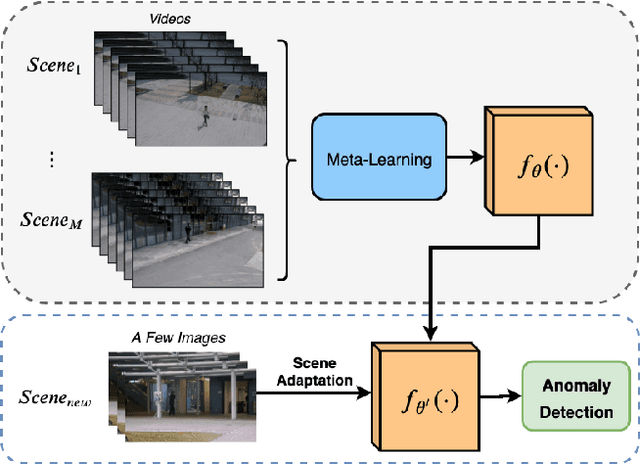
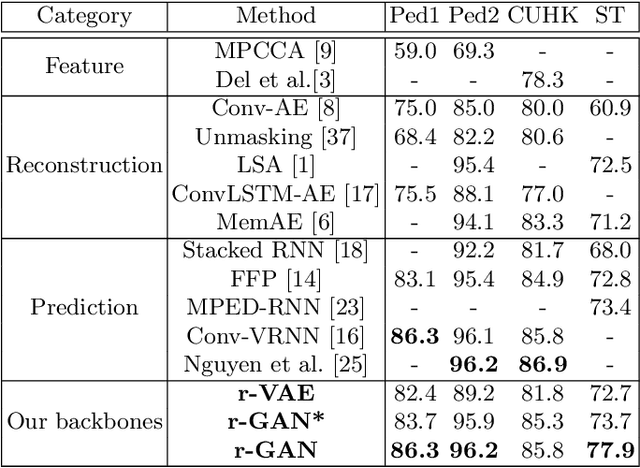
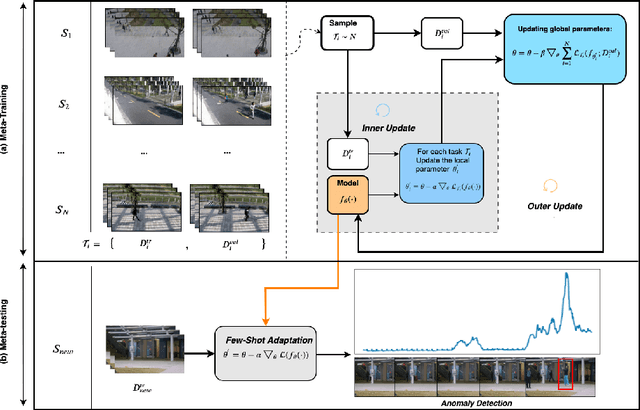
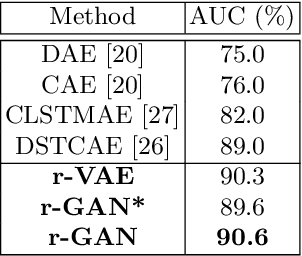
We address the problem of anomaly detection in videos. The goal is to identify unusual behaviours automatically by learning exclusively from normal videos. Most existing approaches are usually data-hungry and have limited generalization abilities. They usually need to be trained on a large number of videos from a target scene to achieve good results in that scene. In this paper, we propose a novel few-shot scene-adaptive anomaly detection problem to address the limitations of previous approaches. Our goal is to learn to detect anomalies in a previously unseen scene with only a few frames. A reliable solution for this new problem will have huge potential in real-world applications since it is expensive to collect a massive amount of data for each target scene. We propose a meta-learning based approach for solving this new problem; extensive experimental results demonstrate the effectiveness of our proposed method.
Few-Shot Scene Adaptive Crowd Counting Using Meta-Learning
Feb 01, 2020
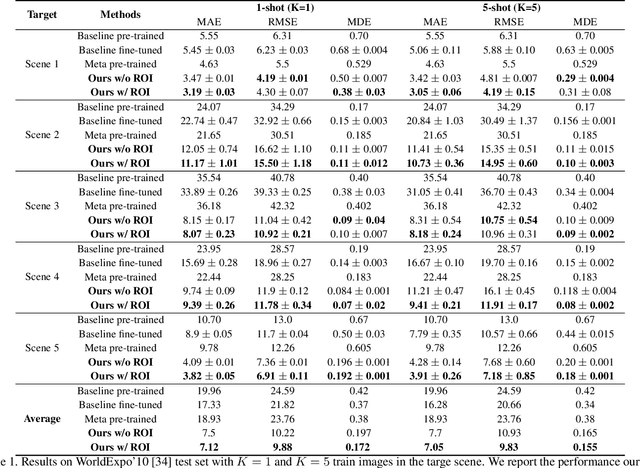
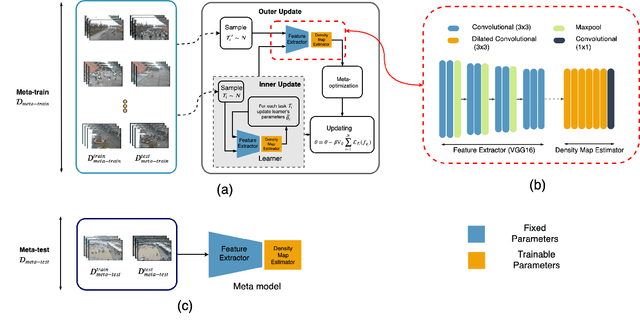

We consider the problem of few-shot scene adaptive crowd counting. Given a target camera scene, our goal is to adapt a model to this specific scene with only a few labeled images of that scene. The solution to this problem has potential applications in numerous real-world scenarios, where we ideally like to deploy a crowd counting model specially adapted to a target camera. We accomplish this challenge by taking inspiration from the recently introduced learning-to-learn paradigm in the context of few-shot regime. In training, our method learns the model parameters in a way that facilitates the fast adaptation to the target scene. At test time, given a target scene with a small number of labeled data, our method quickly adapts to that scene with a few gradient updates to the learned parameters. Our extensive experimental results show that the proposed approach outperforms other alternatives in few-shot scene adaptive crowd counting.
Future Frame Prediction Using Convolutional VRNN for Anomaly Detection
Oct 18, 2019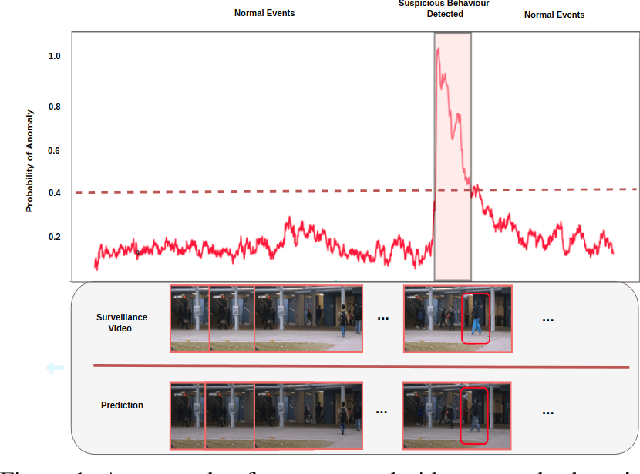
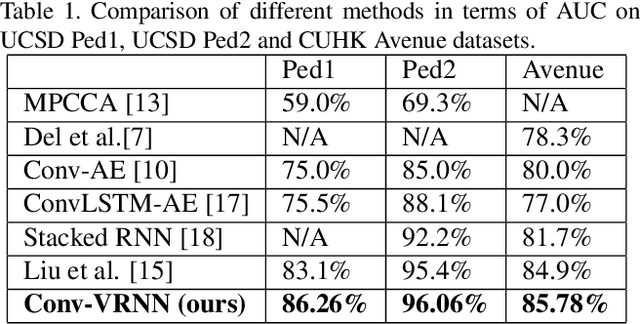
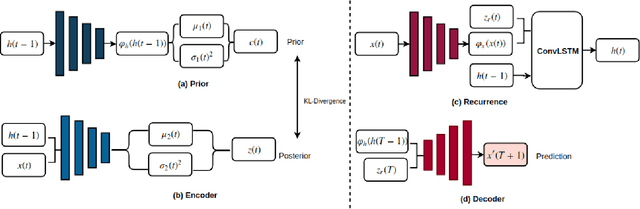
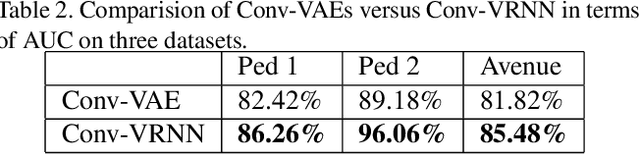
Anomaly detection in videos aims at reporting anything that does not conform the normal behaviour or distribution. However, due to the sparsity of abnormal video clips in real life, collecting annotated data for supervised learning is exceptionally cumbersome. Inspired by the practicability of generative models for semi-supervised learning, we propose a novel sequential generative model based on variational autoencoder (VAE) for future frame prediction with convolutional LSTM (ConvLSTM). To the best of our knowledge, this is the first work that considers temporal information in future frame prediction based anomaly detection framework from the model perspective. Our experiments demonstrate that our approach is superior to the state-of-the-art methods on three benchmark datasets.