 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Motion-Focused Tokenization for Effective and Efficient Video Unsupervised Domain Adaptation
Apr 10, 2026Video Unsupervised Domain Adaptation (VUDA) poses a significant challenge in action recognition, requiring the adaptation of a model from a labeled source domain to an unlabeled target domain. Despite recent advances, existing VUDA methods often fall short of fully supervised performance, a key reason being the prevalence of static and uninformative backgrounds that exacerbate domain shifts. Additionally, prior approaches largely overlook computational efficiency, limiting real-world adoption. To address these issues, we propose Learnable Motion-Focused Tokenization (LMFT) for VUDA. LMFT tokenizes video frames into patch tokens and learns to discard low-motion, redundant tokens, primarily corresponding to background regions, while retaining motion-rich, action-relevant tokens for adaptation. Extensive experiments on three standard VUDA benchmarks across 21 domain adaptation settings show that our VUDA framework with LMFT achieves state-of-the-art performance while significantly reducing computational overhead. LMFT thus enables VUDA that is both effective and computationally efficient.
A Metamorphic Testing Perspective on Knowledge Distillation for Language Models of Code: Does the Student Deeply Mimic the Teacher?
Nov 07, 2025
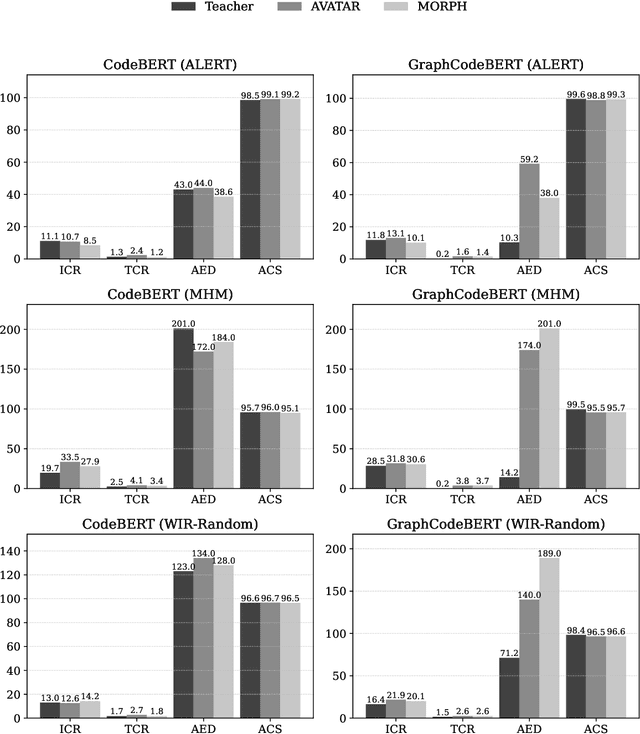
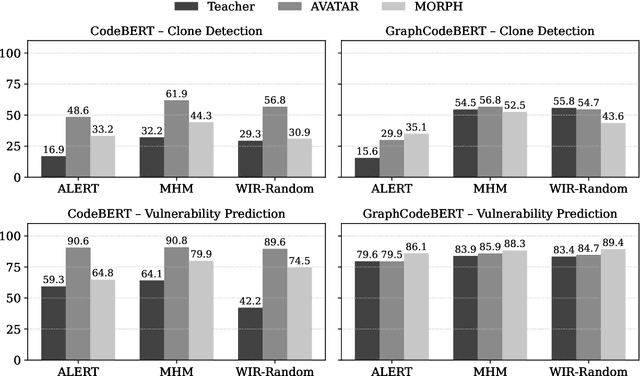

Transformer-based language models of code have achieved state-of-the-art performance across a wide range of software analytics tasks, but their practical deployment remains limited due to high computational costs, slow inference speeds, and significant environmental impact. To address these challenges, recent research has increasingly explored knowledge distillation as a method for compressing a large language model of code (the teacher) into a smaller model (the student) while maintaining performance. However, the degree to which a student model deeply mimics the predictive behavior and internal representations of its teacher remains largely unexplored, as current accuracy-based evaluation provides only a surface-level view of model quality and often fails to capture more profound discrepancies in behavioral fidelity between the teacher and student models. To address this gap, we empirically show that the student model often fails to deeply mimic the teacher model, resulting in up to 285% greater performance drop under adversarial attacks, which is not captured by traditional accuracy-based evaluation. Therefore, we propose MetaCompress, a metamorphic testing framework that systematically evaluates behavioral fidelity by comparing the outputs of teacher and student models under a set of behavior-preserving metamorphic relations. We evaluate MetaCompress on two widely studied tasks, using compressed versions of popular language models of code, obtained via three different knowledge distillation techniques: Compressor, AVATAR, and MORPH. The results show that MetaCompress identifies up to 62% behavioral discrepancies in student models, underscoring the need for behavioral fidelity evaluation within the knowledge distillation pipeline and establishing MetaCompress as a practical framework for testing compressed language models of code derived through knowledge distillation.
Test-Time Adaptation for Video Highlight Detection Using Meta-Auxiliary Learning and Cross-Modality Hallucinations
Aug 06, 2025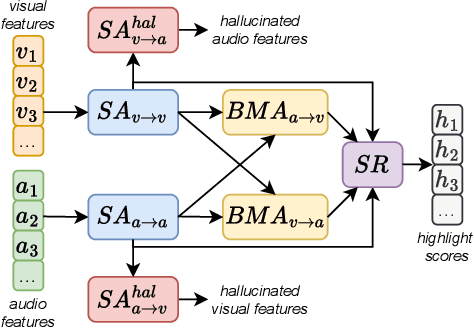
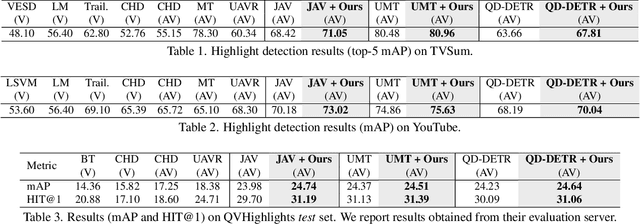
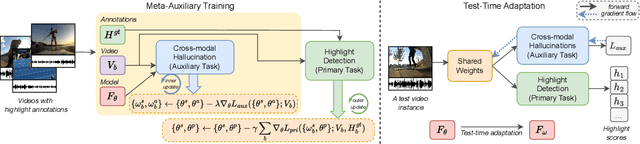
Existing video highlight detection methods, although advanced, struggle to generalize well to all test videos. These methods typically employ a generic highlight detection model for each test video, which is suboptimal as it fails to account for the unique characteristics and variations of individual test videos. Such fixed models do not adapt to the diverse content, styles, or audio and visual qualities present in new, unseen test videos, leading to reduced highlight detection performance. In this paper, we propose Highlight-TTA, a test-time adaptation framework for video highlight detection that addresses this limitation by dynamically adapting the model during testing to better align with the specific characteristics of each test video, thereby improving generalization and highlight detection performance. Highlight-TTA is jointly optimized with an auxiliary task, cross-modality hallucinations, alongside the primary highlight detection task. We utilize a meta-auxiliary training scheme to enable effective adaptation through the auxiliary task while enhancing the primary task. During testing, we adapt the trained model using the auxiliary task on the test video to further enhance its highlight detection performance. Extensive experiments with three state-of-the-art highlight detection models and three benchmark datasets show that the introduction of Highlight-TTA to these models improves their performance, yielding superior results.
Unsupervised Video Highlight Detection by Learning from Audio and Visual Recurrence
Jul 18, 2024

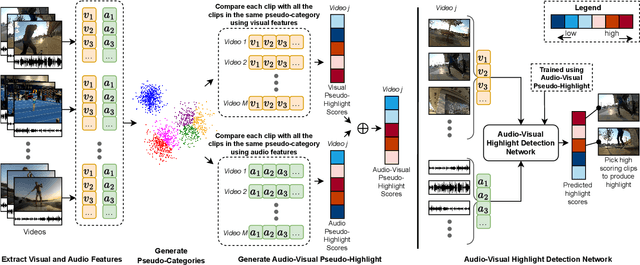
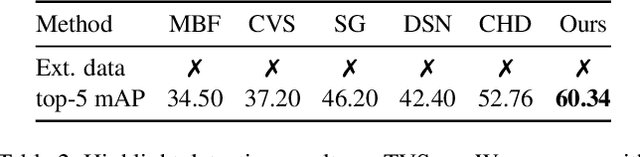
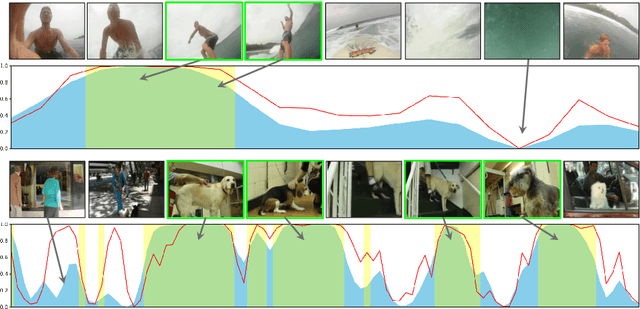
With the exponential growth of video content, the need for automated video highlight detection to extract key moments or highlights from lengthy videos has become increasingly pressing. This technology has the potential to significantly enhance user experiences by allowing quick access to relevant content across diverse domains. Existing methods typically rely either on expensive manually labeled frame-level annotations, or on a large external dataset of videos for weak supervision through category information. To overcome this, we focus on unsupervised video highlight detection, eliminating the need for manual annotations. We propose an innovative unsupervised approach which capitalizes on the premise that significant moments tend to recur across multiple videos of the similar category in both audio and visual modalities. Surprisingly, audio remains under-explored, especially in unsupervised algorithms, despite its potential to detect key moments. Through a clustering technique, we identify pseudo-categories of videos and compute audio pseudo-highlight scores for each video by measuring the similarities of audio features among audio clips of all the videos within each pseudo-category. Similarly, we also compute visual pseudo-highlight scores for each video using visual features. Subsequently, we combine audio and visual pseudo-highlights to create the audio-visual pseudo ground-truth highlight of each video for training an audio-visual highlight detection network. Extensive experiments and ablation studies on three highlight detection benchmarks showcase the superior performance of our method over prior work.
Improving LiDAR 3D Object Detection via Range-based Point Cloud Density Optimization
Jun 09, 2023In recent years, much progress has been made in LiDAR-based 3D object detection mainly due to advances in detector architecture designs and availability of large-scale LiDAR datasets. Existing 3D object detectors tend to perform well on the point cloud regions closer to the LiDAR sensor as opposed to on regions that are farther away. In this paper, we investigate this problem from the data perspective instead of detector architecture design. We observe that there is a learning bias in detection models towards the dense objects near the sensor and show that the detection performance can be improved by simply manipulating the input point cloud density at different distance ranges without modifying the detector architecture and without data augmentation. We propose a model-free point cloud density adjustment pre-processing mechanism that uses iterative MCMC optimization to estimate optimal parameters for altering the point density at different distance ranges. We conduct experiments using four state-of-the-art LiDAR 3D object detectors on two public LiDAR datasets, namely Waymo and ONCE. Our results demonstrate that our range-based point cloud density manipulation technique can improve the performance of the existing detectors, which in turn could potentially inspire future detector designs.
Domain Adaptation in 3D Object Detection with Gradual Batch Alternation Training
Oct 18, 2022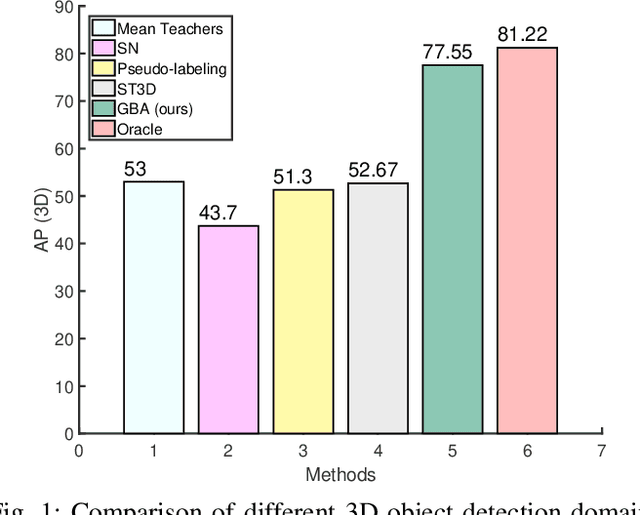
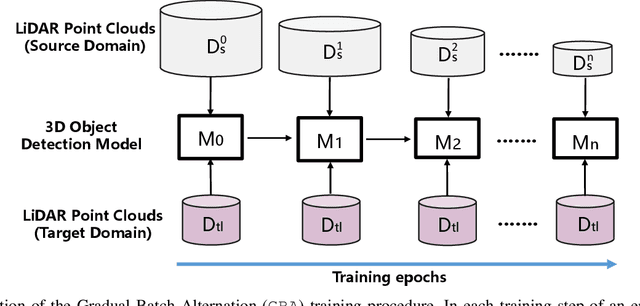
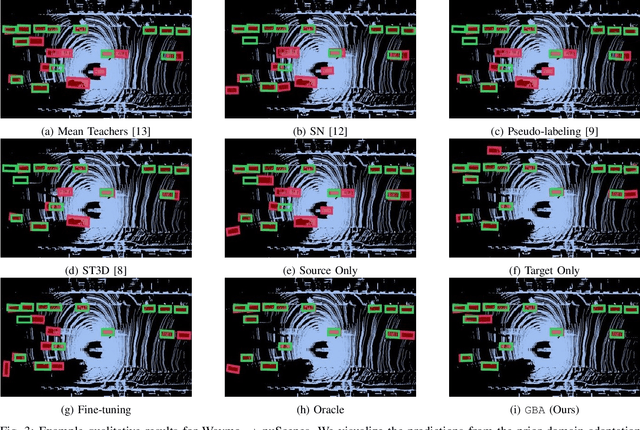
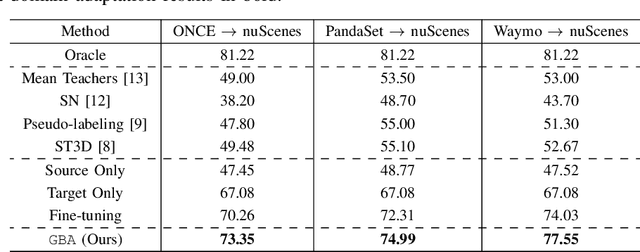
We consider the problem of domain adaptation in LiDAR-based 3D object detection. Towards this, we propose a simple yet effective training strategy called Gradual Batch Alternation that can adapt from a large labeled source domain to an insufficiently labeled target domain. The idea is to initiate the training with the batch of samples from the source and target domain data in an alternate fashion, but then gradually reduce the amount of the source domain data over time as the training progresses. This way the model slowly shifts towards the target domain and eventually better adapt to it. The domain adaptation experiments for 3D object detection on four benchmark autonomous driving datasets, namely ONCE, PandaSet, Waymo, and nuScenes, demonstrate significant performance gains over prior arts and strong baselines.
HYLDA: End-to-end Hybrid Learning Domain Adaptation for LiDAR Semantic Segmentation
Jan 14, 2022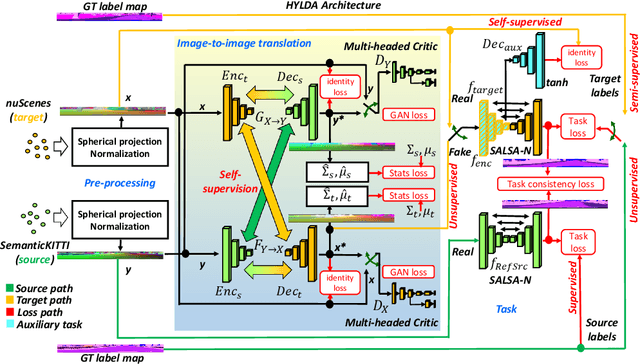
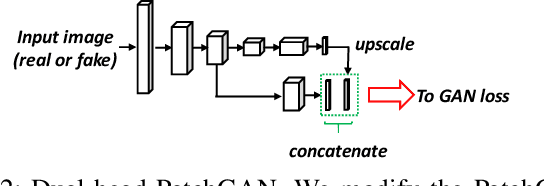

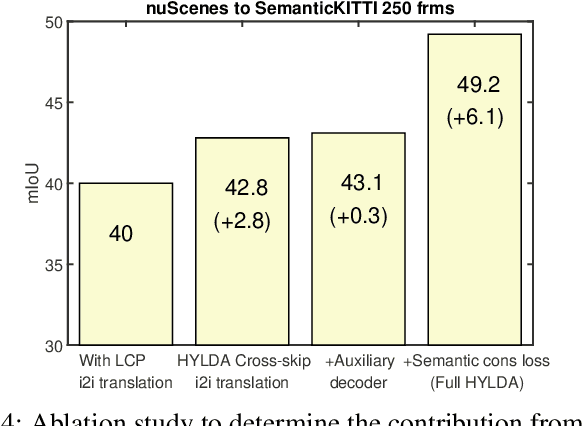
In this paper we address the problem of training a LiDAR semantic segmentation network using a fully-labeled source dataset and a target dataset that only has a small number of labels. To this end, we develop a novel image-to-image translation engine, and couple it with a LiDAR semantic segmentation network, resulting in an integrated domain adaptation architecture we call HYLDA. To train the system end-to-end, we adopt a diverse set of learning paradigms, including 1) self-supervision on a simple auxiliary reconstruction task, 2) semi-supervised training using a few available labeled target domain frames, and 3) unsupervised training on the fake translated images generated by the image-to-image translation stage, together with the labeled frames from the source domain. In the latter case, the semantic segmentation network participates in the updating of the image-to-image translation engine. We demonstrate experimentally that HYLDA effectively addresses the challenging problem of improving generalization on validation data from the target domain when only a few target labeled frames are available for training. We perform an extensive evaluation where we compare HYLDA against strong baseline methods using two publicly available LiDAR semantic segmentation datasets.
Unsupervised Domain Adaptation in LiDAR Semantic Segmentation with Self-Supervision and Gated Adapters
Jul 20, 2021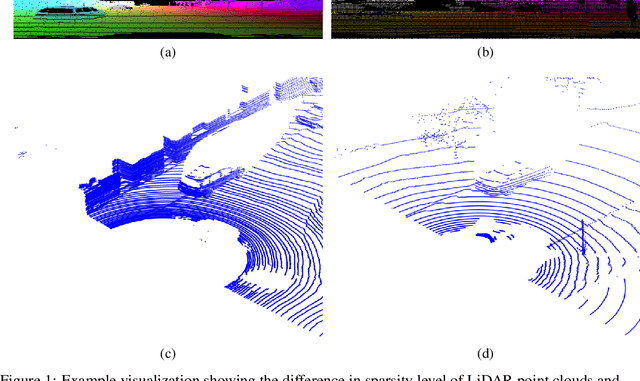
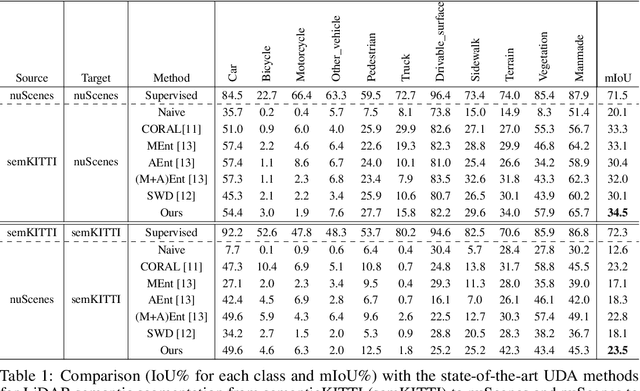
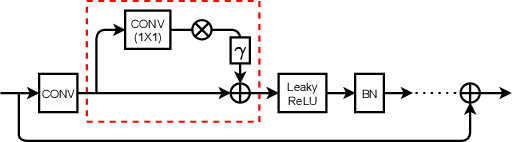
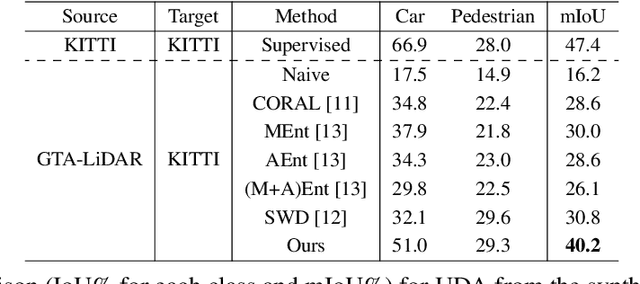
In this paper, we focus on a less explored, but more realistic and complex problem of domain adaptation in LiDAR semantic segmentation. There is a significant drop in performance of an existing segmentation model when training (source domain) and testing (target domain) data originate from different LiDAR sensors. To overcome this shortcoming, we propose an unsupervised domain adaptation framework that leverages unlabeled target domain data for self-supervision, coupled with an unpaired mask transfer strategy to mitigate the impact of domain shifts. Furthermore, we introduce gated adapter modules with a small number of parameters into the network to account for target domain-specific information. Experiments adapting from both real-to-real and synthetic-to-real LiDAR semantic segmentation benchmarks demonstrate the significant improvement over prior arts.
Referring Segmentation in Images and Videos with Cross-Modal Self-Attention Network
Feb 09, 2021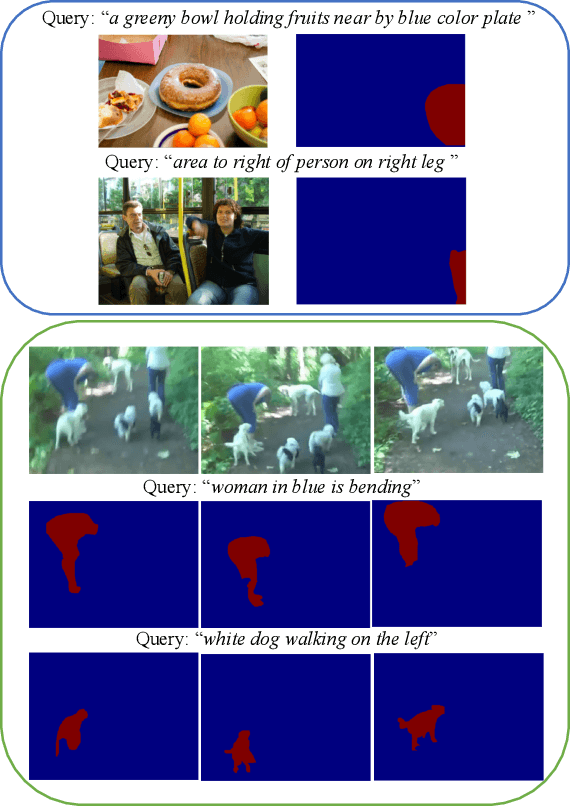

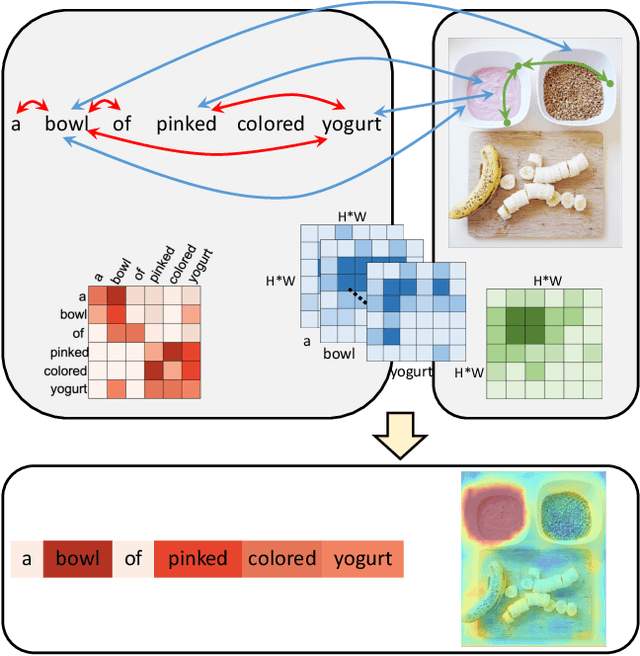
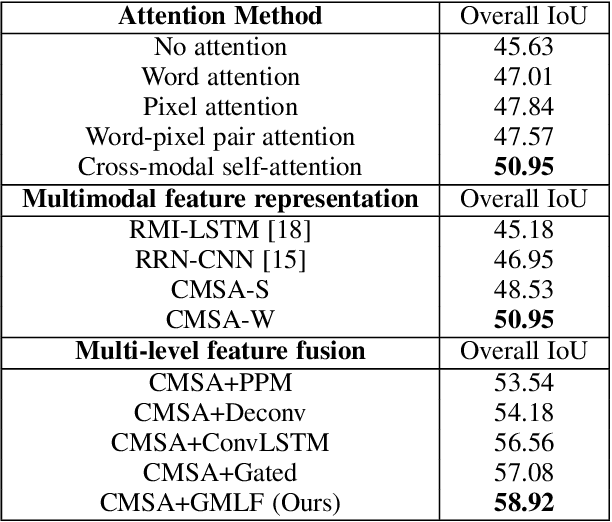
We consider the problem of referring segmentation in images and videos with natural language. Given an input image (or video) and a referring expression, the goal is to segment the entity referred by the expression in the image or video. In this paper, we propose a cross-modal self-attention (CMSA) module to utilize fine details of individual words and the input image or video, which effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the visual input. We further propose a gated multi-level fusion (GMLF) module to selectively integrate self-attentive cross-modal features corresponding to different levels of visual features. This module controls the feature fusion of information flow of features at different levels with high-level and low-level semantic information related to different attentive words. Besides, we introduce cross-frame self-attention (CFSA) module to effectively integrate temporal information in consecutive frames which extends our method in the case of referring segmentation in videos. Experiments on benchmark datasets of four referring image datasets and two actor and action video segmentation datasets consistently demonstrate that our proposed approach outperforms existing state-of-the-art methods.
AdaCrowd: Unlabeled Scene Adaptation for Crowd Counting
Oct 23, 2020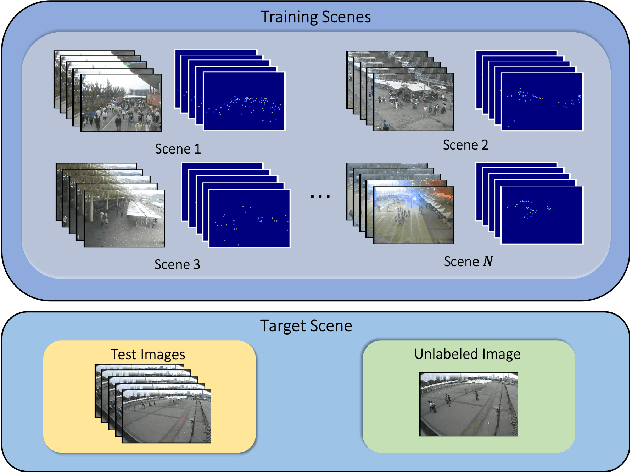
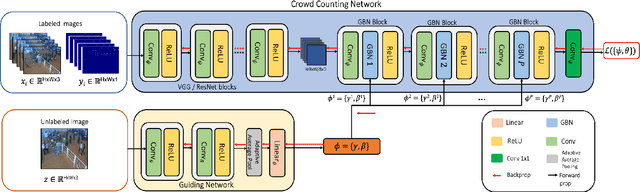
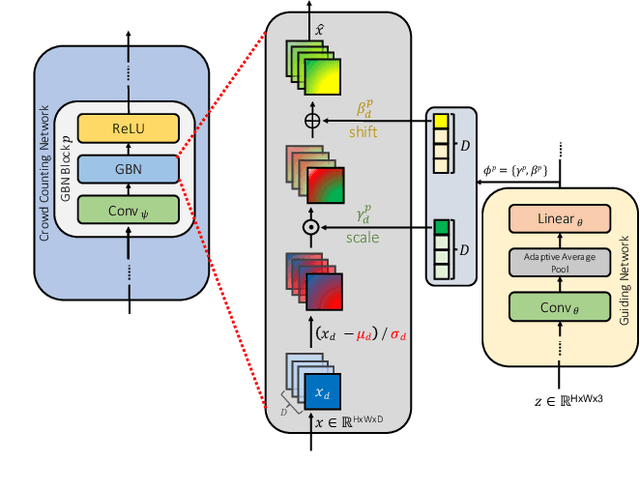

We address the problem of image-based crowd counting. In particular, we propose a new problem called unlabeled scene adaptive crowd counting. Given a new target scene, we would like to have a crowd counting model specifically adapted to this particular scene based on the target data that capture some information about the new scene. In this paper, we propose to use one or more unlabeled images from the target scene to perform the adaptation. In comparison with the existing problem setups (e.g. fully supervised), our proposed problem setup is closer to the real-world applications of crowd counting systems. We introduce a novel AdaCrowd framework to solve this problem. Our framework consists of a crowd counting network and a guiding network. The guiding network predicts some parameters in the crowd counting network based on the unlabeled images from a particular scene. This allows our model to adapt to different target scenes. The experimental results on several challenging benchmark datasets demonstrate the effectiveness of our proposed approach compared with other alternative methods.