 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Segmentation in Images and Videos with Cross-Modal Self-Attention Network
Paper and Code
Feb 09, 2021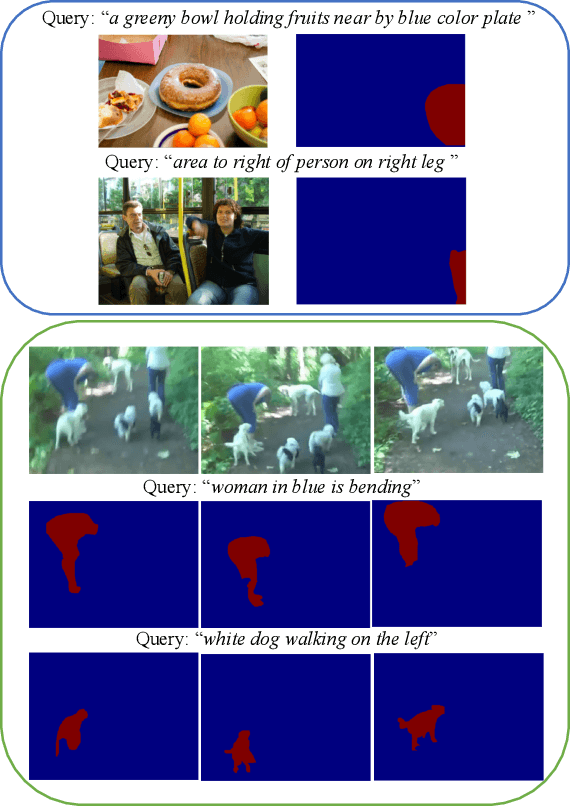

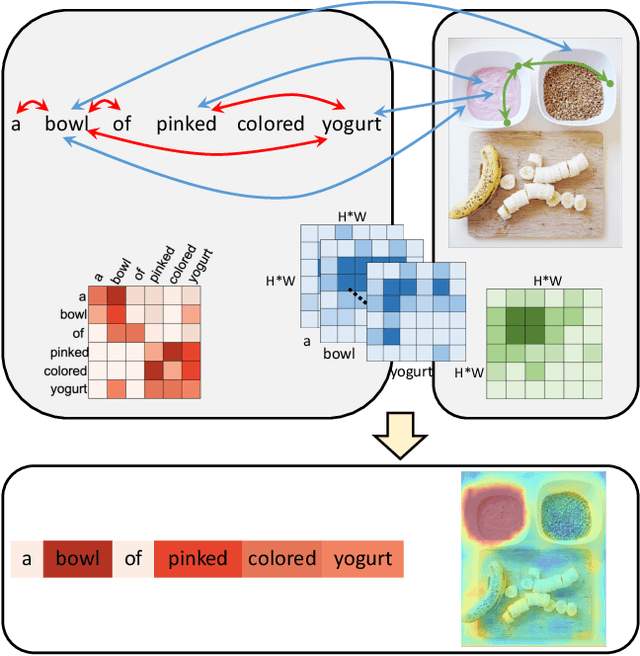
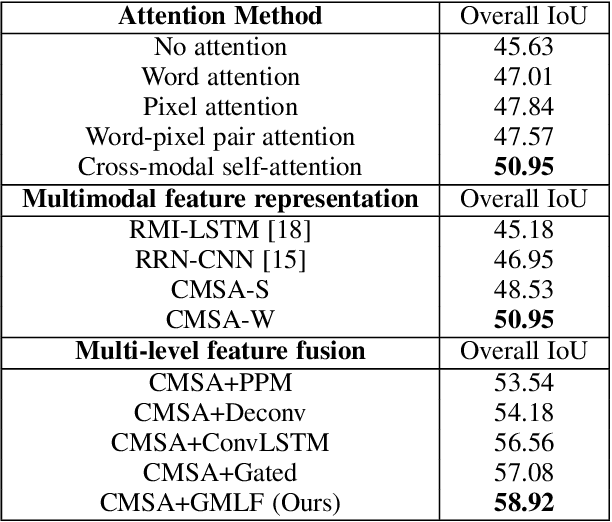
We consider the problem of referring segmentation in images and videos with natural language. Given an input image (or video) and a referring expression, the goal is to segment the entity referred by the expression in the image or video. In this paper, we propose a cross-modal self-attention (CMSA) module to utilize fine details of individual words and the input image or video, which effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the visual input. We further propose a gated multi-level fusion (GMLF) module to selectively integrate self-attentive cross-modal features corresponding to different levels of visual features. This module controls the feature fusion of information flow of features at different levels with high-level and low-level semantic information related to different attentive words. Besides, we introduce cross-frame self-attention (CFSA) module to effectively integrate temporal information in consecutive frames which extends our method in the case of referring segmentation in videos. Experiments on benchmark datasets of four referring image datasets and two actor and action video segmentation datasets consistently demonstrate that our proposed approach outperforms existing state-of-the-art methods.