 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Segmentation in Images and Videos with Cross-Modal Self-Attention Network
Feb 09, 2021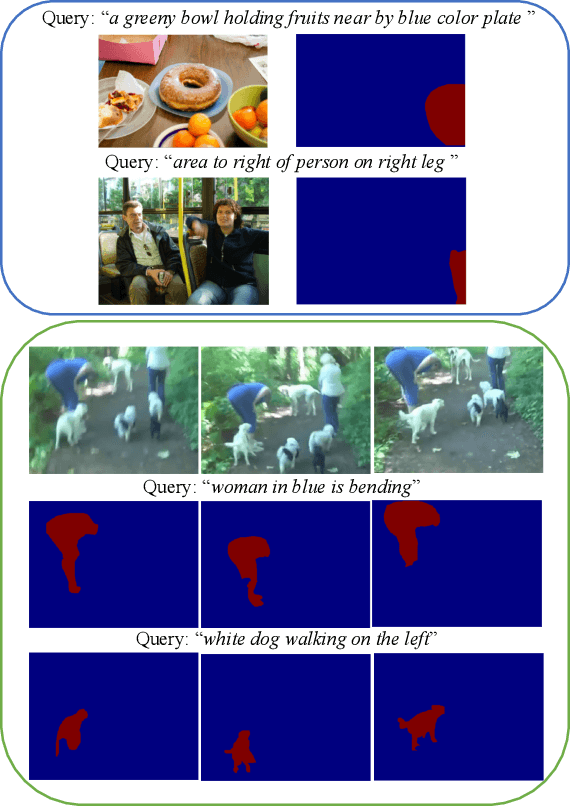

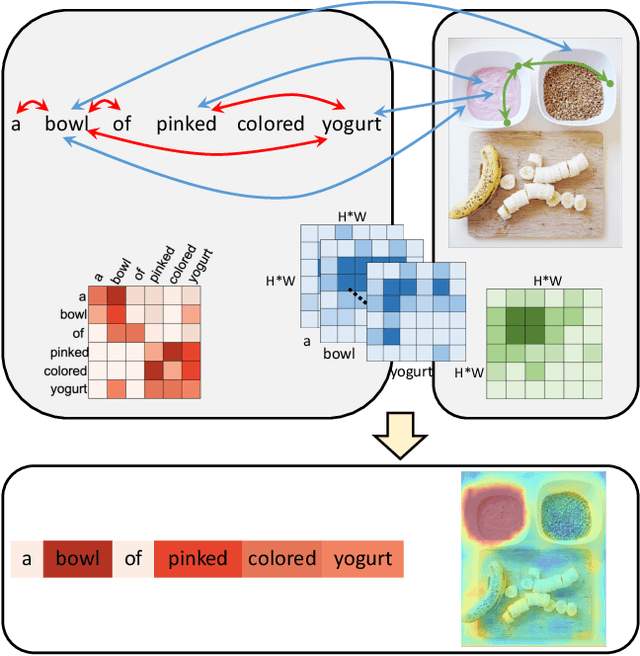
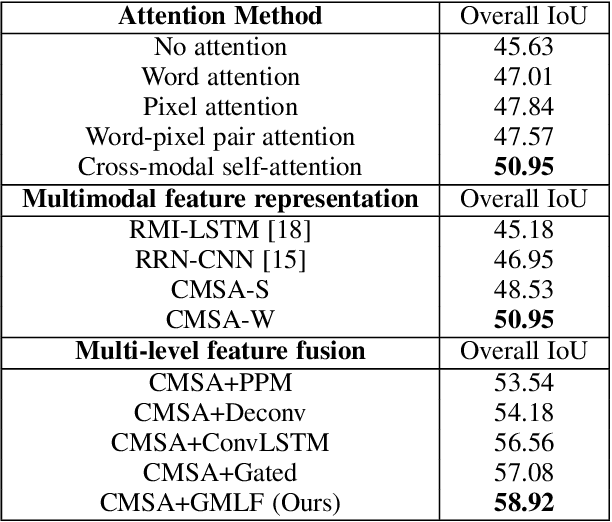
We consider the problem of referring segmentation in images and videos with natural language. Given an input image (or video) and a referring expression, the goal is to segment the entity referred by the expression in the image or video. In this paper, we propose a cross-modal self-attention (CMSA) module to utilize fine details of individual words and the input image or video, which effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the visual input. We further propose a gated multi-level fusion (GMLF) module to selectively integrate self-attentive cross-modal features corresponding to different levels of visual features. This module controls the feature fusion of information flow of features at different levels with high-level and low-level semantic information related to different attentive words. Besides, we introduce cross-frame self-attention (CFSA) module to effectively integrate temporal information in consecutive frames which extends our method in the case of referring segmentation in videos. Experiments on benchmark datasets of four referring image datasets and two actor and action video segmentation datasets consistently demonstrate that our proposed approach outperforms existing state-of-the-art methods.
Adaptive Video Highlight Detection by Learning from User History
Jul 19, 2020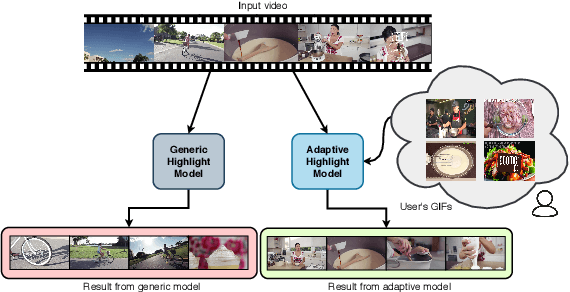
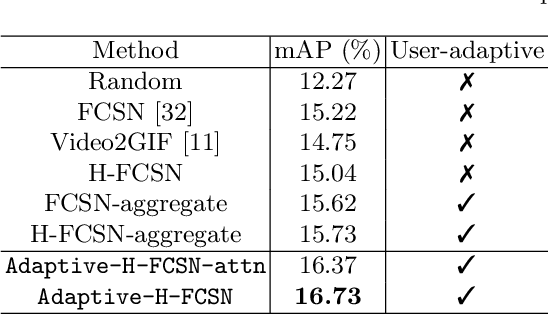
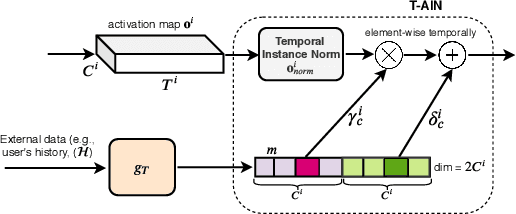

Recently, there is an increasing interest in highlight detection research where the goal is to create a short duration video from a longer video by extracting its interesting moments. However, most existing methods ignore the fact that the definition of video highlight is highly subjective. Different users may have different preferences of highlight for the same input video. In this paper, we propose a simple yet effective framework that learns to adapt highlight detection to a user by exploiting the user's history in the form of highlights that the user has previously created. Our framework consists of two sub-networks: a fully temporal convolutional highlight detection network $H$ that predicts highlight for an input video and a history encoder network $M$ for user history. We introduce a newly designed temporal-adaptive instance normalization (T-AIN) layer to $H$ where the two sub-networks interact with each other. T-AIN has affine parameters that are predicted from $M$ based on the user history and is responsible for the user-adaptive signal to $H$. Extensive experiments on a large-scale dataset show that our framework can make more accurate and user-specific highlight predictions.
Cross-Modal Weighting Network for RGB-D Salient Object Detection
Jul 09, 2020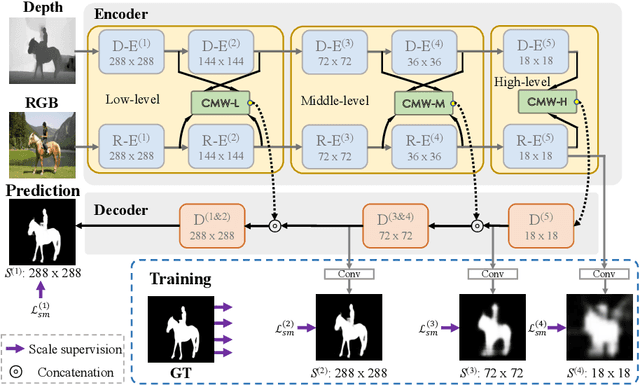
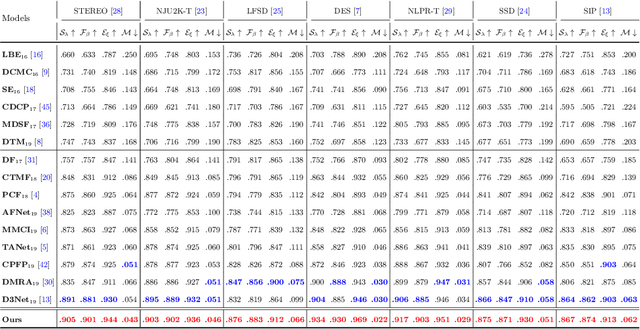

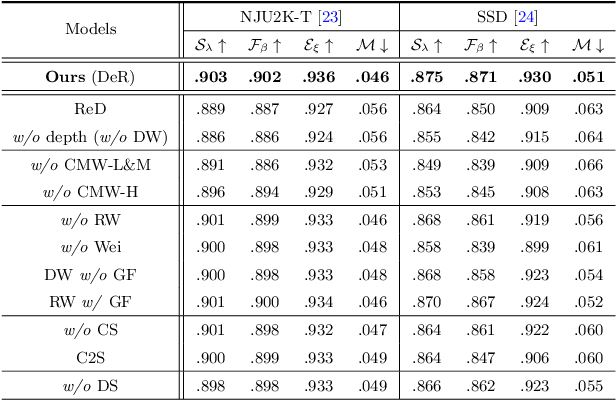
Depth maps contain geometric clues for assisting Salient Object Detection (SOD). In this paper, we propose a novel Cross-Modal Weighting (CMW) strategy to encourage comprehensive interactions between RGB and depth channels for RGB-D SOD. Specifically, three RGB-depth interaction modules, named CMW-L, CMW-M and CMW-H, are developed to deal with respectively low-, middle- and high-level cross-modal information fusion. These modules use Depth-to-RGB Weighing (DW) and RGB-to-RGB Weighting (RW) to allow rich cross-modal and cross-scale interactions among feature layers generated by different network blocks. To effectively train the proposed Cross-Modal Weighting Network (CMWNet), we design a composite loss function that summarizes the errors between intermediate predictions and ground truth over different scales. With all these novel components working together, CMWNet effectively fuses information from RGB and depth channels, and meanwhile explores object localization and details across scales. Thorough evaluations demonstrate CMWNet consistently outperforms 15 state-of-the-art RGB-D SOD methods on seven popular benchmarks.
Dual Convolutional LSTM Network for Referring Image Segmentation
Jan 30, 2020


We consider referring image segmentation. It is a problem at the intersection of computer vision and natural language understanding. Given an input image and a referring expression in the form of a natural language sentence, the goal is to segment the object of interest in the image referred by the linguistic query. To this end, we propose a dual convolutional LSTM (ConvLSTM) network to tackle this problem. Our model consists of an encoder network and a decoder network, where ConvLSTM is used in both encoder and decoder networks to capture spatial and sequential information. The encoder network extracts visual and linguistic features for each word in the expression sentence, and adopts an attention mechanism to focus on words that are more informative in the multimodal interaction. The decoder network integrates the features generated by the encoder network at multiple levels as its input and produces the final precise segmentation mask. Experimental results on four challenging datasets demonstrate that the proposed network achieves superior segmentation performance compared with other state-of-the-art methods.
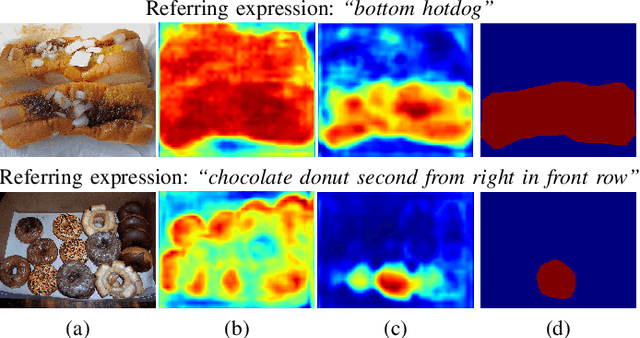
Cross-Modal Self-Attention Network for Referring Image Segmentation
Apr 09, 2019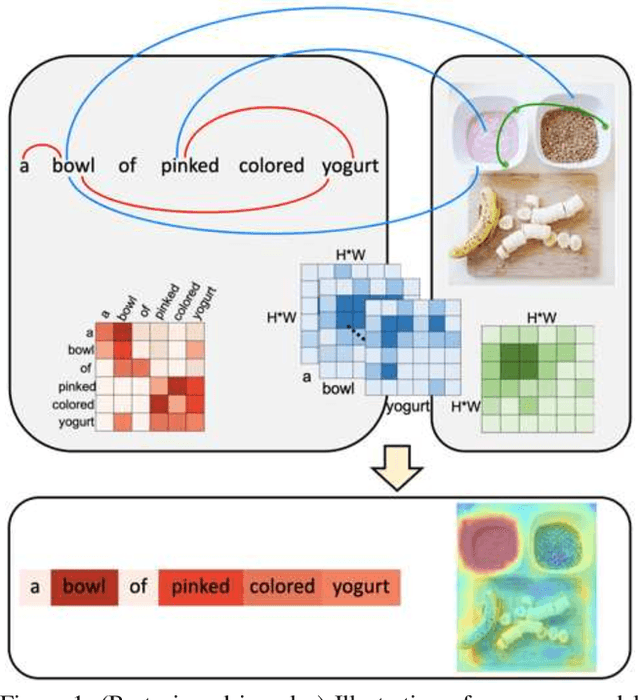

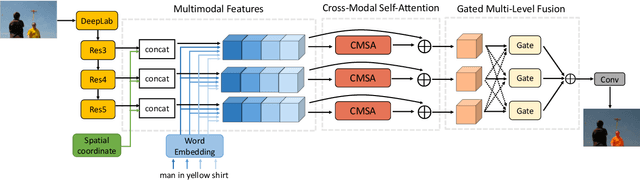
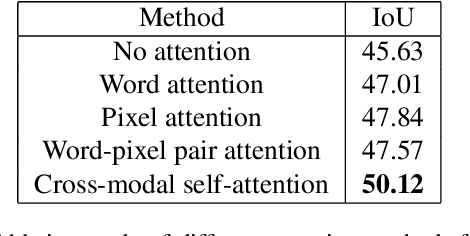
We consider the problem of referring image segmentation. Given an input image and a natural language expression, the goal is to segment the object referred by the language expression in the image. Existing works in this area treat the language expression and the input image separately in their representations. They do not sufficiently capture long-range correlations between these two modalities. In this paper, we propose a cross-modal self-attention (CMSA) module that effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the input image. In addition, we propose a gated multi-level fusion module to selectively integrate self-attentive cross-modal features corresponding to different levels in the image. This module controls the information flow of features at different levels. We validate the proposed approach on four evaluation datasets. Our proposed approach consistently outperforms existing state-of-the-art methods.
Video Summarization Using Fully Convolutional Sequence Networks
Aug 30, 2018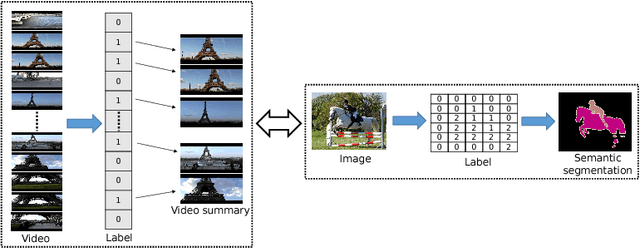

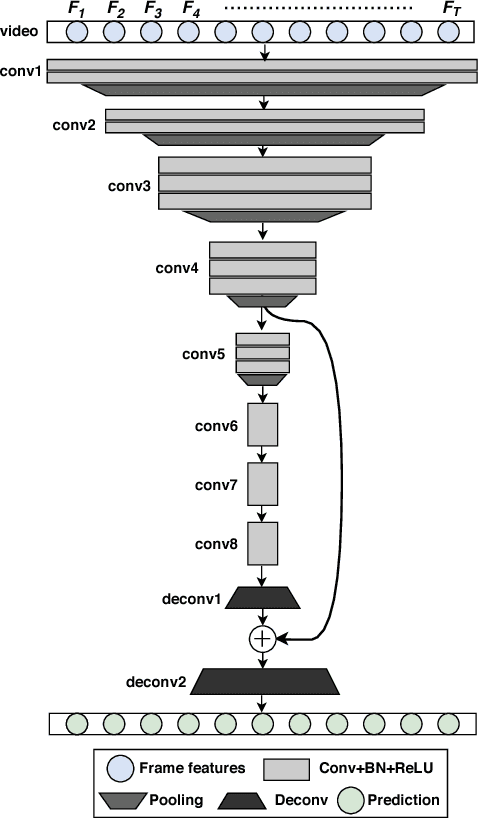

This paper addresses the problem of video summarization. Given an input video, the goal is to select a subset of the frames to create a summary video that optimally captures the important information of the input video. With the large amount of videos available online, video summarization provides a useful tool that assists video search, retrieval, browsing, etc. In this paper, we formulate video summarization as a sequence labeling problem. Unlike existing approaches that use recurrent models, we propose fully convolutional sequence models to solve video summarization. We firstly establish a novel connection between semantic segmentation and video summarization, and then adapt popular semantic segmentation networks for video summarization. Extensive experiments and analysis on two benchmark datasets demonstrate the effectiveness of our models.
Learning Semantic Segmentation with Diverse Supervision
Feb 01, 2018

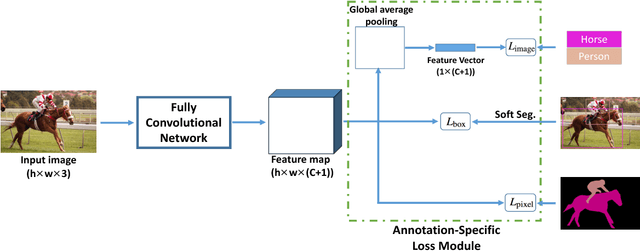
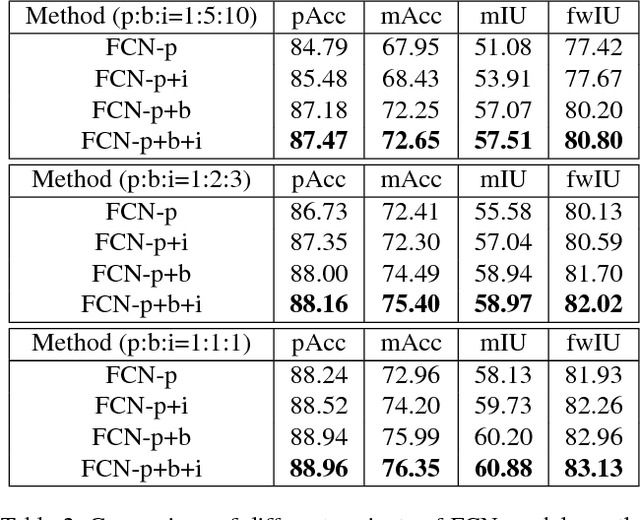
Models based on deep convolutional neural networks (CNN) have significantly improved the performance of semantic segmentation. However, learning these models requires a large amount of training images with pixel-level labels, which are very costly and time-consuming to collect. In this paper, we propose a method for learning CNN-based semantic segmentation models from images with several types of annotations that are available for various computer vision tasks, including image-level labels for classification, box-level labels for object detection and pixel-level labels for semantic segmentation. The proposed method is flexible and can be used together with any existing CNN-based semantic segmentation networks. Experimental evaluation on the challenging PASCAL VOC 2012 and SIFT-flow benchmarks demonstrate that the proposed method can effectively make use of diverse training data to improve the performance of the learned models.