 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Segmentation with Diverse Supervision
Paper and Code


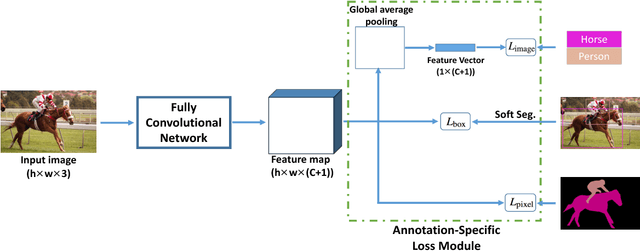
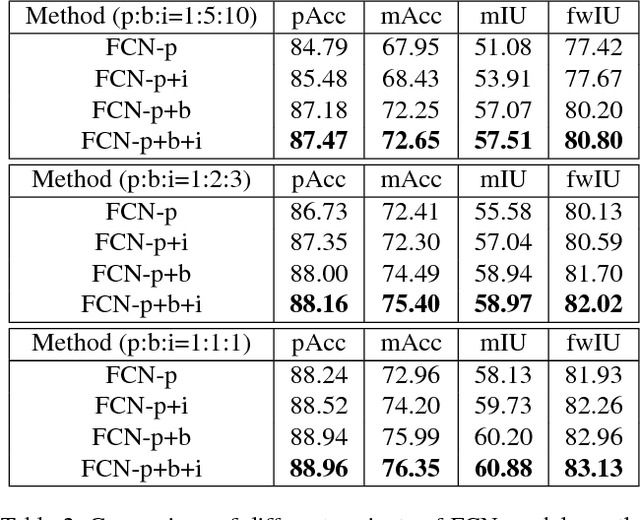
Models based on deep convolutional neural networks (CNN) have significantly improved the performance of semantic segmentation. However, learning these models requires a large amount of training images with pixel-level labels, which are very costly and time-consuming to collect. In this paper, we propose a method for learning CNN-based semantic segmentation models from images with several types of annotations that are available for various computer vision tasks, including image-level labels for classification, box-level labels for object detection and pixel-level labels for semantic segmentation. The proposed method is flexible and can be used together with any existing CNN-based semantic segmentation networks. Experimental evaluation on the challenging PASCAL VOC 2012 and SIFT-flow benchmarks demonstrate that the proposed method can effectively make use of diverse training data to improve the performance of the learned models.