 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Video Saliency Prediction: Methods and Results
Apr 16, 2026This paper presents an overview of the NTIRE 2026 Challenge on Video Saliency Prediction. The goal of the challenge participants was to develop automatic saliency map prediction methods for the provided video sequences. The novel dataset of 2,000 diverse videos with an open license was prepared for this challenge. The fixations and corresponding saliency maps were collected using crowdsourced mouse tracking and contain viewing data from over 5,000 assessors. Evaluation was performed on a subset of 800 test videos using generally accepted quality metrics. The challenge attracted over 20 teams making submissions, and 7 teams passed the final phase with code review. All data used in this challenge is made publicly available - https://github.com/msu-video-group/NTIRE26_Saliency_Prediction.
STENet: Superpixel Token Enhancing Network for RGB-D Salient Object Detection
Mar 23, 2026Transformer-based methods for RGB-D Salient Object Detection (SOD) have gained significant interest, owing to the transformer's exceptional capacity to capture long-range pixel dependencies. Nevertheless, current RGB-D SOD methods face challenges, such as the quadratic complexity of the attention mechanism and the limited local detail extraction. To overcome these limitations, we propose a novel Superpixel Token Enhancing Network (STENet), which introduces superpixels into cross-modal interaction. STENet follows the two-stream encoder-decoder structure. Its cores are two tailored superpixel-driven cross-modal interaction modules, responsible for global and local feature enhancement. Specifically, we update the superpixel generation method by expanding the neighborhood range of each superpixel, allowing for flexible transformation between pixels and superpixels. With the updated superpixel generation method, we first propose the Superpixel Attention Global Enhancing Module to model the global pixel-to-superpixel relationship rather than the traditional global pixel-to-pixel relationship, which can capture region-level information and reduce computational complexity. We also propose the Superpixel Attention Local Refining Module, which leverages pixel similarity within superpixels to filter out a subset of pixels (i.e., local pixels) and then performs feature enhancement on these local pixels, thereby capturing concerned local details. Furthermore, we fuse the globally and locally enhanced features along with the cross-scale features to achieve comprehensive feature representation. Experiments on seven RGB-D SOD datasets reveal that our STENet achieves competitive performance compared to state-of-the-art methods. The code and results of our method are available at https://github.com/Mark9010/STENet.
Efficient UAV trajectory prediction: A multi-modal deep diffusion framework
Jan 26, 2026To meet the requirements for managing unauthorized UAVs in the low-altitude economy, a multi-modal UAV trajectory prediction method based on the fusion of LiDAR and millimeter-wave radar information is proposed. A deep fusion network for multi-modal UAV trajectory prediction, termed the Multi-Modal Deep Fusion Framework, is designed. The overall architecture consists of two modality-specific feature extraction networks and a bidirectional cross-attention fusion module, aiming to fully exploit the complementary information of LiDAR and radar point clouds in spatial geometric structure and dynamic reflection characteristics. In the feature extraction stage, the model employs independent but structurally identical feature encoders for LiDAR and radar. After feature extraction, the model enters the Bidirectional Cross-Attention Mechanism stage to achieve information complementarity and semantic alignment between the two modalities. To verify the effectiveness of the proposed model, the MMAUD dataset used in the CVPR 2024 UG2+ UAV Tracking and Pose-Estimation Challenge is adopted as the training and testing dataset. Experimental results show that the proposed multi-modal fusion model significantly improves trajectory prediction accuracy, achieving a 40% improvement compared to the baseline model. In addition, ablation experiments are conducted to demonstrate the effectiveness of different loss functions and post-processing strategies in improving model performance. The proposed model can effectively utilize multi-modal data and provides an efficient solution for unauthorized UAV trajectory prediction in the low-altitude economy.
Dynamic Channel Charting: An LSTM-AE-based Approach
Jan 26, 2026With the development of the sixth-generation (6G) communication system, Channel State Information (CSI) plays a crucial role in improving network performance. Traditional Channel Charting (CC) methods map high-dimensional CSI data to low-dimensional spaces to help reveal the geometric structure of wireless channels. However, most existing CC methods focus on learning static geometric structures and ignore the dynamic nature of the channel over time, leading to instability and poor topological consistency of the channel charting in complex environments. To address this issue, this paper proposes a novel time-series channel charting approach based on the integration of Long Short-Term Memory (LSTM) networks and Auto encoders (AE) (LSTM-AE-CC). This method incorporates a temporal modeling mechanism into the traditional CC framework, capturing temporal dependencies in CSI using LSTM and learning continuous latent representations with AE. The proposed method ensures both geometric consistency of the channel and explicit modeling of the time-varying properties. Experimental results demonstrate that the proposed method outperforms traditional CC methods in various real-world communication scenarios, particularly in terms of channel charting stability, trajectory continuity, and long-term predictability.
DGA-Net: Enhancing SAM with Depth Prompting and Graph-Anchor Guidance for Camouflaged Object Detection
Jan 06, 2026To fully exploit depth cues in Camouflaged Object Detection (COD), we present DGA-Net, a specialized framework that adapts the Segment Anything Model (SAM) via a novel ``depth prompting" paradigm. Distinguished from existing approaches that primarily rely on sparse prompts (e.g., points or boxes), our method introduces a holistic mechanism for constructing and propagating dense depth prompts. Specifically, we propose a Cross-modal Graph Enhancement (CGE) module that synthesizes RGB semantics and depth geometric within a heterogeneous graph to form a unified guidance signal. Furthermore, we design an Anchor-Guided Refinement (AGR) module. To counteract the inherent information decay in feature hierarchies, AGR forges a global anchor and establishes direct non-local pathways to broadcast this guidance from deep to shallow layers, ensuring precise and consistent segmentation. Quantitative and qualitative experimental results demonstrate that our proposed DGA-Net outperforms the state-of-the-art COD methods.
Context-Aware Interaction Network for RGB-T Semantic Segmentation
Jan 03, 2024



RGB-T semantic segmentation is a key technique for autonomous driving scenes understanding. For the existing RGB-T semantic segmentation methods, however, the effective exploration of the complementary relationship between different modalities is not implemented in the information interaction between multiple levels. To address such an issue, the Context-Aware Interaction Network (CAINet) is proposed for RGB-T semantic segmentation, which constructs interaction space to exploit auxiliary tasks and global context for explicitly guided learning. Specifically, we propose a Context-Aware Complementary Reasoning (CACR) module aimed at establishing the complementary relationship between multimodal features with the long-term context in both spatial and channel dimensions. Further, considering the importance of global contextual and detailed information, we propose the Global Context Modeling (GCM) module and Detail Aggregation (DA) module, and we introduce specific auxiliary supervision to explicitly guide the context interaction and refine the segmentation map. Extensive experiments on two benchmark datasets of MFNet and PST900 demonstrate that the proposed CAINet achieves state-of-the-art performance. The code is available at https://github.com/YingLv1106/CAINet.
Texture-Semantic Collaboration Network for ORSI Salient Object Detection
Dec 06, 2023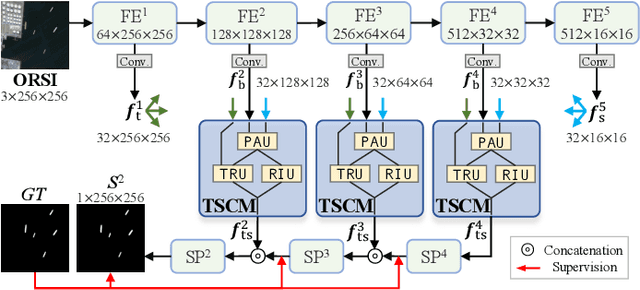
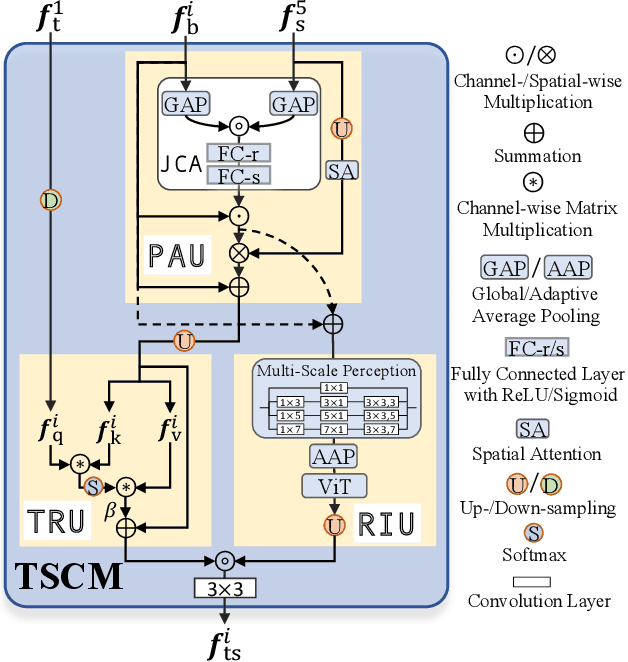
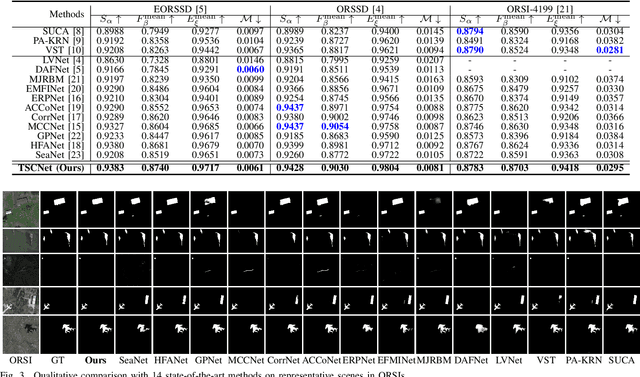

Salient object detection (SOD) in optical remote sensing images (ORSIs) has become increasingly popular recently. Due to the characteristics of ORSIs, ORSI-SOD is full of challenges, such as multiple objects, small objects, low illuminations, and irregular shapes. To address these challenges, we propose a concise yet effective Texture-Semantic Collaboration Network (TSCNet) to explore the collaboration of texture cues and semantic cues for ORSI-SOD. Specifically, TSCNet is based on the generic encoder-decoder structure. In addition to the encoder and decoder, TSCNet includes a vital Texture-Semantic Collaboration Module (TSCM), which performs valuable feature modulation and interaction on basic features extracted from the encoder. The main idea of our TSCM is to make full use of the texture features at the lowest level and the semantic features at the highest level to achieve the expression enhancement of salient regions on features. In the TSCM, we first enhance the position of potential salient regions using semantic features. Then, we render and restore the object details using the texture features. Meanwhile, we also perceive regions of various scales, and construct interactions between different regions. Thanks to the perfect combination of TSCM and generic structure, our TSCNet can take care of both the position and details of salient objects, effectively handling various scenes. Extensive experiments on three datasets demonstrate that our TSCNet achieves competitive performance compared to 14 state-of-the-art methods. The code and results of our method are available at https://github.com/MathLee/TSCNet.
Salient Object Detection in Optical Remote Sensing Images Driven by Transformer
Sep 15, 2023



Existing methods for Salient Object Detection in Optical Remote Sensing Images (ORSI-SOD) mainly adopt Convolutional Neural Networks (CNNs) as the backbone, such as VGG and ResNet. Since CNNs can only extract features within certain receptive fields, most ORSI-SOD methods generally follow the local-to-contextual paradigm. In this paper, we propose a novel Global Extraction Local Exploration Network (GeleNet) for ORSI-SOD following the global-to-local paradigm. Specifically, GeleNet first adopts a transformer backbone to generate four-level feature embeddings with global long-range dependencies. Then, GeleNet employs a Direction-aware Shuffle Weighted Spatial Attention Module (D-SWSAM) and its simplified version (SWSAM) to enhance local interactions, and a Knowledge Transfer Module (KTM) to further enhance cross-level contextual interactions. D-SWSAM comprehensively perceives the orientation information in the lowest-level features through directional convolutions to adapt to various orientations of salient objects in ORSIs, and effectively enhances the details of salient objects with an improved attention mechanism. SWSAM discards the direction-aware part of D-SWSAM to focus on localizing salient objects in the highest-level features. KTM models the contextual correlation knowledge of two middle-level features of different scales based on the self-attention mechanism, and transfers the knowledge to the raw features to generate more discriminative features. Finally, a saliency predictor is used to generate the saliency map based on the outputs of the above three modules. Extensive experiments on three public datasets demonstrate that the proposed GeleNet outperforms relevant state-of-the-art methods. The code and results of our method are available at https://github.com/MathLee/GeleNet.
No-Service Rail Surface Defect Segmentation via Normalized Attention and Dual-scale Interaction
Jun 27, 2023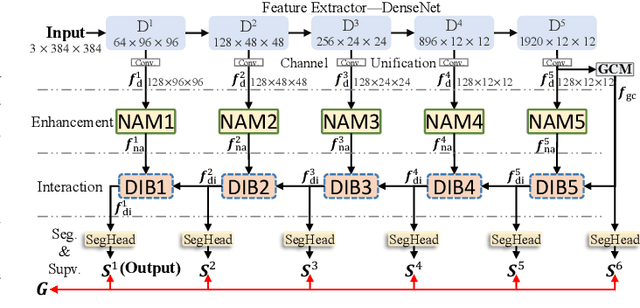
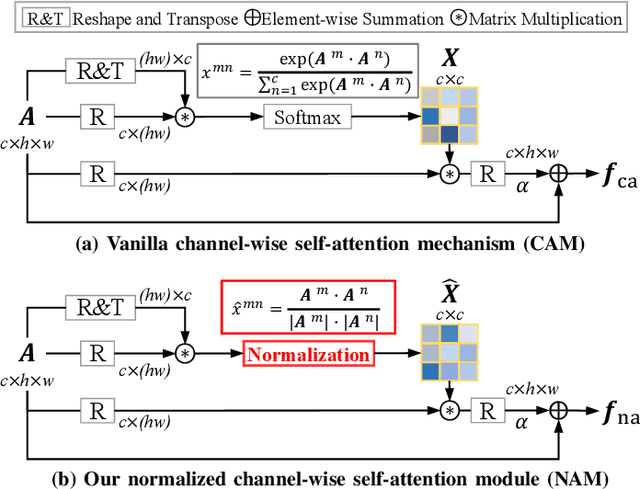

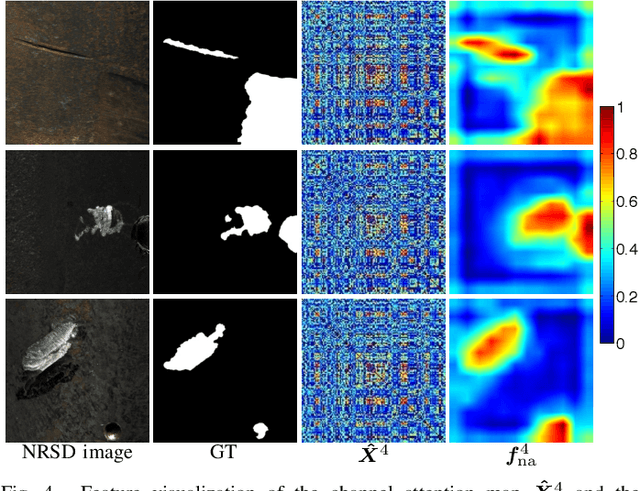
No-service rail surface defect (NRSD) segmentation is an essential way for perceiving the quality of no-service rails. However, due to the complex and diverse outlines and low-contrast textures of no-service rails, existing natural image segmentation methods cannot achieve promising performance in NRSD images, especially in some unique and challenging NRSD scenes. To this end, in this paper, we propose a novel segmentation network for NRSDs based on Normalized Attention and Dual-scale Interaction, named NaDiNet. Specifically, NaDiNet follows the enhancement-interaction paradigm. The Normalized Channel-wise Self-Attention Module (NAM) and the Dual-scale Interaction Block (DIB) are two key components of NaDiNet. NAM is a specific extension of the channel-wise self-attention mechanism (CAM) to enhance features extracted from low-contrast NRSD images. The softmax layer in CAM will produce very small correlation coefficients which are not conducive to low-contrast feature enhancement. Instead, in NAM, we directly calculate the normalized correlation coefficient between channels to enlarge the feature differentiation. DIB is specifically designed for the feature interaction of the enhanced features. It has two interaction branches with dual scales, one for fine-grained clues and the other for coarse-grained clues. With both branches working together, DIB can perceive defect regions of different granularities. With these modules working together, our NaDiNet can generate accurate segmentation map. Extensive experiments on the public NRSD-MN dataset with man-made and natural NRSDs demonstrate that our proposed NaDiNet with various backbones (i.e., VGG, ResNet, and DenseNet) consistently outperforms 10 state-of-the-art methods. The code and results of our method are available at https://github.com/monxxcn/NaDiNet.
Lightweight Salient Object Detection in Optical Remote Sensing Images via Semantic Matching and Edge Alignment
Jan 07, 2023



Recently, relying on convolutional neural networks (CNNs), many methods for salient object detection in optical remote sensing images (ORSI-SOD) are proposed. However, most methods ignore the huge parameters and computational cost brought by CNNs, and only a few pay attention to the portability and mobility. To facilitate practical applications, in this paper, we propose a novel lightweight network for ORSI-SOD based on semantic matching and edge alignment, termed SeaNet. Specifically, SeaNet includes a lightweight MobileNet-V2 for feature extraction, a dynamic semantic matching module (DSMM) for high-level features, an edge self-alignment module (ESAM) for low-level features, and a portable decoder for inference. First, the high-level features are compressed into semantic kernels. Then, semantic kernels are used to activate salient object locations in two groups of high-level features through dynamic convolution operations in DSMM. Meanwhile, in ESAM, cross-scale edge information extracted from two groups of low-level features is self-aligned through L2 loss and used for detail enhancement. Finally, starting from the highest-level features, the decoder infers salient objects based on the accurate locations and fine details contained in the outputs of the two modules. Extensive experiments on two public datasets demonstrate that our lightweight SeaNet not only outperforms most state-of-the-art lightweight methods but also yields comparable accuracy with state-of-the-art conventional methods, while having only 2.76M parameters and running with 1.7G FLOPs for 288x288 inputs. Our code and results are available at https://github.com/MathLee/SeaNet.