 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture-Semantic Collaboration Network for ORSI Salient Object Detection
Dec 06, 2023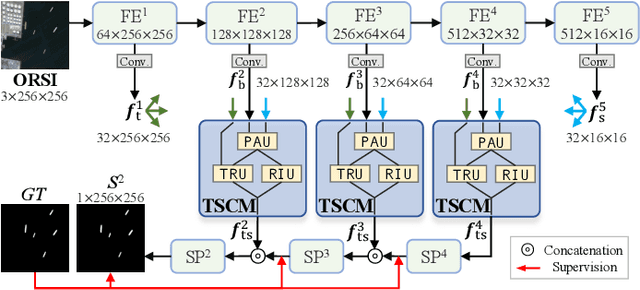
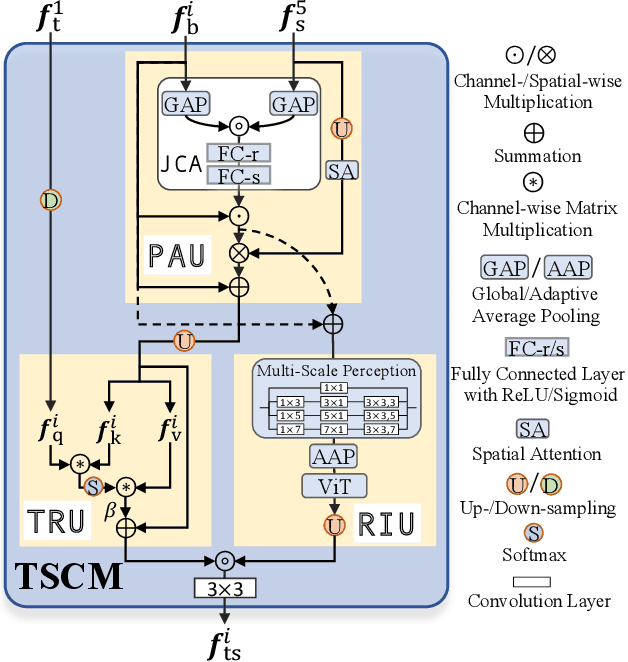
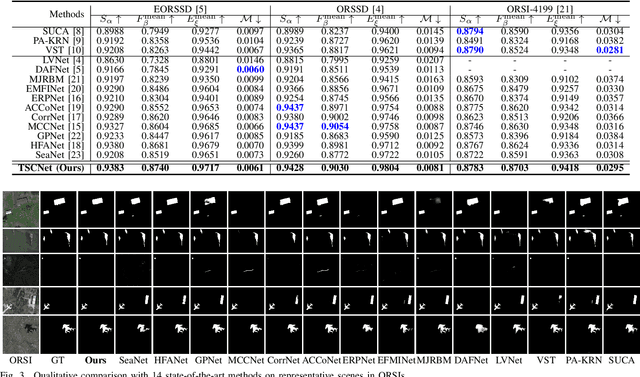

Salient object detection (SOD) in optical remote sensing images (ORSIs) has become increasingly popular recently. Due to the characteristics of ORSIs, ORSI-SOD is full of challenges, such as multiple objects, small objects, low illuminations, and irregular shapes. To address these challenges, we propose a concise yet effective Texture-Semantic Collaboration Network (TSCNet) to explore the collaboration of texture cues and semantic cues for ORSI-SOD. Specifically, TSCNet is based on the generic encoder-decoder structure. In addition to the encoder and decoder, TSCNet includes a vital Texture-Semantic Collaboration Module (TSCM), which performs valuable feature modulation and interaction on basic features extracted from the encoder. The main idea of our TSCM is to make full use of the texture features at the lowest level and the semantic features at the highest level to achieve the expression enhancement of salient regions on features. In the TSCM, we first enhance the position of potential salient regions using semantic features. Then, we render and restore the object details using the texture features. Meanwhile, we also perceive regions of various scales, and construct interactions between different regions. Thanks to the perfect combination of TSCM and generic structure, our TSCNet can take care of both the position and details of salient objects, effectively handling various scenes. Extensive experiments on three datasets demonstrate that our TSCNet achieves competitive performance compared to 14 state-of-the-art methods. The code and results of our method are available at https://github.com/MathLee/TSCNet.
Salient Object Detection in Optical Remote Sensing Images Driven by Transformer
Sep 15, 2023



Existing methods for Salient Object Detection in Optical Remote Sensing Images (ORSI-SOD) mainly adopt Convolutional Neural Networks (CNNs) as the backbone, such as VGG and ResNet. Since CNNs can only extract features within certain receptive fields, most ORSI-SOD methods generally follow the local-to-contextual paradigm. In this paper, we propose a novel Global Extraction Local Exploration Network (GeleNet) for ORSI-SOD following the global-to-local paradigm. Specifically, GeleNet first adopts a transformer backbone to generate four-level feature embeddings with global long-range dependencies. Then, GeleNet employs a Direction-aware Shuffle Weighted Spatial Attention Module (D-SWSAM) and its simplified version (SWSAM) to enhance local interactions, and a Knowledge Transfer Module (KTM) to further enhance cross-level contextual interactions. D-SWSAM comprehensively perceives the orientation information in the lowest-level features through directional convolutions to adapt to various orientations of salient objects in ORSIs, and effectively enhances the details of salient objects with an improved attention mechanism. SWSAM discards the direction-aware part of D-SWSAM to focus on localizing salient objects in the highest-level features. KTM models the contextual correlation knowledge of two middle-level features of different scales based on the self-attention mechanism, and transfers the knowledge to the raw features to generate more discriminative features. Finally, a saliency predictor is used to generate the saliency map based on the outputs of the above three modules. Extensive experiments on three public datasets demonstrate that the proposed GeleNet outperforms relevant state-of-the-art methods. The code and results of our method are available at https://github.com/MathLee/GeleNet.
Participatory Design of AI with Children: Reflections on IDC Design Challenge
Apr 18, 2023
Children growing up in the era of Artificial Intelligence (AI) will be most impacted by the technology across their life span. Participatory Design (PD) is widely adopted by the Interaction Design and Children (IDC) community, which empowers children to bring their interests, needs, and creativity to the design process of future technologies. While PD has drawn increasing attention to human-centered AI design, it remains largely untapped in facilitating the design process of AI technologies relevant to children and their community. In this paper, we report intriguing children's design ideas on AI technologies resulting from the "Research and Design Challenge" of the 22nd ACM Interaction Design and Children (IDC 2023) conference. The diversity of design problems, AI applications and capabilities revealed by the children's design ideas shed light on the potential of engaging children in PD activities for future AI technologies. We discuss opportunities and challenges for accessible and inclusive PD experiences with children in shaping the future of AI-powered society.
A Novel Multimodal Approach for Studying the Dynamics of Curiosity in Small Group Learning
Apr 01, 2022


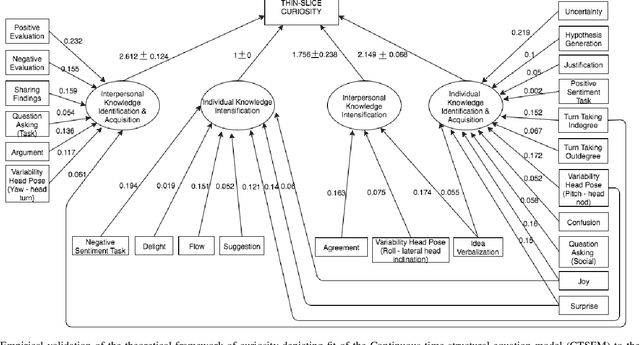
Curiosity is a vital metacognitive skill in educational contexts, leading to creativity, and a love of learning. And while many school systems increasingly undercut curiosity by teaching to the test, teachers are increasingly interested in how to evoke curiosity in their students to prepare them for a world in which lifelong learning and reskilling will be more and more important. One aspect of curiosity that has received little attention, however, is the role of peers in eliciting curiosity. We present what we believe to be the first theoretical framework that articulates an integrated socio-cognitive account of curiosity that ties observable behaviors in peers to underlying curiosity states. We make a bipartite distinction between individual and interpersonal functions that contribute to curiosity, and multimodal behaviors that fulfill these functions. We validate the proposed framework by leveraging a longitudinal latent variable modeling approach. Findings confirm a positive predictive relationship between the latent variables of individual and interpersonal functions and curiosity, with the interpersonal functions exercising a comparatively stronger influence. Prominent behavioral realizations of these functions are also discovered in a data-driven manner. We instantiate the proposed theoretical framework in a set of strategies and tactics that can be incorporated into learning technologies to indicate, evoke, and scaffold curiosity. This work is a step towards designing learning technologies that can recognize and evoke moment-by-moment curiosity during learning in social contexts and towards a more complete multimodal learning analytics. The underlying rationale is applicable more generally for developing computer support for other metacognitive and socio-emotional skills.
Lightweight Salient Object Detection in Optical Remote Sensing Images via Feature Correlation
Jan 20, 2022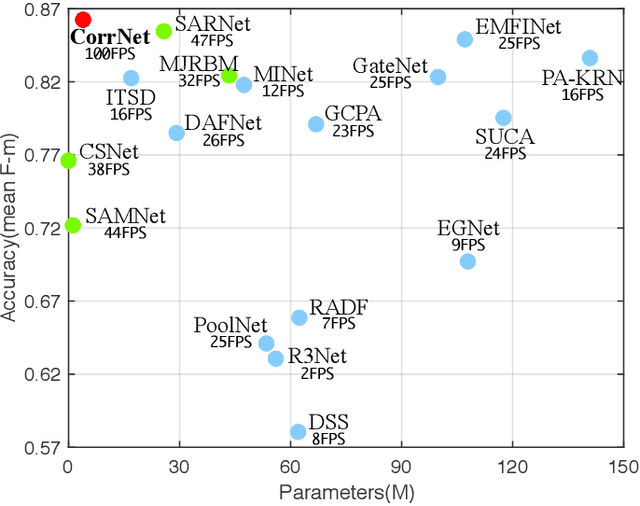


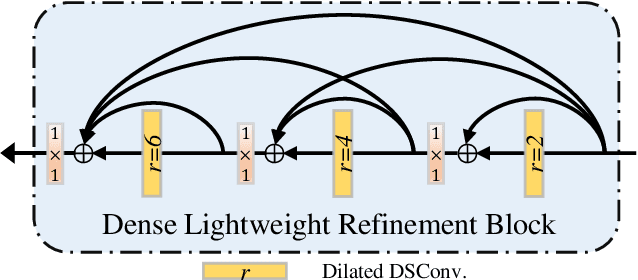
Salient object detection in optical remote sensing images (ORSI-SOD) has been widely explored for understanding ORSIs. However, previous methods focus mainly on improving the detection accuracy while neglecting the cost in memory and computation, which may hinder their real-world applications. In this paper, we propose a novel lightweight ORSI-SOD solution, named CorrNet, to address these issues. In CorrNet, we first lighten the backbone (VGG-16) and build a lightweight subnet for feature extraction. Then, following the coarse-to-fine strategy, we generate an initial coarse saliency map from high-level semantic features in a Correlation Module (CorrM). The coarse saliency map serves as the location guidance for low-level features. In CorrM, we mine the object location information between high-level semantic features through the cross-layer correlation operation. Finally, based on low-level detailed features, we refine the coarse saliency map in the refinement subnet equipped with Dense Lightweight Refinement Blocks, and produce the final fine saliency map. By reducing the parameters and computations of each component, CorrNet ends up having only 4.09M parameters and running with 21.09G FLOPs. Experimental results on two public datasets demonstrate that our lightweight CorrNet achieves competitive or even better performance compared with 26 state-of-the-art methods (including 16 large CNN-based methods and 2 lightweight methods), and meanwhile enjoys the clear memory and run time efficiency. The code and results of our method are available at https://github.com/MathLee/CorrNet.