 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Arithmetic Formulas in the Presence of Noise: A General Framework and Applications to Unsupervised Learning
Nov 13, 2023We present a general framework for designing efficient algorithms for unsupervised learning problems, such as mixtures of Gaussians and subspace clustering. Our framework is based on a meta algorithm that learns arithmetic circuits in the presence of noise, using lower bounds. This builds upon the recent work of Garg, Kayal and Saha (FOCS 20), who designed such a framework for learning arithmetic circuits without any noise. A key ingredient of our meta algorithm is an efficient algorithm for a novel problem called Robust Vector Space Decomposition. We show that our meta algorithm works well when certain matrices have sufficiently large smallest non-zero singular values. We conjecture that this condition holds for smoothed instances of our problems, and thus our framework would yield efficient algorithms for these problems in the smoothed setting.
MathDial: A Dialogue Tutoring Dataset with Rich Pedagogical Properties Grounded in Math Reasoning Problems
May 23, 2023

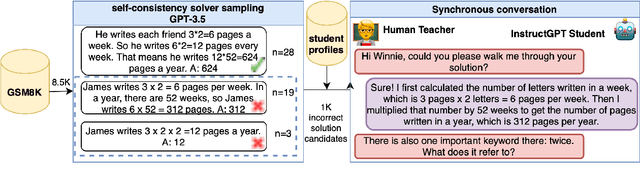

Although automatic dialogue tutors hold great potential in making education personalized and more accessible, research on such systems has been hampered by a lack of sufficiently large and high-quality datasets. However, collecting such datasets remains challenging, as recording tutoring sessions raises privacy concerns and crowdsourcing leads to insufficient data quality. To address this problem, we propose a framework to semi-synthetically generate such dialogues by pairing real teachers with a large language model (LLM) scaffolded to represent common student errors. In this paper, we describe our ongoing efforts to use this framework to collect MathDial, a dataset of currently ca. 1.5k tutoring dialogues grounded in multi-step math word problems. We show that our dataset exhibits rich pedagogical properties, focusing on guiding students using sense-making questions to let them explore problems. Moreover, we outline that MathDial and its grounding annotations can be used to finetune language models to be more effective tutors (and not just solvers) and highlight remaining challenges that need to be addressed by the research community. We will release our dataset publicly to foster research in this socially important area of NLP.
Opportunities and Challenges in Neural Dialog Tutoring
Jan 24, 2023
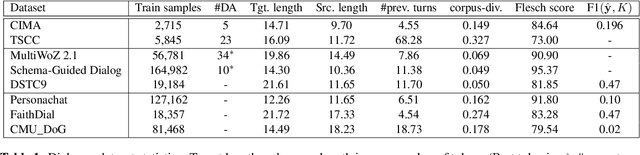


Designing dialog tutors has been challenging as it involves modeling the diverse and complex pedagogical strategies employed by human tutors. Although there have been significant recent advances in neural conversational systems using large language models and growth in available dialog corpora, dialog tutoring has largely remained unaffected by these advances. In this paper, we rigorously analyze various generative language models on two dialog tutoring datasets for language learning using automatic and human evaluations to understand the new opportunities brought by these advances as well as the challenges we must overcome to build models that would be usable in real educational settings. We find that although current approaches can model tutoring in constrained learning scenarios when the number of concepts to be taught and possible teacher strategies are small, they perform poorly in less constrained scenarios. Our human quality evaluation shows that both models and ground-truth annotations exhibit low performance in terms of equitable tutoring, which measures learning opportunities for students and how engaging the dialog is. To understand the behavior of our models in a real tutoring setting, we conduct a user study using expert annotators and find a significantly large number of model reasoning errors in 45% of conversations. Finally, we connect our findings to outline future work.
Automatic Generation of Socratic Subquestions for Teaching Math Word Problems
Nov 23, 2022



Socratic questioning is an educational method that allows students to discover answers to complex problems by asking them a series of thoughtful questions. Generation of didactically sound questions is challenging, requiring understanding of the reasoning process involved in the problem. We hypothesize that such questioning strategy can not only enhance the human performance, but also assist the math word problem (MWP) solvers. In this work, we explore the ability of large language models (LMs) in generating sequential questions for guiding math word problem-solving. We propose various guided question generation schemes based on input conditioning and reinforcement learning. On both automatic and human quality evaluations, we find that LMs constrained with desirable question properties generate superior questions and improve the overall performance of a math word problem solver. We conduct a preliminary user study to examine the potential value of such question generation models in the education domain. Results suggest that the difficulty level of problems plays an important role in determining whether questioning improves or hinders human performance. We discuss the future of using such questioning strategies in education.
A Novel Multimodal Approach for Studying the Dynamics of Curiosity in Small Group Learning
Apr 01, 2022


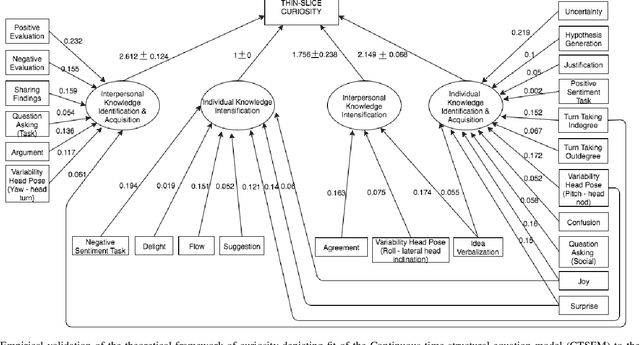
Curiosity is a vital metacognitive skill in educational contexts, leading to creativity, and a love of learning. And while many school systems increasingly undercut curiosity by teaching to the test, teachers are increasingly interested in how to evoke curiosity in their students to prepare them for a world in which lifelong learning and reskilling will be more and more important. One aspect of curiosity that has received little attention, however, is the role of peers in eliciting curiosity. We present what we believe to be the first theoretical framework that articulates an integrated socio-cognitive account of curiosity that ties observable behaviors in peers to underlying curiosity states. We make a bipartite distinction between individual and interpersonal functions that contribute to curiosity, and multimodal behaviors that fulfill these functions. We validate the proposed framework by leveraging a longitudinal latent variable modeling approach. Findings confirm a positive predictive relationship between the latent variables of individual and interpersonal functions and curiosity, with the interpersonal functions exercising a comparatively stronger influence. Prominent behavioral realizations of these functions are also discovered in a data-driven manner. We instantiate the proposed theoretical framework in a set of strategies and tactics that can be incorporated into learning technologies to indicate, evoke, and scaffold curiosity. This work is a step towards designing learning technologies that can recognize and evoke moment-by-moment curiosity during learning in social contexts and towards a more complete multimodal learning analytics. The underlying rationale is applicable more generally for developing computer support for other metacognitive and socio-emotional skills.
Capturing "attrition intensifying" structural traits from didactic interaction sequences of MOOC learners
Sep 20, 2014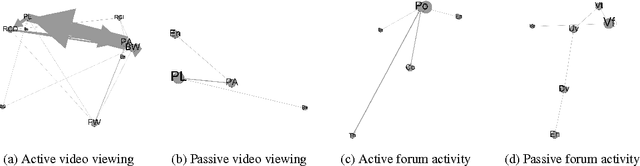

This work is an attempt to discover hidden structural configurations in learning activity sequences of students in Massive Open Online Courses (MOOCs). Leveraging combined representations of video clickstream interactions and forum activities, we seek to fundamentally understand traits that are predictive of decreasing engagement over time. Grounded in the interdisciplinary field of network science, we follow a graph based approach to successfully extract indicators of active and passive MOOC participation that reflect persistence and regularity in the overall interaction footprint. Using these rich educational semantics, we focus on the problem of predicting student attrition, one of the major highlights of MOOC literature in the recent years. Our results indicate an improvement over a baseline ngram based approach in capturing "attrition intensifying" features from the learning activities that MOOC learners engage in. Implications for some compelling future research are discussed.
Your click decides your fate: Inferring Information Processing and Attrition Behavior from MOOC Video Clickstream Interactions
Sep 16, 2014

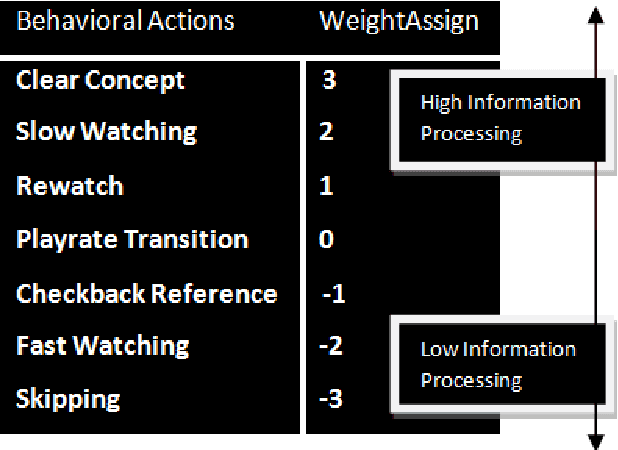

In this work, we explore video lecture interaction in Massive Open Online Courses (MOOCs), which is central to student learning experience on these educational platforms. As a research contribution, we operationalize video lecture clickstreams of students into cognitively plausible higher level behaviors, and construct a quantitative information processing index, which can aid instructors to better understand MOOC hurdles and reason about unsatisfactory learning outcomes. Our results illustrate how such a metric inspired by cognitive psychology can help answer critical questions regarding students' engagement, their future click interactions and participation trajectories that lead to in-video & course dropouts. Implications for research and practice are discussed
Leveraging user profile attributes for improving pedagogical accuracy of learning pathways
Jul 27, 2014In recent years, with the enormous explosion of web based learning resources, personalization has become a critical factor for the success of services that wish to leverage the power of Web 2.0. However, the relevance, significance and impact of tailored content delivery in the learning domain is still questionable. Apart from considering only interaction based features like ratings and inferring learner preferences from them, if these services were to incorporate innate user profile attributes which affect learning activities, the quality of recommendations produced could be vastly improved. Recognizing the crucial role of effective guidance in informal educational settings, we provide a principled way of utilizing multiple sources of information from the user profile itself for the recommendation task. We explore factors that affect the choice of learning resources and explain in what way are they helpful to improve the pedagogical accuracy of learning objects recommended. Through a systematical application of machine learning techniques, we further provide a technological solution to convert these indirectly mapped learner specific attributes into a direct mapping with the learning resources. This mapping has a distinct advantage of tagging learning resources to make their metadata more informative. The results of our empirical study depict the similarity of nominal learning attributes with respect to each other. We further succeed in capturing the learner subset, whose preferences are most likely to be an indication of learning resource usage. Our novel system filters learner profile attributes to discover a tag that links them with learning resources.
Together we stand, Together we fall, Together we win: Dynamic Team Formation in Massive Open Online Courses
Apr 22, 2014


Massive Open Online Courses (MOOCs) offer a new scalable paradigm for e-learning by providing students with global exposure and opportunities for connecting and interacting with millions of people all around the world. Very often, students work as teams to effectively accomplish course related tasks. However, due to lack of face to face interaction, it becomes difficult for MOOC students to collaborate. Additionally, the instructor also faces challenges in manually organizing students into teams because students flock to these MOOCs in huge numbers. Thus, the proposed research is aimed at developing a robust methodology for dynamic team formation in MOOCs, the theoretical framework for which is grounded at the confluence of organizational team theory, social network analysis and machine learning. A prerequisite for such an undertaking is that we understand the fact that, each and every informal tie established among students offers the opportunities to influence and be influenced. Therefore, we aim to extract value from the inherent connectedness of students in the MOOC. These connections carry with them radical implications for the way students understand each other in the networked learning community. Our approach will enable course instructors to automatically group students in teams that have fairly balanced social connections with their peers, well defined in terms of appropriately selected qualitative and quantitative network metrics.