 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Between the Pixels: Linking Text-Image Embedding Alignment to Typographic Attack Success on Vision-Language Models
Apr 14, 2026We study typographic prompt injection attacks on vision-language models (VLMs), where adversarial text is rendered as images to bypass safety mechanisms, posing a growing threat as VLMs serve as the perceptual backbone of autonomous agents, from browser automation and computer-use systems to camera-equipped embodied agents. In practice, the attack surface is heterogeneous: adversarial text appears at varying font sizes and under diverse visual conditions, while the growing ecosystem of VLMs exhibits substantial variation in vulnerability, complicating defensive approaches. Evaluating 1,000 prompts from SALAD-Bench across four VLMs, namely, GPT-4o, Claude Sonnet 4.5, Mistral-Large-3, and Qwen3-VL-4B-Instruct under varying font sizes (6--28px) and visual transformations (rotation, blur, noise, contrast changes), we find: (1) font size significantly affects attack success rate (ASR), with very small fonts (6px) yielding near-zero ASR while mid-range fonts achieve peak effectiveness; (2) text attacks are more effective than image attacks for GPT-4o (36% vs 8%) and Claude (47% vs 22%), while Qwen3-VL and Mistral show comparable ASR across modalities; (3) text-image embedding distance from two multimodal embedding models (JinaCLIP and Qwen3-VL-Embedding) shows strong negative correlation with ASR across all four models (r = -0.71 to -0.93, p < 0.01); (4) heavy degradations increase embedding distance by 10--12% and reduce ASR by 34--96%, while rotation asymmetrically affects models (Mistral drops 50%, GPT-4o unchanged). These findings highlight that model-specific robustness patterns preclude one-size-fits-all defenses and offer empirical guidance for practitioners selecting VLM backbones for agentic systems operating in adversarial environments.
On Strengths and Limitations of Single-Vector Embeddings
Mar 31, 2026Recent work (Weller et al., 2025) introduced a naturalistic dataset called LIMIT and showed empirically that a wide range of popular single-vector embedding models suffer substantial drops in retrieval quality, raising concerns about the reliability of single-vector embeddings for retrieval. Although (Weller et al., 2025) proposed limited dimensionality as the main factor contributing to this, we show that dimensionality alone cannot explain the observed failures. We observe from results in (Alon et al., 2016) that $2k+1$-dimensional vector embeddings suffice for top-$k$ retrieval. This result points to other drivers of poor performance. Controlling for tokenization artifacts and linguistic similarity between attributes yields only modest gains. In contrast, we find that domain shift and misalignment between embedding similarities and the task's underlying notion of relevance are major contributors; finetuning mitigates these effects and can improve recall substantially. Even with finetuning, however, single-vector models remain markedly weaker than multi-vector representations, pointing to fundamental limitations. Moreover, finetuning single-vector models on LIMIT-like datasets leads to catastrophic forgetting (performance on MSMARCO drops by more than 40%), whereas forgetting for multi-vector models is minimal. To better understand the gap between performance of single-vector and multi-vector models, we study the drowning in documents paradox (Reimers \& Gurevych, 2021; Jacob et al., 2025): as the corpus grows, relevant documents are increasingly "drowned out" because embedding similarities behave, in part, like noisy statistical proxies for relevance. Through experiments and mathematical calculations on toy mathematical models, we illustrate why single-vector models are more susceptible to drowning effects compared to multi-vector models.
Cisco Integrated AI Security and Safety Framework Report
Dec 15, 2025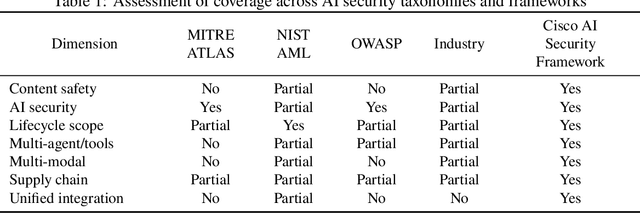
Artificial intelligence (AI) systems are being readily and rapidly adopted, increasingly permeating critical domains: from consumer platforms and enterprise software to networked systems with embedded agents. While this has unlocked potential for human productivity gains, the attack surface has expanded accordingly: threats now span content safety failures (e.g., harmful or deceptive outputs), model and data integrity compromise (e.g., poisoning, supply-chain tampering), runtime manipulations (e.g., prompt injection, tool and agent misuse), and ecosystem risks (e.g., orchestration abuse, multi-agent collusion). Existing frameworks such as MITRE ATLAS, National Institute of Standards and Technology (NIST) AI 100-2 Adversarial Machine Learning (AML) taxonomy, and OWASP Top 10s for Large Language Models (LLMs) and Agentic AI Applications provide valuable viewpoints, but each covers only slices of this multi-dimensional space. This paper presents Cisco's Integrated AI Security and Safety Framework ("AI Security Framework"), a unified, lifecycle-aware taxonomy and operationalization framework that can be used to classify, integrate, and operationalize the full range of AI risks. It integrates AI security and AI safety across modalities, agents, pipelines, and the broader ecosystem. The AI Security Framework is designed to be practical for threat identification, red-teaming, risk prioritization, and it is comprehensive in scope and can be extensible to emerging deployments in multimodal contexts, humanoids, wearables, and sensory infrastructures. We analyze gaps in prevailing frameworks, discuss design principles for our framework, and demonstrate how the taxonomy provides structure for understanding how modern AI systems fail, how adversaries exploit these failures, and how organizations can build defenses across the AI lifecycle that evolve alongside capability advancements.
Learning Arithmetic Formulas in the Presence of Noise: A General Framework and Applications to Unsupervised Learning
Nov 13, 2023We present a general framework for designing efficient algorithms for unsupervised learning problems, such as mixtures of Gaussians and subspace clustering. Our framework is based on a meta algorithm that learns arithmetic circuits in the presence of noise, using lower bounds. This builds upon the recent work of Garg, Kayal and Saha (FOCS 20), who designed such a framework for learning arithmetic circuits without any noise. A key ingredient of our meta algorithm is an efficient algorithm for a novel problem called Robust Vector Space Decomposition. We show that our meta algorithm works well when certain matrices have sufficiently large smallest non-zero singular values. We conjecture that this condition holds for smoothed instances of our problems, and thus our framework would yield efficient algorithms for these problems in the smoothed setting.
Near-Optimal Lower Bounds For Convex Optimization For All Orders of Smoothness
Dec 02, 2021We study the complexity of optimizing highly smooth convex functions. For a positive integer $p$, we want to find an $\epsilon$-approximate minimum of a convex function $f$, given oracle access to the function and its first $p$ derivatives, assuming that the $p$th derivative of $f$ is Lipschitz. Recently, three independent research groups (Jiang et al., PLMR 2019; Gasnikov et al., PLMR 2019; Bubeck et al., PLMR 2019) developed a new algorithm that solves this problem with $\tilde{O}(1/\epsilon^{\frac{2}{3p+1}})$ oracle calls for constant $p$. This is known to be optimal (up to log factors) for deterministic algorithms, but known lower bounds for randomized algorithms do not match this bound. We prove a new lower bound that matches this bound (up to log factors), and holds not only for randomized algorithms, but also for quantum algorithms.
Learning sums of powers of low-degree polynomials in the non-degenerate case
Apr 15, 2020We develop algorithms for writing a polynomial as sums of powers of low degree polynomials. Consider an $n$-variate degree-$d$ polynomial $f$ which can be written as $$f = c_1Q_1^{m} + \ldots + c_s Q_s^{m},$$ where each $c_i\in \mathbb{F}^{\times}$, $Q_i$ is a homogeneous polynomial of degree $t$, and $t m = d$. In this paper, we give a $\text{poly}((ns)^t)$-time learning algorithm for finding the $Q_i$'s given (black-box access to) $f$, if the $Q_i's$ satisfy certain non-degeneracy conditions and $n$ is larger than $d^2$. The set of degenerate $Q_i$'s (i.e., inputs for which the algorithm does not work) form a non-trivial variety and hence if the $Q_i$'s are chosen according to any reasonable (full-dimensional) distribution, then they are non-degenerate with high probability (if $s$ is not too large). Our algorithm is based on a scheme for obtaining a learning algorithm for an arithmetic circuit model from a lower bound for the same model, provided certain non-degeneracy conditions hold. The scheme reduces the learning problem to the problem of decomposing two vector spaces under the action of a set of linear operators, where the spaces and the operators are derived from the input circuit and the complexity measure used in a typical lower bound proof. The non-degeneracy conditions are certain restrictions on how the spaces decompose.
Communication Lower Bounds for Statistical Estimation Problems via a Distributed Data Processing Inequality
May 10, 2016We study the tradeoff between the statistical error and communication cost of distributed statistical estimation problems in high dimensions. In the distributed sparse Gaussian mean estimation problem, each of the $m$ machines receives $n$ data points from a $d$-dimensional Gaussian distribution with unknown mean $\theta$ which is promised to be $k$-sparse. The machines communicate by message passing and aim to estimate the mean $\theta$. We provide a tight (up to logarithmic factors) tradeoff between the estimation error and the number of bits communicated between the machines. This directly leads to a lower bound for the distributed \textit{sparse linear regression} problem: to achieve the statistical minimax error, the total communication is at least $\Omega(\min\{n,d\}m)$, where $n$ is the number of observations that each machine receives and $d$ is the ambient dimension. These lower results improve upon [Sha14,SD'14] by allowing multi-round iterative communication model. We also give the first optimal simultaneous protocol in the dense case for mean estimation. As our main technique, we prove a \textit{distributed data processing inequality}, as a generalization of usual data processing inequalities, which might be of independent interest and useful for other problems.
On Communication Cost of Distributed Statistical Estimation and Dimensionality
Nov 08, 2014We explore the connection between dimensionality and communication cost in distributed learning problems. Specifically we study the problem of estimating the mean $\vec{\theta}$ of an unknown $d$ dimensional gaussian distribution in the distributed setting. In this problem, the samples from the unknown distribution are distributed among $m$ different machines. The goal is to estimate the mean $\vec{\theta}$ at the optimal minimax rate while communicating as few bits as possible. We show that in this setting, the communication cost scales linearly in the number of dimensions i.e. one needs to deal with different dimensions individually. Applying this result to previous lower bounds for one dimension in the interactive setting \cite{ZDJW13} and to our improved bounds for the simultaneous setting, we prove new lower bounds of $\Omega(md/\log(m))$ and $\Omega(md)$ for the bits of communication needed to achieve the minimax squared loss, in the interactive and simultaneous settings respectively. To complement, we also demonstrate an interactive protocol achieving the minimax squared loss with $O(md)$ bits of communication, which improves upon the simple simultaneous protocol by a logarithmic factor. Given the strong lower bounds in the general setting, we initiate the study of the distributed parameter estimation problems with structured parameters. Specifically, when the parameter is promised to be $s$-sparse, we show a simple thresholding based protocol that achieves the same squared loss while saving a $d/s$ factor of communication. We conjecture that the tradeoff between communication and squared loss demonstrated by this protocol is essentially optimal up to logarithmic factor.
Close Clustering Based Automated Color Image Annotation
Aug 02, 2010Most image-search approaches today are based on the text based tags associated with the images which are mostly human generated and are subject to various kinds of errors. The results of a query to the image database thus can often be misleading and may not satisfy the requirements of the user. In this work we propose our approach to automate this tagging process of images, where image results generated can be fine filtered based on a probabilistic tagging mechanism. We implement a tool which helps to automate the tagging process by maintaining a training database, wherein the system is trained to identify certain set of input images, the results generated from which are used to create a probabilistic tagging mechanism. Given a certain set of segments in an image it calculates the probability of presence of particular keywords. This probability table is further used to generate the candidate tags for input images.