 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Algorithms for Reinforcement Learning with a Generative Model
Dec 15, 2021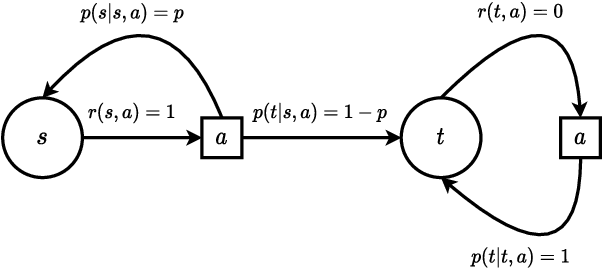
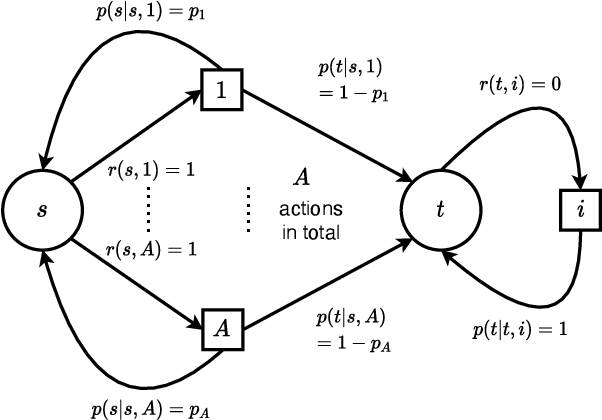
Reinforcement learning studies how an agent should interact with an environment to maximize its cumulative reward. A standard way to study this question abstractly is to ask how many samples an agent needs from the environment to learn an optimal policy for a $\gamma$-discounted Markov decision process (MDP). For such an MDP, we design quantum algorithms that approximate an optimal policy ($\pi^*$), the optimal value function ($v^*$), and the optimal $Q$-function ($q^*$), assuming the algorithms can access samples from the environment in quantum superposition. This assumption is justified whenever there exists a simulator for the environment; for example, if the environment is a video game or some other program. Our quantum algorithms, inspired by value iteration, achieve quadratic speedups over the best-possible classical sample complexities in the approximation accuracy ($\epsilon$) and two main parameters of the MDP: the effective time horizon ($\frac{1}{1-\gamma}$) and the size of the action space ($A$). Moreover, we show that our quantum algorithm for computing $q^*$ is optimal by proving a matching quantum lower bound.
* 26 pages
Near-Optimal Lower Bounds For Convex Optimization For All Orders of Smoothness
Dec 02, 2021We study the complexity of optimizing highly smooth convex functions. For a positive integer $p$, we want to find an $\epsilon$-approximate minimum of a convex function $f$, given oracle access to the function and its first $p$ derivatives, assuming that the $p$th derivative of $f$ is Lipschitz. Recently, three independent research groups (Jiang et al., PLMR 2019; Gasnikov et al., PLMR 2019; Bubeck et al., PLMR 2019) developed a new algorithm that solves this problem with $\tilde{O}(1/\epsilon^{\frac{2}{3p+1}})$ oracle calls for constant $p$. This is known to be optimal (up to log factors) for deterministic algorithms, but known lower bounds for randomized algorithms do not match this bound. We prove a new lower bound that matches this bound (up to log factors), and holds not only for randomized algorithms, but also for quantum algorithms.
Optimal learning of quantum Hamiltonians from high-temperature Gibbs states
Aug 10, 2021We study the problem of learning a Hamiltonian $H$ to precision $\varepsilon$, supposing we are given copies of its Gibbs state $\rho=\exp(-\beta H)/\operatorname{Tr}(\exp(-\beta H))$ at a known inverse temperature $\beta$. Anshu, Arunachalam, Kuwahara, and Soleimanifar (Nature Physics, 2021) recently studied the sample complexity (number of copies of $\rho$ needed) of this problem for geometrically local $N$-qubit Hamiltonians. In the high-temperature (low $\beta$) regime, their algorithm has sample complexity poly$(N, 1/\beta,1/\varepsilon)$ and can be implemented with polynomial, but suboptimal, time complexity. In this paper, we study the same question for a more general class of Hamiltonians. We show how to learn the coefficients of a Hamiltonian to error $\varepsilon$ with sample complexity $S = O(\log N/(\beta\varepsilon)^{2})$ and time complexity linear in the sample size, $O(S N)$. Furthermore, we prove a matching lower bound showing that our algorithm's sample complexity is optimal, and hence our time complexity is also optimal. In the appendix, we show that virtually the same algorithm can be used to learn $H$ from a real-time evolution unitary $e^{-it H}$ in a small $t$ regime with similar sample and time complexity.
Easy and hard functions for the Boolean hidden shift problem
Apr 16, 2013


We study the quantum query complexity of the Boolean hidden shift problem. Given oracle access to f(x+s) for a known Boolean function f, the task is to determine the n-bit string s. The quantum query complexity of this problem depends strongly on f. We demonstrate that the easiest instances of this problem correspond to bent functions, in the sense that an exact one-query algorithm exists if and only if the function is bent. We partially characterize the hardest instances, which include delta functions. Moreover, we show that the problem is easy for random functions, since two queries suffice. Our algorithm for random functions is based on performing the pretty good measurement on several copies of a certain state; its analysis relies on the Fourier transform. We also use this approach to improve the quantum rejection sampling approach to the Boolean hidden shift problem.
* 29 pages, 2 figures