 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Sep 17, 2025
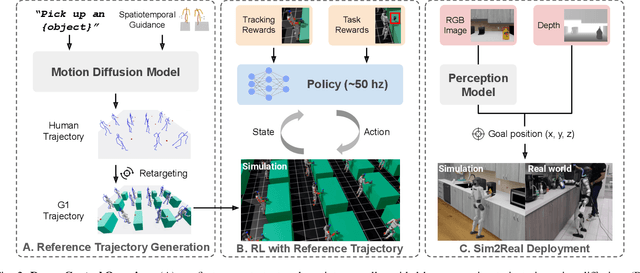

We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
Pretrained Embeddings as a Behavior Specification Mechanism
Mar 03, 2025We propose an approach to formally specifying the behavioral properties of systems that rely on a perception model for interactions with the physical world. The key idea is to introduce embeddings -- mathematical representations of a real-world concept -- as a first-class construct in a specification language, where properties are expressed in terms of distances between a pair of ideal and observed embeddings. To realize this approach, we propose a new type of temporal logic called Embedding Temporal Logic (ETL), and describe how it can be used to express a wider range of properties about AI-enabled systems than previously possible. We demonstrate the applicability of ETL through a preliminary evaluation involving planning tasks in robots that are driven by foundation models; the results are promising, showing that embedding-based specifications can be used to steer a system towards desirable behaviors.
MatMamba: A Matryoshka State Space Model
Oct 09, 2024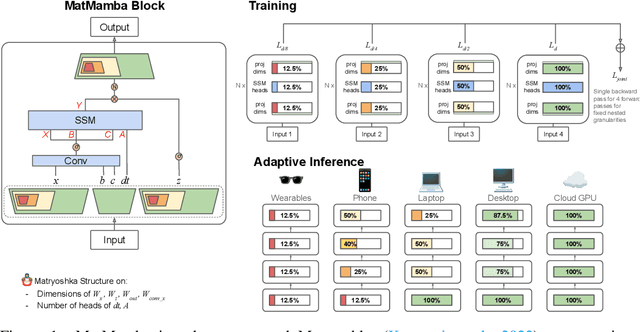



State Space Models (SSMs) like Mamba2 are a promising alternative to Transformers, with faster theoretical training and inference times -- especially for long context lengths. Recent work on Matryoshka Representation Learning -- and its application to Transformer backbones in works like MatFormer -- showed how to introduce nested granularities of smaller submodels in one universal elastic model. In this work, we present MatMamba: a state space model which combines Matryoshka-style learning with Mamba2, by modifying the block to contain nested dimensions to enable joint training and adaptive inference. MatMamba allows for efficient and adaptive deployment across various model sizes. We train a single large MatMamba model and are able to get a number of smaller nested models for free -- while maintaining or improving upon the performance of a baseline smaller model trained from scratch. We train language and image models at a variety of parameter sizes from 35M to 1.4B. Our results on ImageNet and FineWeb show that MatMamba models scale comparably to Transformers, while having more efficient inference characteristics. This makes MatMamba a practically viable option for deploying large-scale models in an elastic way based on the available inference compute. Code and models are open sourced at \url{https://github.com/ScaledFoundations/MatMamba}
Logically Constrained Robotics Transformers for Enhanced Perception-Action Planning
Aug 09, 2024


With the advent of large foundation model based planning, there is a dire need to ensure their output aligns with the stakeholder's intent. When these models are deployed in the real world, the need for alignment is magnified due to the potential cost to life and infrastructure due to unexpected faliures. Temporal Logic specifications have long provided a way to constrain system behaviors and are a natural fit for these use cases. In this work, we propose a novel approach to factor in signal temporal logic specifications while using autoregressive transformer models for trajectory planning. We also provide a trajectory dataset for pretraining and evaluating foundation models. Our proposed technique acheives 74.3 % higher specification satisfaction over the baselines.
Foundation Models in Robotics: Applications, Challenges, and the Future
Dec 13, 2023


We survey applications of pretrained foundation models in robotics. Traditional deep learning models in robotics are trained on small datasets tailored for specific tasks, which limits their adaptability across diverse applications. In contrast, foundation models pretrained on internet-scale data appear to have superior generalization capabilities, and in some instances display an emergent ability to find zero-shot solutions to problems that are not present in the training data. Foundation models may hold the potential to enhance various components of the robot autonomy stack, from perception to decision-making and control. For example, large language models can generate code or provide common sense reasoning, while vision-language models enable open-vocabulary visual recognition. However, significant open research challenges remain, particularly around the scarcity of robot-relevant training data, safety guarantees and uncertainty quantification, and real-time execution. In this survey, we study recent papers that have used or built foundation models to solve robotics problems. We explore how foundation models contribute to improving robot capabilities in the domains of perception, decision-making, and control. We discuss the challenges hindering the adoption of foundation models in robot autonomy and provide opportunities and potential pathways for future advancements. The GitHub project corresponding to this paper (Preliminary release. We are committed to further enhancing and updating this work to ensure its quality and relevance) can be found here: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
GRID: A Platform for General Robot Intelligence Development
Oct 07, 2023



Developing machine intelligence abilities in robots and autonomous systems is an expensive and time consuming process. Existing solutions are tailored to specific applications and are harder to generalize. Furthermore, scarcity of training data adds a layer of complexity in deploying deep machine learning models. We present a new platform for General Robot Intelligence Development (GRID) to address both of these issues. The platform enables robots to learn, compose and adapt skills to their physical capabilities, environmental constraints and goals. The platform addresses AI problems in robotics via foundation models that know the physical world. GRID is designed from the ground up to be extensible to accommodate new types of robots, vehicles, hardware platforms and software protocols. In addition, the modular design enables various deep ML components and existing foundation models to be easily usable in a wider variety of robot-centric problems. We demonstrate the platform in various aerial robotics scenarios and demonstrate how the platform dramatically accelerates development of machine intelligent robots.
EvDNeRF: Reconstructing Event Data with Dynamic Neural Radiance Fields
Oct 03, 2023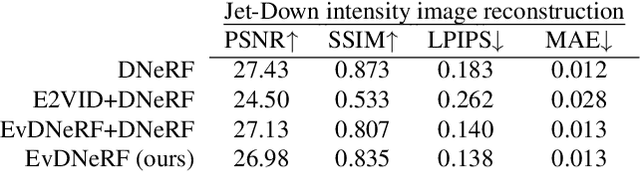


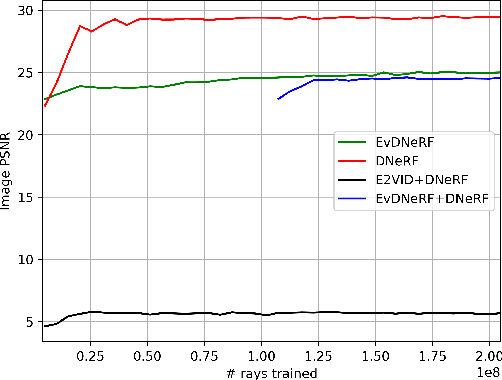
We present EvDNeRF, a pipeline for generating event data and training an event-based dynamic NeRF, for the purpose of faithfully reconstructing eventstreams on scenes with rigid and non-rigid deformations that may be too fast to capture with a standard camera. Event cameras register asynchronous per-pixel brightness changes at MHz rates with high dynamic range, making them ideal for observing fast motion with almost no motion blur. Neural radiance fields (NeRFs) offer visual-quality geometric-based learnable rendering, but prior work with events has only considered reconstruction of static scenes. Our EvDNeRF can predict eventstreams of dynamic scenes from a static or moving viewpoint between any desired timestamps, thereby allowing it to be used as an event-based simulator for a given scene. We show that by training on varied batch sizes of events, we can improve test-time predictions of events at fine time resolutions, outperforming baselines that pair standard dynamic NeRFs with event simulators. We release our simulated and real datasets, as well as code for both event-based data generation and the training of event-based dynamic NeRF models (https://github.com/anish-bhattacharya/EvDNeRF).
Is Imitation All You Need? Generalized Decision-Making with Dual-Phase Training
Jul 18, 2023



We introduce DualMind, a generalist agent designed to tackle various decision-making tasks that addresses challenges posed by current methods, such as overfitting behaviors and dependence on task-specific fine-tuning. DualMind uses a novel "Dual-phase" training strategy that emulates how humans learn to act in the world. The model first learns fundamental common knowledge through a self-supervised objective tailored for control tasks and then learns how to make decisions based on different contexts through imitating behaviors conditioned on given prompts. DualMind can handle tasks across domains, scenes, and embodiments using just a single set of model weights and can execute zero-shot prompting without requiring task-specific fine-tuning. We evaluate DualMind on MetaWorld and Habitat through extensive experiments and demonstrate its superior generalizability compared to previous techniques, outperforming other generalist agents by over 50$\%$ and 70$\%$ on Habitat and MetaWorld, respectively. On the 45 tasks in MetaWorld, DualMind achieves over 30 tasks at a 90$\%$ success rate.
ConBaT: Control Barrier Transformer for Safe Policy Learning
Mar 07, 2023Large-scale self-supervised models have recently revolutionized our ability to perform a variety of tasks within the vision and language domains. However, using such models for autonomous systems is challenging because of safety requirements: besides executing correct actions, an autonomous agent must also avoid the high cost and potentially fatal critical mistakes. Traditionally, self-supervised training mainly focuses on imitating previously observed behaviors, and the training demonstrations carry no notion of which behaviors should be explicitly avoided. In this work, we propose Control Barrier Transformer (ConBaT), an approach that learns safe behaviors from demonstrations in a self-supervised fashion. ConBaT is inspired by the concept of control barrier functions in control theory and uses a causal transformer that learns to predict safe robot actions autoregressively using a critic that requires minimal safety data labeling. During deployment, we employ a lightweight online optimization to find actions that ensure future states lie within the learned safe set. We apply our approach to different simulated control tasks and show that our method results in safer control policies compared to other classical and learning-based methods such as imitation learning, reinforcement learning, and model predictive control.
SMART: Self-supervised Multi-task pretrAining with contRol Transformers
Jan 24, 2023



Self-supervised pretraining has been extensively studied in language and vision domains, where a unified model can be easily adapted to various downstream tasks by pretraining representations without explicit labels. When it comes to sequential decision-making tasks, however, it is difficult to properly design such a pretraining approach that can cope with both high-dimensional perceptual information and the complexity of sequential control over long interaction horizons. The challenge becomes combinatorially more complex if we want to pretrain representations amenable to a large variety of tasks. To tackle this problem, in this work, we formulate a general pretraining-finetuning pipeline for sequential decision making, under which we propose a generic pretraining framework \textit{Self-supervised Multi-task pretrAining with contRol Transformer (SMART)}. By systematically investigating pretraining regimes, we carefully design a Control Transformer (CT) coupled with a novel control-centric pretraining objective in a self-supervised manner. SMART encourages the representation to capture the common essential information relevant to short-term control and long-term control, which is transferrable across tasks. We show by extensive experiments in DeepMind Control Suite that SMART significantly improves the learning efficiency among seen and unseen downstream tasks and domains under different learning scenarios including Imitation Learning (IL) and Reinforcement Learning (RL). Benefiting from the proposed control-centric objective, SMART is resilient to distribution shift between pretraining and finetuning, and even works well with low-quality pretraining datasets that are randomly collected.