 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatMamba: A Matryoshka State Space Model
Paper and Code
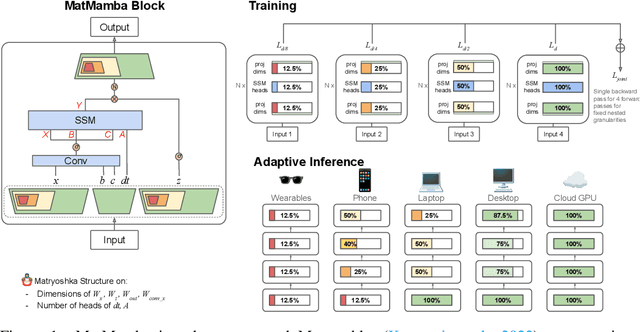



State Space Models (SSMs) like Mamba2 are a promising alternative to Transformers, with faster theoretical training and inference times -- especially for long context lengths. Recent work on Matryoshka Representation Learning -- and its application to Transformer backbones in works like MatFormer -- showed how to introduce nested granularities of smaller submodels in one universal elastic model. In this work, we present MatMamba: a state space model which combines Matryoshka-style learning with Mamba2, by modifying the block to contain nested dimensions to enable joint training and adaptive inference. MatMamba allows for efficient and adaptive deployment across various model sizes. We train a single large MatMamba model and are able to get a number of smaller nested models for free -- while maintaining or improving upon the performance of a baseline smaller model trained from scratch. We train language and image models at a variety of parameter sizes from 35M to 1.4B. Our results on ImageNet and FineWeb show that MatMamba models scale comparably to Transformers, while having more efficient inference characteristics. This makes MatMamba a practically viable option for deploying large-scale models in an elastic way based on the available inference compute. Code and models are open sourced at \url{https://github.com/ScaledFoundations/MatMamba}