 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuRe: Cultural Gaps in the Long Tail of Text-to-Image Systems
Jun 09, 2025Popular text-to-image (T2I) systems are trained on web-scraped data, which is heavily Amero and Euro-centric, underrepresenting the cultures of the Global South. To analyze these biases, we introduce CuRe, a novel and scalable benchmarking and scoring suite for cultural representativeness that leverages the marginal utility of attribute specification to T2I systems as a proxy for human judgments. Our CuRe benchmark dataset has a novel categorical hierarchy built from the crowdsourced Wikimedia knowledge graph, with 300 cultural artifacts across 32 cultural subcategories grouped into six broad cultural axes (food, art, fashion, architecture, celebrations, and people). Our dataset's categorical hierarchy enables CuRe scorers to evaluate T2I systems by analyzing their response to increasing the informativeness of text conditioning, enabling fine-grained cultural comparisons. We empirically observe much stronger correlations of our class of scorers to human judgments of perceptual similarity, image-text alignment, and cultural diversity across image encoders (SigLIP 2, AIMV2 and DINOv2), vision-language models (OpenCLIP, SigLIP 2, Gemini 2.0 Flash) and state-of-the-art text-to-image systems, including three variants of Stable Diffusion (1.5, XL, 3.5 Large), FLUX.1 [dev], Ideogram 2.0, and DALL-E 3. The code and dataset is open-sourced and available at https://aniketrege.github.io/cure/.
Matryoshka Quantization
Feb 10, 2025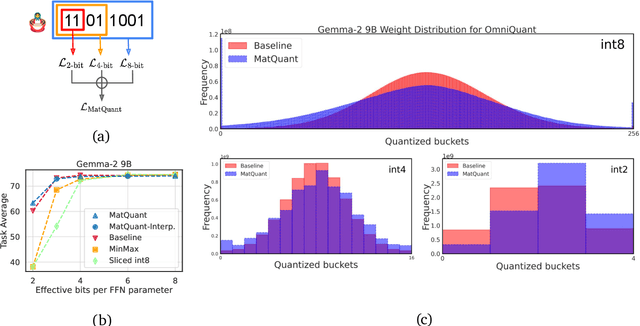
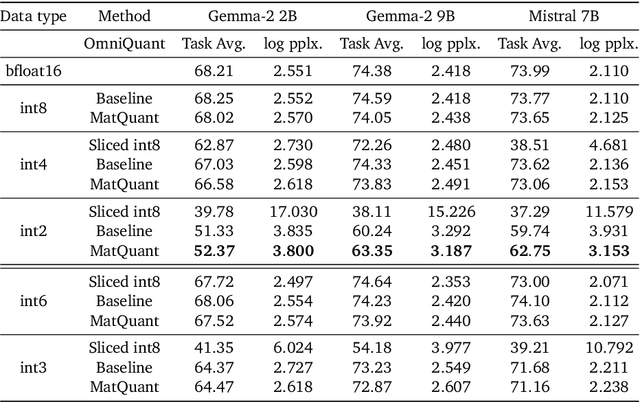
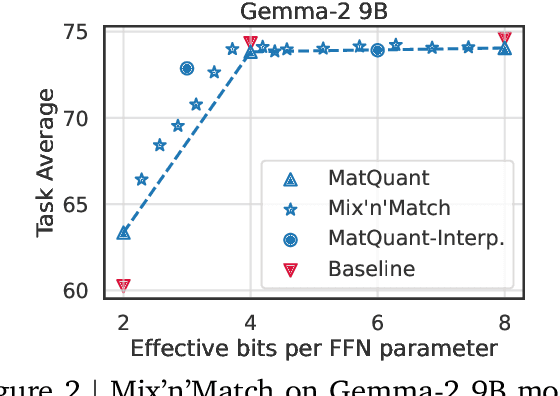
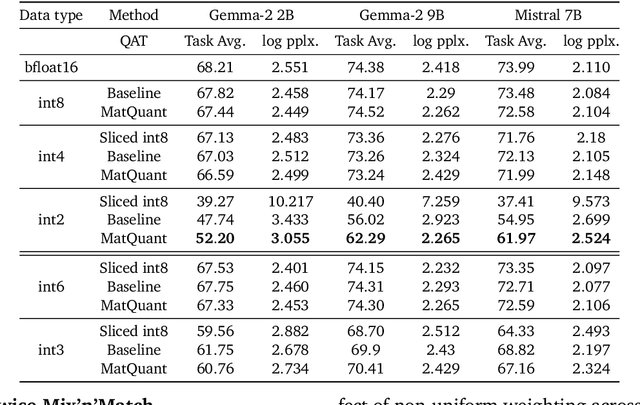
Quantizing model weights is critical for reducing the communication and inference costs of large models. However, quantizing models -- especially to low precisions like int4 or int2 -- requires a trade-off in model quality; int2, in particular, is known to severely degrade model quality. Consequently, practitioners are often forced to maintain multiple models with different quantization levels or serve a single model that best satisfies the quality-latency trade-off. On the other hand, integer data types, such as int8, inherently possess a nested (Matryoshka) structure where smaller bit-width integers, like int4 or int2, are nested within the most significant bits. This paper proposes Matryoshka Quantization (MatQuant), a novel multi-scale quantization technique that addresses the challenge of needing multiple quantized models. It allows training and maintaining just one model, which can then be served at different precision levels. Furthermore, due to the co-training and co-distillation regularization provided by MatQuant, the int2 precision models extracted by MatQuant can be up to $10\%$ more accurate than standard int2 quantization (using techniques like QAT or OmniQuant). This represents significant progress in model quantization, demonstrated by the fact that, with the same recipe, an int2 FFN-quantized Gemma-2 9B model is more accurate than an int8 FFN-quantized Gemma-2 2B model.
From an Image to a Scene: Learning to Imagine the World from a Million 360 Videos
Dec 10, 2024Three-dimensional (3D) understanding of objects and scenes play a key role in humans' ability to interact with the world and has been an active area of research in computer vision, graphics, and robotics. Large scale synthetic and object-centric 3D datasets have shown to be effective in training models that have 3D understanding of objects. However, applying a similar approach to real-world objects and scenes is difficult due to a lack of large-scale data. Videos are a potential source for real-world 3D data, but finding diverse yet corresponding views of the same content has shown to be difficult at scale. Furthermore, standard videos come with fixed viewpoints, determined at the time of capture. This restricts the ability to access scenes from a variety of more diverse and potentially useful perspectives. We argue that large scale 360 videos can address these limitations to provide: scalable corresponding frames from diverse views. In this paper, we introduce 360-1M, a 360 video dataset, and a process for efficiently finding corresponding frames from diverse viewpoints at scale. We train our diffusion-based model, Odin, on 360-1M. Empowered by the largest real-world, multi-view dataset to date, Odin is able to freely generate novel views of real-world scenes. Unlike previous methods, Odin can move the camera through the environment, enabling the model to infer the geometry and layout of the scene. Additionally, we show improved performance on standard novel view synthesis and 3D reconstruction benchmarks.
MatMamba: A Matryoshka State Space Model
Oct 09, 2024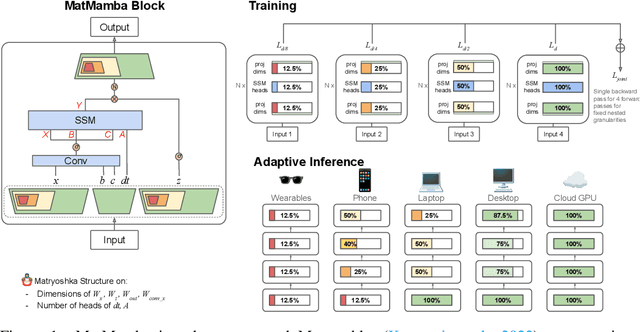



State Space Models (SSMs) like Mamba2 are a promising alternative to Transformers, with faster theoretical training and inference times -- especially for long context lengths. Recent work on Matryoshka Representation Learning -- and its application to Transformer backbones in works like MatFormer -- showed how to introduce nested granularities of smaller submodels in one universal elastic model. In this work, we present MatMamba: a state space model which combines Matryoshka-style learning with Mamba2, by modifying the block to contain nested dimensions to enable joint training and adaptive inference. MatMamba allows for efficient and adaptive deployment across various model sizes. We train a single large MatMamba model and are able to get a number of smaller nested models for free -- while maintaining or improving upon the performance of a baseline smaller model trained from scratch. We train language and image models at a variety of parameter sizes from 35M to 1.4B. Our results on ImageNet and FineWeb show that MatMamba models scale comparably to Transformers, while having more efficient inference characteristics. This makes MatMamba a practically viable option for deploying large-scale models in an elastic way based on the available inference compute. Code and models are open sourced at \url{https://github.com/ScaledFoundations/MatMamba}
ActionAtlas: A VideoQA Benchmark for Domain-specialized Action Recognition
Oct 08, 2024


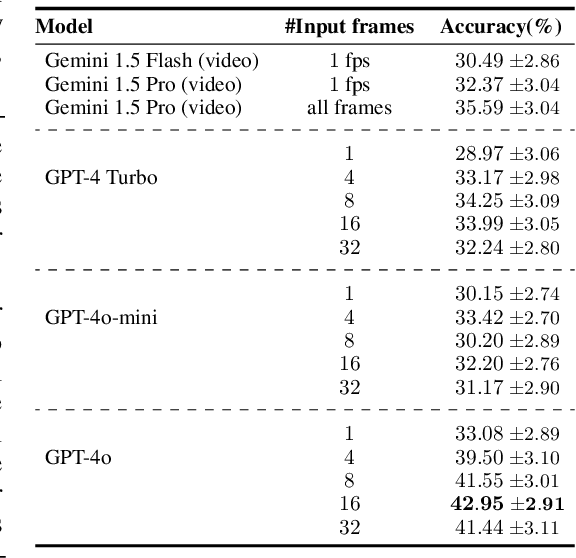
Our world is full of varied actions and moves across specialized domains that we, as humans, strive to identify and understand. Within any single domain, actions can often appear quite similar, making it challenging for deep models to distinguish them accurately. To evaluate the effectiveness of multimodal foundation models in helping us recognize such actions, we present ActionAtlas v1.0, a multiple-choice video question answering benchmark featuring short videos across various sports. Each video in the dataset is paired with a question and four or five choices. The question pinpoints specific individuals, asking which choice "best" describes their action within a certain temporal context. Overall, the dataset includes 934 videos showcasing 580 unique actions across 56 sports, with a total of 1896 actions within choices. Unlike most existing video question answering benchmarks that only cover simplistic actions, often identifiable from a single frame, ActionAtlas focuses on intricate movements and rigorously tests the model's capability to discern subtle differences between moves that look similar within each domain. We evaluate open and proprietary foundation models on this benchmark, finding that the best model, GPT-4o, achieves a maximum accuracy of 45.52%. Meanwhile, Non-expert crowd workers, provided with action description for each choice, achieve 61.64% accuracy, where random chance is approximately 21%. Our findings with state-of-the-art models indicate that having a high frame sampling rate is important for accurately recognizing actions in ActionAtlas, a feature that some leading proprietary video models, such as Gemini, do not include in their default configuration.
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
Jul 29, 2024

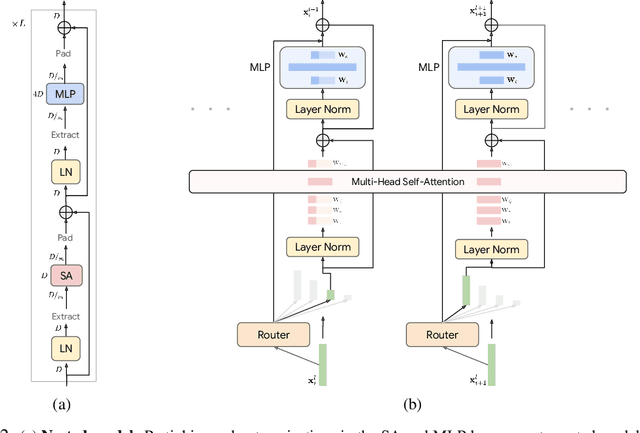
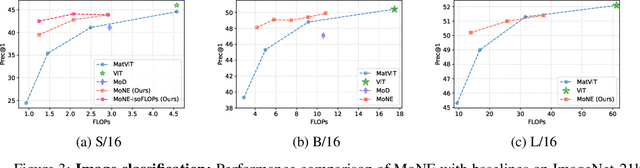
The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing. While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining same inference-time costs, but they come with a larger parameter footprint. We present Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve. Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts. Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets - ImageNet-21K, Kinetics400, and Something-Something-v2. We further highlight MoNE$'$s adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.
Superposed Decoding: Multiple Generations from a Single Autoregressive Inference Pass
May 29, 2024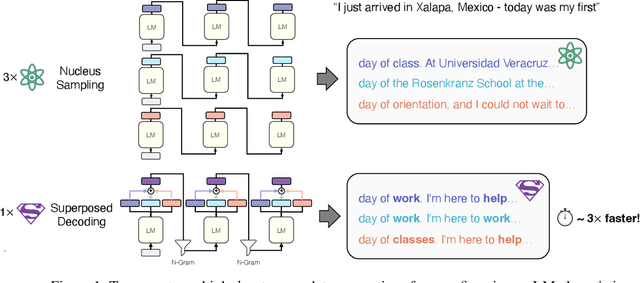

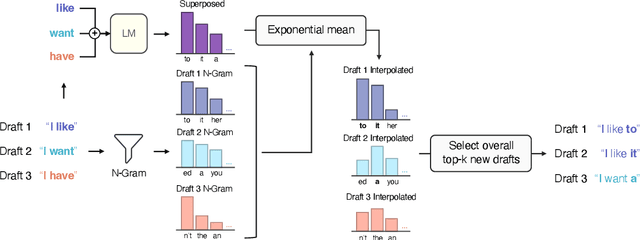

Many applications today provide users with multiple auto-complete drafts as they type, including GitHub's code completion, Gmail's smart compose, and Apple's messaging auto-suggestions. Under the hood, language models support this by running an autoregressive inference pass to provide a draft. Consequently, providing $k$ drafts to the user requires running an expensive language model $k$ times. To alleviate the computation cost of running $k$ inference passes, we propose Superposed Decoding, a new decoding algorithm that generates $k$ drafts at the computation cost of one autoregressive inference pass. We achieve this by feeding a superposition of the most recent token embeddings from the $k$ drafts as input to the next decoding step of the language model. At every inference step we combine the $k$ drafts with the top-$k$ tokens to get $k^2$ new drafts and cache the $k$ most likely options, using an n-gram interpolation with minimal compute overhead to filter out incoherent generations. Our experiments show that $k$ drafts from Superposed Decoding are at least as coherent and factual as Nucleus Sampling and Greedy Decoding respectively, while being at least $2.44\times$ faster for $k\ge3$. In a compute-normalized setting, user evaluations demonstrably favor text generated by Superposed Decoding over Nucleus Sampling. Code and more examples open-sourced at https://github.com/RAIVNLab/SuperposedDecoding.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024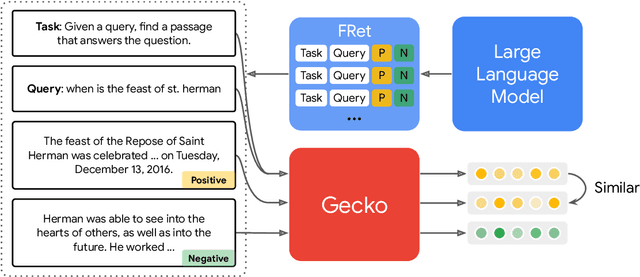
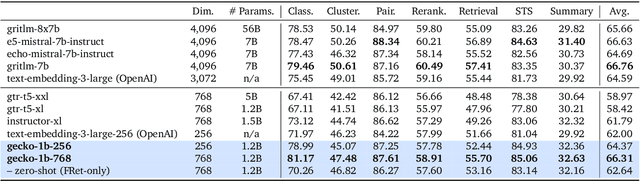

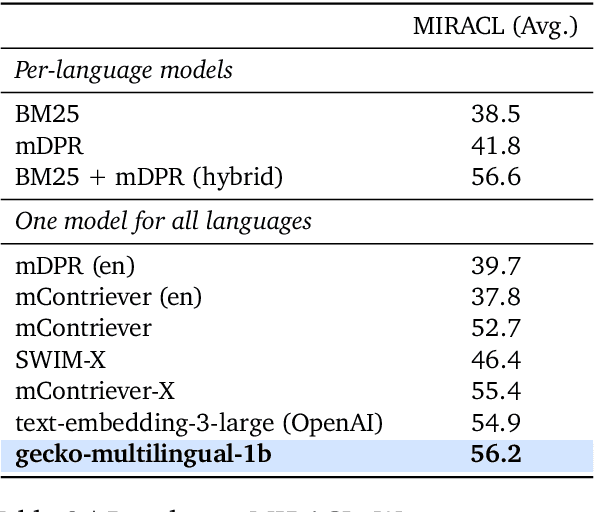
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Are "Hierarchical" Visual Representations Hierarchical?
Nov 23, 2023Learned visual representations often capture large amounts of semantic information for accurate downstream applications. Human understanding of the world is fundamentally grounded in hierarchy. To mimic this and further improve representation capabilities, the community has explored "hierarchical" visual representations that aim at modeling the underlying hierarchy of the visual world. In this work, we set out to investigate if hierarchical visual representations truly capture the human perceived hierarchy better than standard learned representations. To this end, we create HierNet, a suite of 12 datasets spanning 3 kinds of hierarchy from the BREEDs subset of ImageNet. After extensive evaluation of Hyperbolic and Matryoshka Representations across training setups, we conclude that they do not capture hierarchy any better than the standard representations but can assist in other aspects like search efficiency and interpretability. Our benchmark and the datasets are open-sourced at https://github.com/ethanlshen/HierNet.
SHARCS: Efficient Transformers through Routing with Dynamic Width Sub-networks
Oct 18, 2023



We introduce SHARCS for adaptive inference that takes into account the hardness of input samples. SHARCS can train a router on any transformer network, enabling the model to direct different samples to sub-networks with varying widths. Our experiments demonstrate that: (1) SHARCS outperforms or complements existing per-sample adaptive inference methods across various classification tasks in terms of accuracy vs. FLOPs; (2) SHARCS generalizes across different architectures and can be even applied to compressed and efficient transformer encoders to further improve their efficiency; (3) SHARCS can provide a 2 times inference speed up at an insignificant drop in accuracy.