 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Keep a Secret? Involuntary Information Leakage in Language Model Writing
May 11, 2026Language models are deployed in settings that require compartmentalization: system prompts should not be disclosed, chain-of-thought reasoning is hidden from users, and sensitive data passes through shared contexts. We test whether models can keep prompted information out of their writing. We give each model a secret word with instructions not to reveal it, then ask it to write a story. A second model tries to identify the secret from the story in a binary discrimination test. The secret word never appears literally in any output, but all five frontier models we test leak it thematically -- through topic choice, imagery, and setting--6hy-at rates significantly different from chance, up to 79\%. When told to actively hide the secret, models write \emph{away from} it, and this avoidance is itself detectable. The leakage is cross-model readable, scales sharply with model size within two model families, and disappears entirely for short-form writing like jokes. Giving the model a decoy concept to ``focus on instead'' partially redirects the leakage from the real secret to the decoy. Attending to a secret appears to open up an information channel that frontier LLMs cannot close, even when instructed to.
Spoiler Alert: Narrative Forecasting as a Metric for Tension in LLM Storytelling
Apr 10, 2026LLMs have so far failed both to generate consistently compelling stories and to recognize this failure--on the leading creative-writing benchmark (EQ-Bench), LLM judges rank zero-shot AI stories above New Yorker short stories, a gold standard for literary fiction. We argue that existing rubrics overlook a key dimension of compelling human stories: narrative tension. We introduce the 100-Endings metric, which walks through a story sentence by sentence: at each position, a model predicts how the story will end 100 times given only the text so far, and we measure tension as how often predictions fail to match the ground truth. Beyond the mismatch rate, the sentence-level curve yields complementary statistics, such as inflection rate, a geometric measure of how frequently the curve reverses direction, tracking twists and revelations. Unlike rubric-based judges, 100-Endings correctly ranks New Yorker stories far above LLM outputs. Grounded in narratological principles, we design a story-generation pipeline using structural constraints, including analysis of story templates, idea formulation, and narrative scaffolding. Our pipeline significantly increases narrative tension as measured by the 100-Endings metric, while maintaining performance on the EQ-Bench leaderboard.
AI as Entertainment
Jan 13, 2026Generative AI systems are predominantly designed, evaluated, and marketed as intelligent systems which will benefit society by augmenting or automating human cognitive labor, promising to increase personal, corporate, and macroeconomic productivity. But this mainstream narrative about what AI is and what it can do is in tension with another emerging use case: entertainment. We argue that the field of AI is unprepared to measure or respond to how the proliferation of entertaining AI-generated content will impact society. Emerging data suggest AI is already widely adopted for entertainment purposes -- especially by young people -- and represents a large potential source of revenue. We contend that entertainment will become a primary business model for major AI corporations seeking returns on massive infrastructure investments; this will exert a powerful influence on the technology these companies produce in the coming years. Examining current evaluation practices, we identify a critical asymmetry: while AI assessments rigorously measure both benefits and harms of intelligence, they focus almost exclusively on cultural harms. We lack frameworks for articulating how cultural outputs might be actively beneficial. Drawing on insights from the humanities, we propose "thick entertainment" as a framework for evaluating AI-generated cultural content -- one that considers entertainment's role in meaning-making, identity formation, and social connection rather than simply minimizing harm. While AI is often touted for its potential to revolutionize productivity, in the long run we may find that AI turns out to be as much about "intelligence" as social media is about social connection.
LL3M: Large Language 3D Modelers
Aug 11, 2025

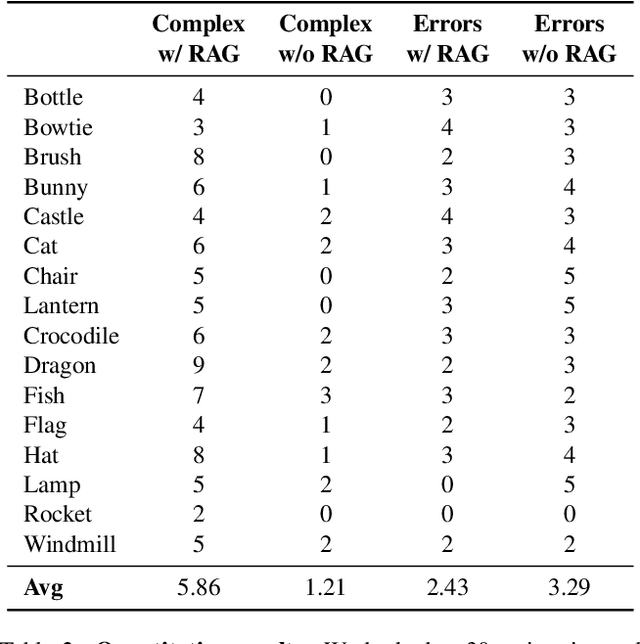

We present LL3M, a multi-agent system that leverages pretrained large language models (LLMs) to generate 3D assets by writing interpretable Python code in Blender. We break away from the typical generative approach that learns from a collection of 3D data. Instead, we reformulate shape generation as a code-writing task, enabling greater modularity, editability, and integration with artist workflows. Given a text prompt, LL3M coordinates a team of specialized LLM agents to plan, retrieve, write, debug, and refine Blender scripts that generate and edit geometry and appearance. The generated code works as a high-level, interpretable, human-readable, well-documented representation of scenes and objects, making full use of sophisticated Blender constructs (e.g. B-meshes, geometry modifiers, shader nodes) for diverse, unconstrained shapes, materials, and scenes. This code presents many avenues for further agent and human editing and experimentation via code tweaks or procedural parameters. This medium naturally enables a co-creative loop in our system: agents can automatically self-critique using code and visuals, while iterative user instructions provide an intuitive way to refine assets. A shared code context across agents enables awareness of previous attempts, and a retrieval-augmented generation knowledge base built from Blender API documentation, BlenderRAG, equips agents with examples, types, and functions empowering advanced modeling operations and code correctness. We demonstrate the effectiveness of LL3M across diverse shape categories, style and material edits, and user-driven refinements. Our experiments showcase the power of code as a generative and interpretable medium for 3D asset creation. Our project page is at https://threedle.github.io/ll3m.
Multiple Streams of Relation Extraction: Enriching and Recalling in Transformers
Jun 25, 2025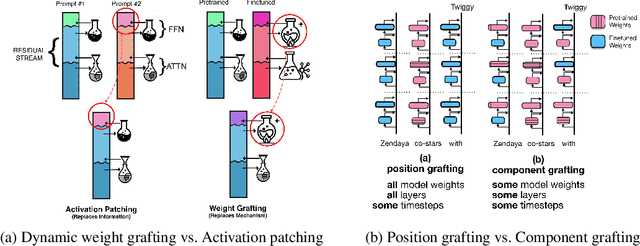

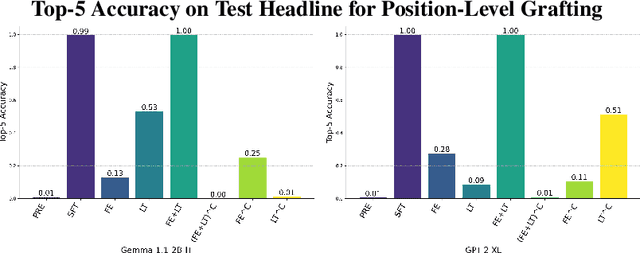

When an LLM learns a relation during finetuning (e.g., new movie releases, corporate mergers, etc.), where does this information go? Is it extracted when the model processes an entity, recalled just-in-time before a prediction, or are there multiple separate heuristics? Existing localization approaches (e.g. activation patching) are ill-suited for this analysis because they tend to replace parts of the residual stream, potentially deleting information. To fill this gap, we propose dynamic weight-grafting between fine-tuned and pre-trained language models to show that fine-tuned language models both (1) extract relation information learned during finetuning while processing entities and (2) ``recall" this information in later layers while generating predictions. In some cases, models need both of these pathways to correctly generate finetuned information while, in other cases, a single ``enrichment" or ``recall" pathway alone is sufficient. We examine the necessity and sufficiency of these information pathways, examining what layers they occur at, how much redundancy they exhibit, and which model components are involved -- finding that the ``recall" pathway occurs via both task-specific attention mechanisms and a relation extraction step in the output of the attention and the feedforward networks at the final layers before next token prediction.
AbsenceBench: Language Models Can't Tell What's Missing
Jun 13, 2025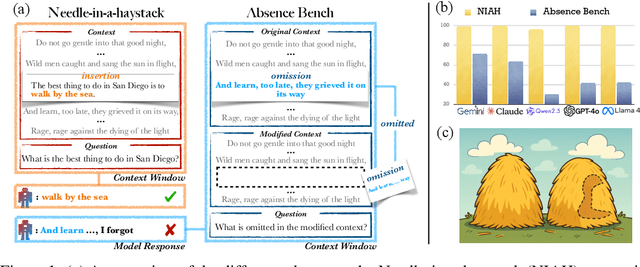

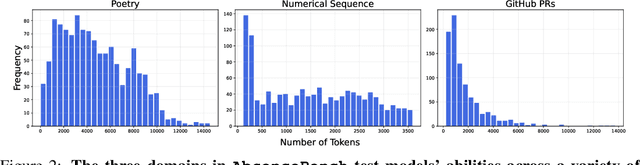

Large language models (LLMs) are increasingly capable of processing long inputs and locating specific information within them, as evidenced by their performance on the Needle in a Haystack (NIAH) test. However, while models excel at recalling surprising information, they still struggle to identify clearly omitted information. We introduce AbsenceBench to assesses LLMs' capacity to detect missing information across three domains: numerical sequences, poetry, and GitHub pull requests. AbsenceBench asks models to identify which pieces of a document were deliberately removed, given access to both the original and edited contexts. Despite the apparent straightforwardness of these tasks, our experiments reveal that even state-of-the-art models like Claude-3.7-Sonnet achieve only 69.6% F1-score with a modest average context length of 5K tokens. Our analysis suggests this poor performance stems from a fundamental limitation: Transformer attention mechanisms cannot easily attend to "gaps" in documents since these absences don't correspond to any specific keys that can be attended to. Overall, our results and analysis provide a case study of the close proximity of tasks where models are already superhuman (NIAH) and tasks where models breakdown unexpectedly (AbsenceBench).
Byte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
Forking Paths in Neural Text Generation
Dec 10, 2024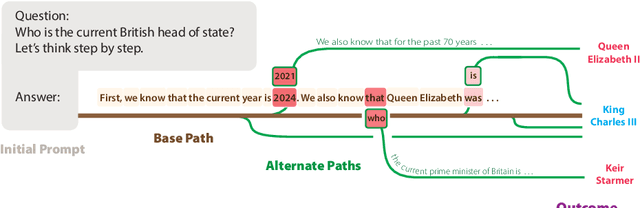
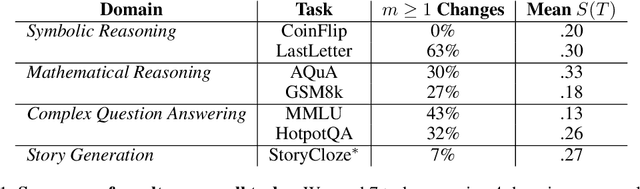
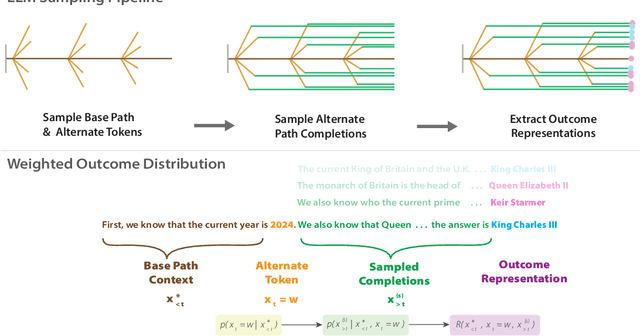
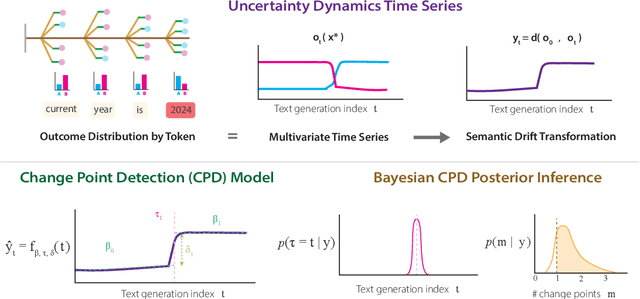
Estimating uncertainty in Large Language Models (LLMs) is important for properly evaluating LLMs, and ensuring safety for users. However, prior approaches to uncertainty estimation focus on the final answer in generated text, ignoring intermediate steps that might dramatically impact the outcome. We hypothesize that there exist key forking tokens, such that re-sampling the system at those specific tokens, but not others, leads to very different outcomes. To test this empirically, we develop a novel approach to representing uncertainty dynamics across individual tokens of text generation, and applying statistical models to test our hypothesis. Our approach is highly flexible: it can be applied to any dataset and any LLM, without fine tuning or accessing model weights. We use our method to analyze LLM responses on 7 different tasks across 4 domains, spanning a wide range of typical use cases. We find many examples of forking tokens, including surprising ones such as punctuation marks, suggesting that LLMs are often just a single token away from saying something very different.
Benchmarks as Microscopes: A Call for Model Metrology
Jul 22, 2024Modern language models (LMs) pose a new challenge in capability assessment. Static benchmarks inevitably saturate without providing confidence in the deployment tolerances of LM-based systems, but developers nonetheless claim that their models have generalized traits such as reasoning or open-domain language understanding based on these flawed metrics. The science and practice of LMs requires a new approach to benchmarking which measures specific capabilities with dynamic assessments. To be confident in our metrics, we need a new discipline of model metrology -- one which focuses on how to generate benchmarks that predict performance under deployment. Motivated by our evaluation criteria, we outline how building a community of model metrology practitioners -- one focused on building tools and studying how to measure system capabilities -- is the best way to meet these needs to and add clarity to the AI discussion.
MUSE: Machine Unlearning Six-Way Evaluation for Language Models
Jul 08, 2024Language models (LMs) are trained on vast amounts of text data, which may include private and copyrighted content. Data owners may request the removal of their data from a trained model due to privacy or copyright concerns. However, exactly unlearning only these datapoints (i.e., retraining with the data removed) is intractable in modern-day models. This has led to the development of many approximate unlearning algorithms. The evaluation of the efficacy of these algorithms has traditionally been narrow in scope, failing to precisely quantify the success and practicality of the algorithm from the perspectives of both the model deployers and the data owners. We address this issue by proposing MUSE, a comprehensive machine unlearning evaluation benchmark that enumerates six diverse desirable properties for unlearned models: (1) no verbatim memorization, (2) no knowledge memorization, (3) no privacy leakage, (4) utility preservation on data not intended for removal, (5) scalability with respect to the size of removal requests, and (6) sustainability over sequential unlearning requests. Using these criteria, we benchmark how effectively eight popular unlearning algorithms on 7B-parameter LMs can unlearn Harry Potter books and news articles. Our results demonstrate that most algorithms can prevent verbatim memorization and knowledge memorization to varying degrees, but only one algorithm does not lead to severe privacy leakage. Furthermore, existing algorithms fail to meet deployer's expectations because they often degrade general model utility and also cannot sustainably accommodate successive unlearning requests or large-scale content removal. Our findings identify key issues with the practicality of existing unlearning algorithms on language models, and we release our benchmark to facilitate further evaluations: muse-bench.github.io