 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Information Geometry of Softmax: Probing and Steering
Feb 17, 2026This paper concerns the question of how AI systems encode semantic structure into the geometric structure of their representation spaces. The motivating observation of this paper is that the natural geometry of these representation spaces should reflect the way models use representations to produce behavior. We focus on the important special case of representations that define softmax distributions. In this case, we argue that the natural geometry is information geometry. Our focus is on the role of information geometry on semantic encoding and the linear representation hypothesis. As an illustrative application, we develop "dual steering", a method for robustly steering representations to exhibit a particular concept using linear probes. We prove that dual steering optimally modifies the target concept while minimizing changes to off-target concepts. Empirically, we find that dual steering enhances the controllability and stability of concept manipulation.
Multiple Streams of Relation Extraction: Enriching and Recalling in Transformers
Jun 25, 2025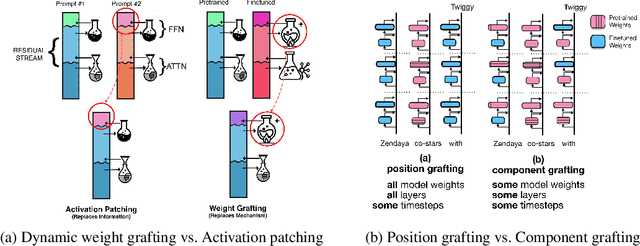

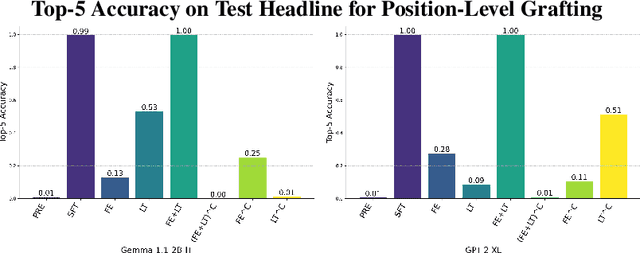

When an LLM learns a relation during finetuning (e.g., new movie releases, corporate mergers, etc.), where does this information go? Is it extracted when the model processes an entity, recalled just-in-time before a prediction, or are there multiple separate heuristics? Existing localization approaches (e.g. activation patching) are ill-suited for this analysis because they tend to replace parts of the residual stream, potentially deleting information. To fill this gap, we propose dynamic weight-grafting between fine-tuned and pre-trained language models to show that fine-tuned language models both (1) extract relation information learned during finetuning while processing entities and (2) ``recall" this information in later layers while generating predictions. In some cases, models need both of these pathways to correctly generate finetuned information while, in other cases, a single ``enrichment" or ``recall" pathway alone is sufficient. We examine the necessity and sufficiency of these information pathways, examining what layers they occur at, how much redundancy they exhibit, and which model components are involved -- finding that the ``recall" pathway occurs via both task-specific attention mechanisms and a relation extraction step in the output of the attention and the feedforward networks at the final layers before next token prediction.
SoK: On Finding Common Ground in Loss Landscapes Using Deep Model Merging Techniques
Oct 16, 2024



Understanding neural networks is crucial to creating reliable and trustworthy deep learning models. Most contemporary research in interpretability analyzes just one model at a time via causal intervention or activation analysis. Yet despite successes, these methods leave significant gaps in our understanding of the training behaviors of neural networks, how their inner representations emerge, and how we can predictably associate model components with task-specific behaviors. Seeking new insights from work in related fields, here we survey literature in the field of model merging, a field that aims to combine the abilities of various neural networks by merging their parameters and identifying task-specific model components in the process. We analyze the model merging literature through the lens of loss landscape geometry, an approach that enables us to connect observations from empirical studies on interpretability, security, model merging, and loss landscape analysis to phenomena that govern neural network training and the emergence of their inner representations. To systematize knowledge in this area, we present a novel taxonomy of model merging techniques organized by their core algorithmic principles. Additionally, we distill repeated empirical observations from the literature in these fields into characterizations of four major aspects of loss landscape geometry: mode convexity, determinism, directedness, and connectivity. We argue that by improving our understanding of the principles underlying model merging and loss landscape geometry, this work contributes to the goal of ensuring secure and trustworthy machine learning in practice.
RATE: Score Reward Models with Imperfect Rewrites of Rewrites
Oct 15, 2024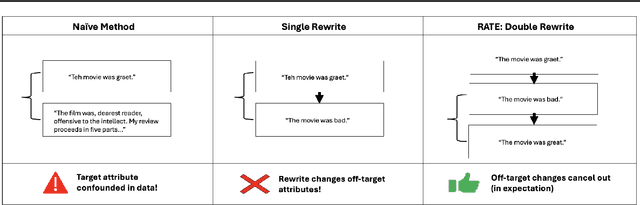

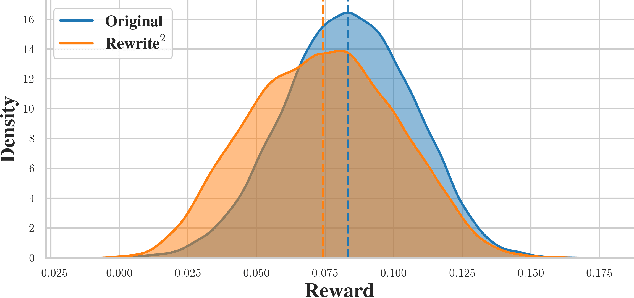
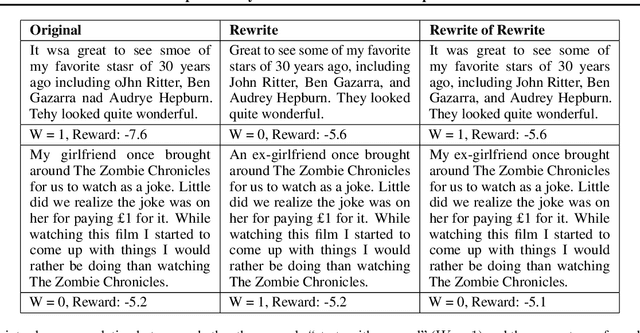
This paper concerns the evaluation of reward models used in language modeling. A reward model is a function that takes a prompt and a response and assigns a score indicating how good that response is for the prompt. A key challenge is that reward models are usually imperfect proxies for actual preferences. For example, we may worry that a model trained to reward helpfulness learns to instead prefer longer responses. In this paper, we develop an evaluation method, RATE (Rewrite-based Attribute Treatment Estimators), that allows us to measure the causal effect of a given attribute of a response (e.g., length) on the reward assigned to that response. The core idea is to use large language models to rewrite responses to produce imperfect counterfactuals, and to adjust for rewriting error by rewriting twice. We show that the RATE estimator is consistent under reasonable assumptions. We demonstrate the effectiveness of RATE on synthetic and real-world data, showing that it can accurately estimate the effect of a given attribute on the reward model.