 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Aware Knowledge Propagation in Decentralized Learning
May 16, 2025Decentralized learning enables collaborative training of models across naturally distributed data without centralized coordination or maintenance of a global model. Instead, devices are organized in arbitrary communication topologies, in which they can only communicate with neighboring devices. Each device maintains its own local model by training on its local data and integrating new knowledge via model aggregation with neighbors. Therefore, knowledge is propagated across the topology via successive aggregation rounds. We study, in particular, the propagation of out-of-distribution (OOD) knowledge. We find that popular decentralized learning algorithms struggle to propagate OOD knowledge effectively to all devices. Further, we find that both the location of OOD data within a topology, and the topology itself, significantly impact OOD knowledge propagation. We then propose topology-aware aggregation strategies to accelerate (OOD) knowledge propagation across devices. These strategies improve OOD data accuracy, compared to topology-unaware baselines, by 123% on average across models in a topology.
SCOPE-MRI: Bankart Lesion Detection as a Case Study in Data Curation and Deep Learning for Challenging Diagnoses
Apr 29, 2025While deep learning has shown strong performance in musculoskeletal imaging, existing work has largely focused on pathologies where diagnosis is not a clinical challenge, leaving more difficult problems underexplored, such as detecting Bankart lesions (anterior-inferior glenoid labral tears) on standard MRIs. Diagnosing these lesions is challenging due to their subtle imaging features, often leading to reliance on invasive MRI arthrograms (MRAs). This study introduces ScopeMRI, the first publicly available, expert-annotated dataset for shoulder pathologies, and presents a deep learning (DL) framework for detecting Bankart lesions on both standard MRIs and MRAs. ScopeMRI includes 586 shoulder MRIs (335 standard, 251 MRAs) from 558 patients who underwent arthroscopy. Ground truth labels were derived from intraoperative findings, the gold standard for diagnosis. Separate DL models for MRAs and standard MRIs were trained using a combination of CNNs and transformers. Predictions from sagittal, axial, and coronal views were ensembled to optimize performance. The models were evaluated on a 20% hold-out test set (117 MRIs: 46 MRAs, 71 standard MRIs). The models achieved an AUC of 0.91 and 0.93, sensitivity of 83% and 94%, and specificity of 91% and 86% for standard MRIs and MRAs, respectively. Notably, model performance on non-invasive standard MRIs matched or surpassed radiologists interpreting MRAs. External validation demonstrated initial generalizability across imaging protocols. This study demonstrates that DL models can achieve radiologist-level diagnostic performance on standard MRIs, reducing the need for invasive MRAs. By releasing ScopeMRI and a modular codebase for training and evaluating deep learning models on 3D medical imaging data, we aim to accelerate research in musculoskeletal imaging and support the development of new datasets for clinically challenging diagnostic tasks.
Toward Non-Invasive Diagnosis of Bankart Lesions with Deep Learning
Dec 09, 2024Bankart lesions, or anterior-inferior glenoid labral tears, are diagnostically challenging on standard MRIs due to their subtle imaging features-often necessitating invasive MRI arthrograms (MRAs). This study develops deep learning (DL) models to detect Bankart lesions on both standard MRIs and MRAs, aiming to improve diagnostic accuracy and reduce reliance on MRAs. We curated a dataset of 586 shoulder MRIs (335 standard, 251 MRAs) from 558 patients who underwent arthroscopy. Ground truth labels were derived from intraoperative findings, the gold standard for Bankart lesion diagnosis. Separate DL models for MRAs and standard MRIs were trained using the Swin Transformer architecture, pre-trained on a public knee MRI dataset. Predictions from sagittal, axial, and coronal views were ensembled to optimize performance. The models were evaluated on a 20% hold-out test set (117 MRIs: 46 MRAs, 71 standard MRIs). Bankart lesions were identified in 31.9% of MRAs and 8.6% of standard MRIs. The models achieved AUCs of 0.87 (86% accuracy, 83% sensitivity, 86% specificity) and 0.90 (85% accuracy, 82% sensitivity, 86% specificity) on standard MRIs and MRAs, respectively. These results match or surpass radiologist performance on our dataset and reported literature metrics. Notably, our model's performance on non-invasive standard MRIs matched or surpassed the radiologists interpreting MRAs. This study demonstrates the feasibility of using DL to address the diagnostic challenges posed by subtle pathologies like Bankart lesions. Our models demonstrate potential to improve diagnostic confidence, reduce reliance on invasive imaging, and enhance accessibility to care.
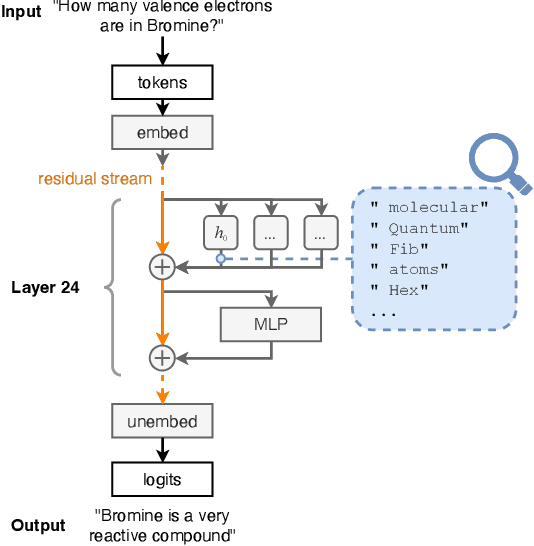
Towards Interpreting Language Models: A Case Study in Multi-Hop Reasoning
Nov 06, 2024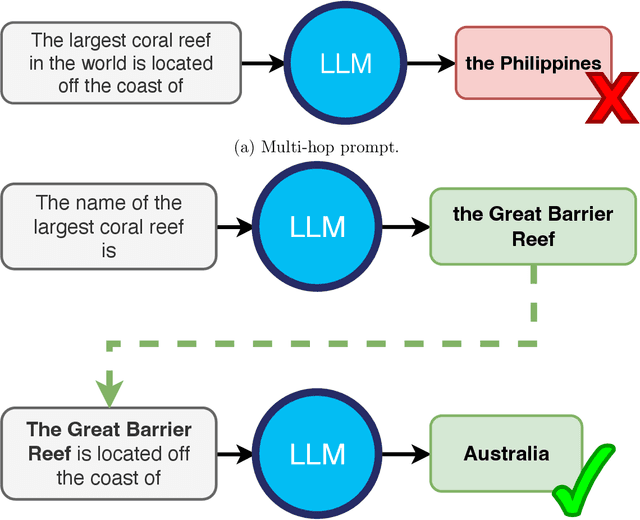

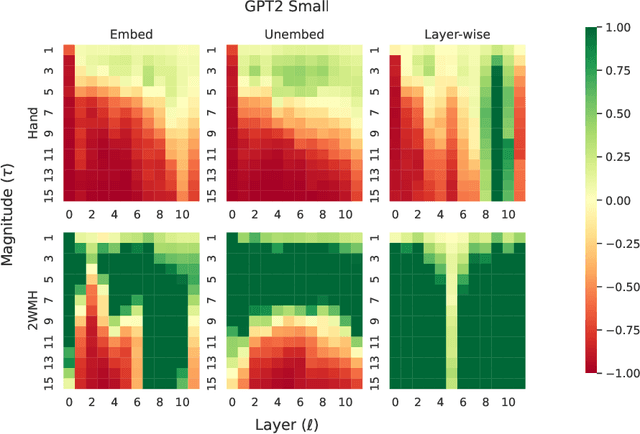
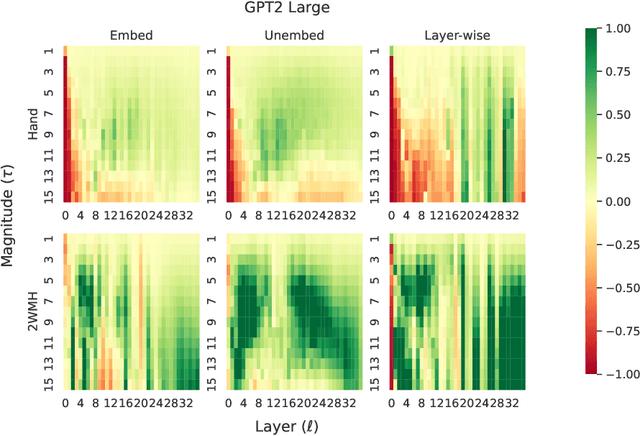
Answering multi-hop reasoning questions requires retrieving and synthesizing information from diverse sources. Language models (LMs) struggle to perform such reasoning consistently. We propose an approach to pinpoint and rectify multi-hop reasoning failures through targeted memory injections on LM attention heads. First, we analyze the per-layer activations of GPT-2 models in response to single- and multi-hop prompts. We then propose a mechanism that allows users to inject relevant prompt-specific information, which we refer to as "memories," at critical LM locations during inference. By thus enabling the LM to incorporate additional relevant information during inference, we enhance the quality of multi-hop prompt completions. We empirically show that a simple, efficient, and targeted memory injection into a key attention layer often increases the probability of the desired next token in multi-hop tasks, by up to 424%. We observe that small subsets of attention heads can significantly impact the model prediction during multi-hop reasoning. To more faithfully interpret these heads, we develop Attention Lens: an open source tool that translates the outputs of attention heads into vocabulary tokens via learned transformations called lenses. We demonstrate the use of lenses to reveal how a model arrives at its answer and use them to localize sources of model failures such as in the case of biased and malicious language generation.
SoK: On Finding Common Ground in Loss Landscapes Using Deep Model Merging Techniques
Oct 16, 2024



Understanding neural networks is crucial to creating reliable and trustworthy deep learning models. Most contemporary research in interpretability analyzes just one model at a time via causal intervention or activation analysis. Yet despite successes, these methods leave significant gaps in our understanding of the training behaviors of neural networks, how their inner representations emerge, and how we can predictably associate model components with task-specific behaviors. Seeking new insights from work in related fields, here we survey literature in the field of model merging, a field that aims to combine the abilities of various neural networks by merging their parameters and identifying task-specific model components in the process. We analyze the model merging literature through the lens of loss landscape geometry, an approach that enables us to connect observations from empirical studies on interpretability, security, model merging, and loss landscape analysis to phenomena that govern neural network training and the emergence of their inner representations. To systematize knowledge in this area, we present a novel taxonomy of model merging techniques organized by their core algorithmic principles. Additionally, we distill repeated empirical observations from the literature in these fields into characterizations of four major aspects of loss landscape geometry: mode convexity, determinism, directedness, and connectivity. We argue that by improving our understanding of the principles underlying model merging and loss landscape geometry, this work contributes to the goal of ensuring secure and trustworthy machine learning in practice.
Mitigating Memorization In Language Models
Oct 03, 2024



Language models (LMs) can "memorize" information, i.e., encode training data in their weights in such a way that inference-time queries can lead to verbatim regurgitation of that data. This ability to extract training data can be problematic, for example, when data are private or sensitive. In this work, we investigate methods to mitigate memorization: three regularizer-based, three finetuning-based, and eleven machine unlearning-based methods, with five of the latter being new methods that we introduce. We also introduce TinyMem, a suite of small, computationally-efficient LMs for the rapid development and evaluation of memorization-mitigation methods. We demonstrate that the mitigation methods that we develop using TinyMem can successfully be applied to production-grade LMs, and we determine via experiment that: regularizer-based mitigation methods are slow and ineffective at curbing memorization; fine-tuning-based methods are effective at curbing memorization, but overly expensive, especially for retaining higher accuracies; and unlearning-based methods are faster and more effective, allowing for the precise localization and removal of memorized information from LM weights prior to inference. We show, in particular, that our proposed unlearning method BalancedSubnet outperforms other mitigation methods at removing memorized information while preserving performance on target tasks.
Trillion Parameter AI Serving Infrastructure for Scientific Discovery: A Survey and Vision
Feb 05, 2024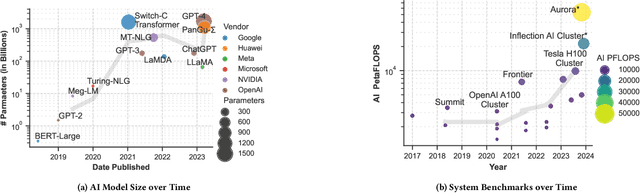
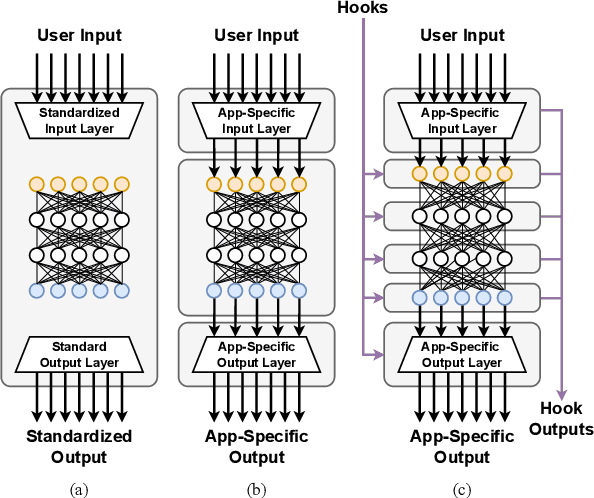
Deep learning methods are transforming research, enabling new techniques, and ultimately leading to new discoveries. As the demand for more capable AI models continues to grow, we are now entering an era of Trillion Parameter Models (TPM), or models with more than a trillion parameters -- such as Huawei's PanGu-$\Sigma$. We describe a vision for the ecosystem of TPM users and providers that caters to the specific needs of the scientific community. We then outline the significant technical challenges and open problems in system design for serving TPMs to enable scientific research and discovery. Specifically, we describe the requirements of a comprehensive software stack and interfaces to support the diverse and flexible requirements of researchers.
Attention Lens: A Tool for Mechanistically Interpreting the Attention Head Information Retrieval Mechanism
Oct 25, 2023

Transformer-based Large Language Models (LLMs) are the state-of-the-art for natural language tasks. Recent work has attempted to decode, by reverse engineering the role of linear layers, the internal mechanisms by which LLMs arrive at their final predictions for text completion tasks. Yet little is known about the specific role of attention heads in producing the final token prediction. We propose Attention Lens, a tool that enables researchers to translate the outputs of attention heads into vocabulary tokens via learned attention-head-specific transformations called lenses. Preliminary findings from our trained lenses indicate that attention heads play highly specialized roles in language models. The code for Attention Lens is available at github.com/msakarvadia/AttentionLens.
Memory Injections: Correcting Multi-Hop Reasoning Failures during Inference in Transformer-Based Language Models
Sep 12, 2023



Answering multi-hop reasoning questions requires retrieving and synthesizing information from diverse sources. Large Language Models (LLMs) struggle to perform such reasoning consistently. Here we propose an approach to pinpoint and rectify multi-hop reasoning failures through targeted memory injections on LLM attention heads. First, we analyze the per-layer activations of GPT-2 models in response to single and multi-hop prompts. We then propose a mechanism that allows users to inject pertinent prompt-specific information, which we refer to as "memories," at critical LLM locations during inference. By thus enabling the LLM to incorporate additional relevant information during inference, we enhance the quality of multi-hop prompt completions. We show empirically that a simple, efficient, and targeted memory injection into a key attention layer can often increase the probability of the desired next token in multi-hop tasks, by up to 424%.