 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Routing to Interpretable Surrogates with Distribution-Free Safety Guarantees
Mar 15, 2026Model routing determines whether to use an accurate black-box model or a simpler surrogate that approximates it at lower cost or greater interpretability. In deployment settings, practitioners often wish to restrict surrogate use to inputs where its degradation relative to a reference model is controlled. We study proactive (input-based) routing, in which a lightweight gate selects the model before either runs, enabling distribution-free control of the fraction of routed inputs whose degradation exceeds a tolerance τ. The gate is trained to distinguish safe from unsafe inputs, and a routing threshold is chosen via Clopper-Pearson conformal calibration on a held-out set, guaranteeing that the routed-set violation rate is at most α with probability 1-δ. We derive a feasibility condition linking safe routing to the base safe rate π and risk budget α, along with sufficient AUC thresholds ensuring that feasible routing exists. Across 35 OpenML datasets and multiple black-box model families, gate-based conformal routing maintains controlled violation while achieving substantially higher coverage than regression conformal and naive baselines. We further show that probabilistic calibration primarily affects routing efficiency rather than distribution-free validity.
Evaluating Kubernetes Performance for GenAI Inference: From Automatic Speech Recognition to LLM Summarization
Feb 03, 2026As Generative AI (GenAI), particularly inference, rapidly emerges as a dominant workload category, the Kubernetes ecosystem is proactively evolving to natively support its unique demands. This industry paper demonstrates how emerging Kubernetes-native projects can be combined to deliver the benefits of container orchestration, such as scalability and resource efficiency, to complex AI workflows. We implement and evaluate an illustrative, multi-stage use case consisting of automatic speech recognition and summarization. First, we address batch inference by using Kueue to manage jobs that transcribe audio files with Whisper models and Dynamic Accelerator Slicer (DAS) to increase parallel job execution. Second, we address a discrete online inference scenario by feeding the transcripts to a Large Language Model for summarization hosted using llm-d, a novel solution utilizing the recent developments around the Kubernetes Gateway API Inference Extension (GAIE) for optimized routing of inference requests. Our findings illustrate that these complementary components (Kueue, DAS, and GAIE) form a cohesive, high-performance platform, proving Kubernetes' capability to serve as a unified foundation for demanding GenAI workloads: Kueue reduced total makespan by up to 15%; DAS shortened mean job completion time by 36%; and GAIE improved Time to First Token by 82\%.
STEB: In Search of the Best Evaluation Approach for Synthetic Time Series
May 27, 2025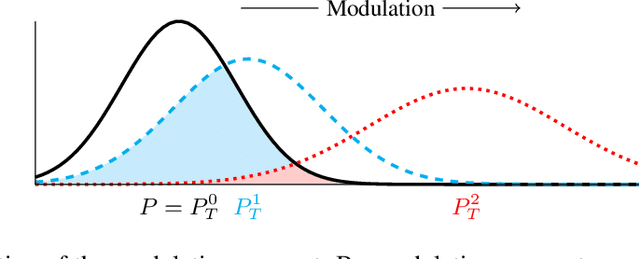
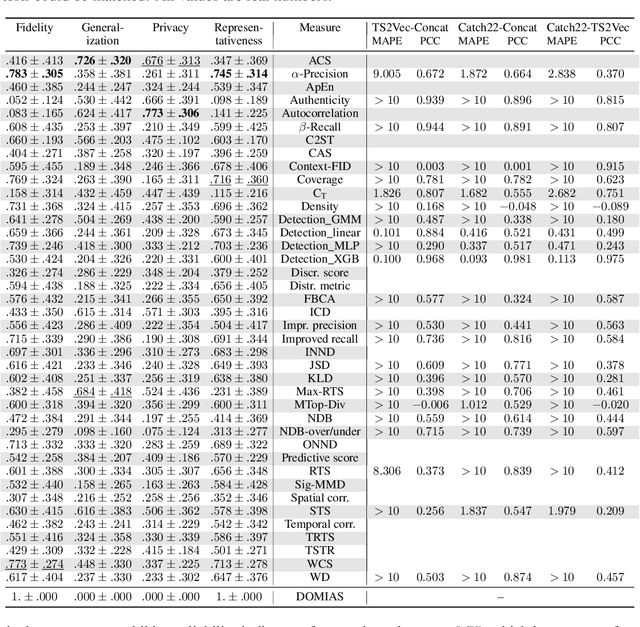
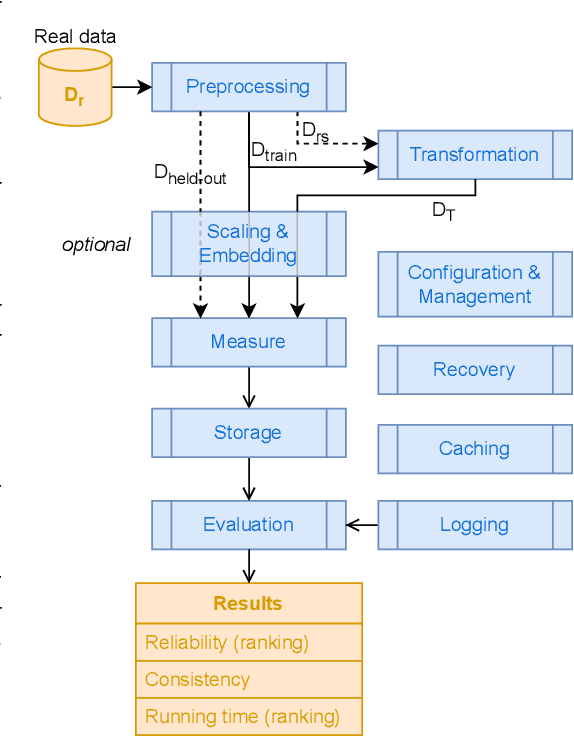
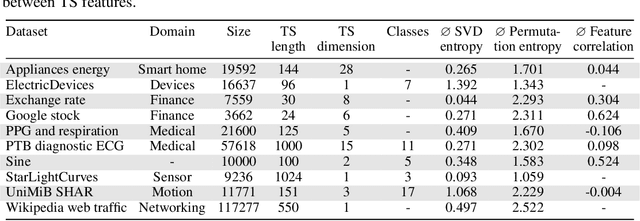
The growing need for synthetic time series, due to data augmentation or privacy regulations, has led to numerous generative models, frameworks, and evaluation measures alike. Objectively comparing these measures on a large scale remains an open challenge. We propose the Synthetic Time series Evaluation Benchmark (STEB) -- the first benchmark framework that enables comprehensive and interpretable automated comparisons of synthetic time series evaluation measures. Using 10 diverse datasets, randomness injection, and 13 configurable data transformations, STEB computes indicators for measure reliability and score consistency. It tracks running time, test errors, and features sequential and parallel modes of operation. In our experiments, we determine a ranking of 41 measures from literature and confirm that the choice of upstream time series embedding heavily impacts the final score.
Oil & Water? Diffusion of AI Within and Across Scientific Fields
May 24, 2024

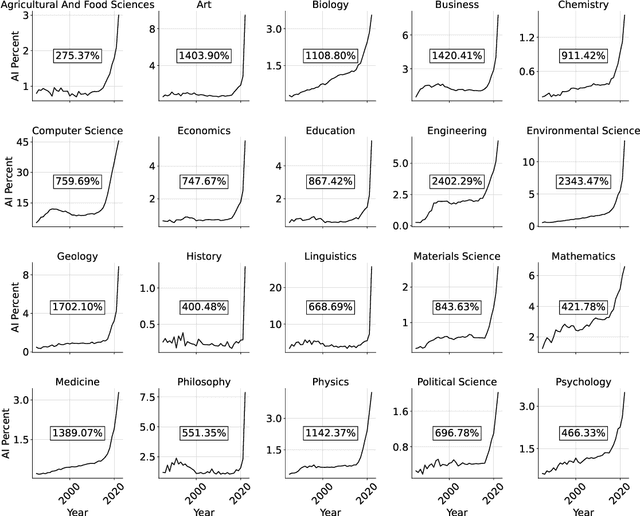
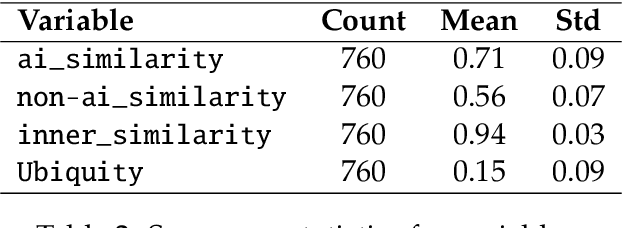
This study empirically investigates claims of the increasing ubiquity of artificial intelligence (AI) within roughly 80 million research publications across 20 diverse scientific fields, by examining the change in scholarly engagement with AI from 1985 through 2022. We observe exponential growth, with AI-engaged publications increasing approximately thirteenfold (13x) across all fields, suggesting a dramatic shift from niche to mainstream. Moreover, we provide the first empirical examination of the distribution of AI-engaged publications across publication venues within individual fields, with results that reveal a broadening of AI engagement within disciplines. While this broadening engagement suggests a move toward greater disciplinary integration in every field, increased ubiquity is associated with a semantic tension between AI-engaged research and more traditional disciplinary research. Through an analysis of tens of millions of document embeddings, we observe a complex interplay between AI-engaged and non-AI-engaged research within and across fields, suggesting that increasing ubiquity is something of an oil-and-water phenomenon -- AI-engaged work is spreading out over fields, but not mixing well with non-AI-engaged work.
Trillion Parameter AI Serving Infrastructure for Scientific Discovery: A Survey and Vision
Feb 05, 2024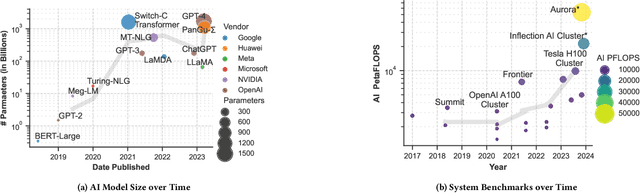
Deep learning methods are transforming research, enabling new techniques, and ultimately leading to new discoveries. As the demand for more capable AI models continues to grow, we are now entering an era of Trillion Parameter Models (TPM), or models with more than a trillion parameters -- such as Huawei's PanGu-$\Sigma$. We describe a vision for the ecosystem of TPM users and providers that caters to the specific needs of the scientific community. We then outline the significant technical challenges and open problems in system design for serving TPMs to enable scientific research and discovery. Specifically, we describe the requirements of a comprehensive software stack and interfaces to support the diverse and flexible requirements of researchers.
Comprehensive Exploration of Synthetic Data Generation: A Survey
Jan 04, 2024Recent years have witnessed a surge in the popularity of Machine Learning (ML), applied across diverse domains. However, progress is impeded by the scarcity of training data due to expensive acquisition and privacy legislation. Synthetic data emerges as a solution, but the abundance of released models and limited overview literature pose challenges for decision-making. This work surveys 417 Synthetic Data Generation (SDG) models over the last decade, providing a comprehensive overview of model types, functionality, and improvements. Common attributes are identified, leading to a classification and trend analysis. The findings reveal increased model performance and complexity, with neural network-based approaches prevailing, except for privacy-preserving data generation. Computer vision dominates, with GANs as primary generative models, while diffusion models, transformers, and RNNs compete. Implications from our performance evaluation highlight the scarcity of common metrics and datasets, making comparisons challenging. Additionally, the neglect of training and computational costs in literature necessitates attention in future research. This work serves as a guide for SDG model selection and identifies crucial areas for future exploration.
Attention Lens: A Tool for Mechanistically Interpreting the Attention Head Information Retrieval Mechanism
Oct 25, 2023

Transformer-based Large Language Models (LLMs) are the state-of-the-art for natural language tasks. Recent work has attempted to decode, by reverse engineering the role of linear layers, the internal mechanisms by which LLMs arrive at their final predictions for text completion tasks. Yet little is known about the specific role of attention heads in producing the final token prediction. We propose Attention Lens, a tool that enables researchers to translate the outputs of attention heads into vocabulary tokens via learned attention-head-specific transformations called lenses. Preliminary findings from our trained lenses indicate that attention heads play highly specialized roles in language models. The code for Attention Lens is available at github.com/msakarvadia/AttentionLens.
Telescope: An Automated Hybrid Forecasting Approach on a Level-Playing Field
Sep 26, 2023


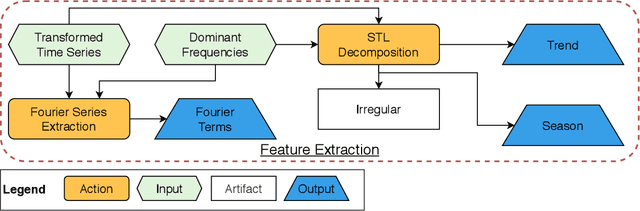
In many areas of decision-making, forecasting is an essential pillar. Consequently, many different forecasting methods have been proposed. From our experience, recently presented forecasting methods are computationally intensive, poorly automated, tailored to a particular data set, or they lack a predictable time-to-result. To this end, we introduce Telescope, a novel machine learning-based forecasting approach that automatically retrieves relevant information from a given time series and splits it into parts, handling each of them separately. In contrast to deep learning methods, our approach doesn't require parameterization or the need to train and fit a multitude of parameters. It operates with just one time series and provides forecasts within seconds without any additional setup. Our experiments show that Telescope outperforms recent methods by providing accurate and reliable forecasts while making no assumptions about the analyzed time series.
Memory Injections: Correcting Multi-Hop Reasoning Failures during Inference in Transformer-Based Language Models
Sep 12, 2023



Answering multi-hop reasoning questions requires retrieving and synthesizing information from diverse sources. Large Language Models (LLMs) struggle to perform such reasoning consistently. Here we propose an approach to pinpoint and rectify multi-hop reasoning failures through targeted memory injections on LLM attention heads. First, we analyze the per-layer activations of GPT-2 models in response to single and multi-hop prompts. We then propose a mechanism that allows users to inject pertinent prompt-specific information, which we refer to as "memories," at critical LLM locations during inference. By thus enabling the LLM to incorporate additional relevant information during inference, we enhance the quality of multi-hop prompt completions. We show empirically that a simple, efficient, and targeted memory injection into a key attention layer can often increase the probability of the desired next token in multi-hop tasks, by up to 424%.