 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfabulation: The Surprising Value of Large Language Model Hallucinations
Jun 06, 2024This paper presents a systematic defense of large language model (LLM) hallucinations or 'confabulations' as a potential resource instead of a categorically negative pitfall. The standard view is that confabulations are inherently problematic and AI research should eliminate this flaw. In this paper, we argue and empirically demonstrate that measurable semantic characteristics of LLM confabulations mirror a human propensity to utilize increased narrativity as a cognitive resource for sense-making and communication. In other words, it has potential value. Specifically, we analyze popular hallucination benchmarks and reveal that hallucinated outputs display increased levels of narrativity and semantic coherence relative to veridical outputs. This finding reveals a tension in our usually dismissive understandings of confabulation. It suggests, counter-intuitively, that the tendency for LLMs to confabulate may be intimately associated with a positive capacity for coherent narrative-text generation.
Oil & Water? Diffusion of AI Within and Across Scientific Fields
May 24, 2024

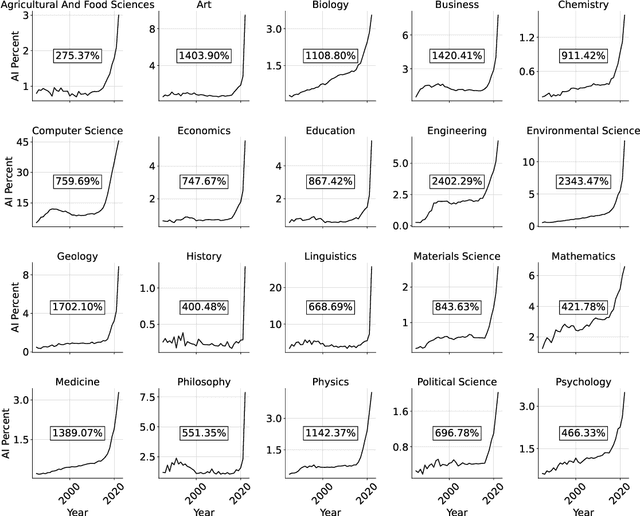
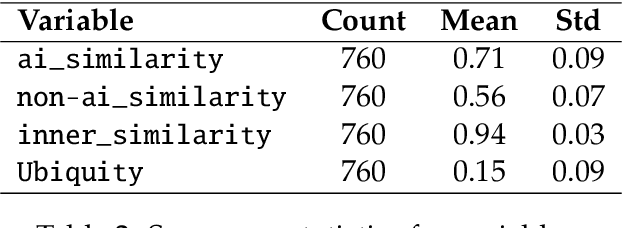
This study empirically investigates claims of the increasing ubiquity of artificial intelligence (AI) within roughly 80 million research publications across 20 diverse scientific fields, by examining the change in scholarly engagement with AI from 1985 through 2022. We observe exponential growth, with AI-engaged publications increasing approximately thirteenfold (13x) across all fields, suggesting a dramatic shift from niche to mainstream. Moreover, we provide the first empirical examination of the distribution of AI-engaged publications across publication venues within individual fields, with results that reveal a broadening of AI engagement within disciplines. While this broadening engagement suggests a move toward greater disciplinary integration in every field, increased ubiquity is associated with a semantic tension between AI-engaged research and more traditional disciplinary research. Through an analysis of tens of millions of document embeddings, we observe a complex interplay between AI-engaged and non-AI-engaged research within and across fields, suggesting that increasing ubiquity is something of an oil-and-water phenomenon -- AI-engaged work is spreading out over fields, but not mixing well with non-AI-engaged work.
Apriori Knowledge in an Era of Computational Opacity: The Role of AI in Mathematical Discovery
Mar 15, 2024Computation is central to contemporary mathematics. Many accept that we can acquire genuine mathematical knowledge of the Four Color Theorem from Appel and Haken's program insofar as it is simply a repetitive application of human forms of mathematical reasoning. Modern LLMs / DNNs are, by contrast, opaque to us in significant ways, and this creates obstacles in obtaining mathematical knowledge from them. We argue, however, that if a proof-checker automating human forms of proof-checking is attached to such machines, then we can obtain apriori mathematical knowledge from them, even though the original machines are entirely opaque to us and the proofs they output are not human-surveyable.
The Representational Status of Deep Learning Models
Mar 21, 2023This paper aims to clarify the representational status of Deep Learning Models (DLMs). While commonly referred to as 'representations', what this entails is ambiguous due to a conflation of functional and relational conceptions of representation. This paper argues that while DLMs represent their targets in a relational sense, they are best understood as highly idealized models. This result has immediate implications for explainable AI (XAI) and directs philosophical attention toward examining the idealized nature of DLM representations and their role in future scientific investigation.
Deep Learning Opacity in Scientific Discovery
Jun 01, 2022
Philosophers have recently focused on critical, epistemological challenges that arise from the opacity of deep neural networks. One might conclude from this literature that doing good science with opaque models is exceptionally challenging, if not impossible. Yet, this is hard to square with the recent boom in optimism for AI in science alongside a flood of recent scientific breakthroughs driven by AI methods. In this paper, I argue that the disconnect between philosophical pessimism and scientific optimism is driven by a failure to examine how AI is actually used in science. I show that, in order to understand the epistemic justification for AI-powered breakthroughs, philosophers must examine the role played by deep learning as part of a wider process of discovery. The philosophical distinction between the 'context of discovery' and the 'context of justification' is helpful in this regard. I demonstrate the importance of attending to this distinction with two cases drawn from the scientific literature, and show that epistemic opacity need not diminish AI's capacity to lead scientists to significant and justifiable breakthroughs.
ScholarBERT: Bigger is Not Always Better
May 23, 2022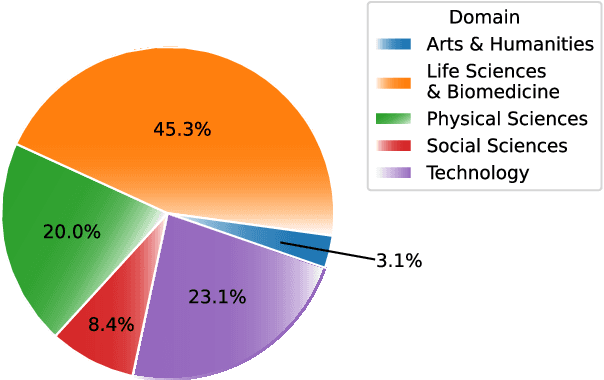
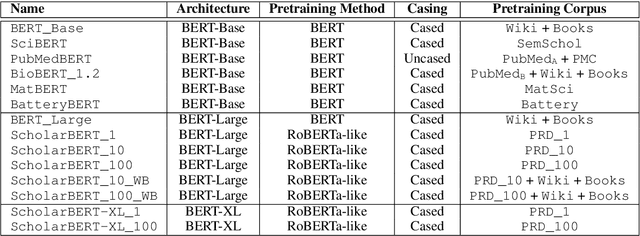

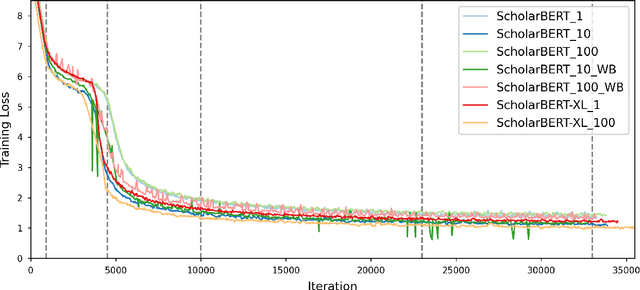
Transformer-based masked language models trained on general corpora, such as BERT and RoBERTa, have shown impressive performance on various downstream tasks. Increasingly, researchers are "finetuning" these models to improve performance on domain-specific tasks. Here, we report a broad study in which we applied 14 transformer-based models to 11 scientific tasks in order to evaluate how downstream performance is affected by changes along various dimensions (e.g., training data, model size, pretraining time, finetuning length). In this process, we created the largest and most diverse scientific language model to date, ScholarBERT, by training a 770M-parameter BERT model on an 221B token scientific literature dataset spanning many disciplines. Counterintuitively, our evaluation of the 14 BERT-based models (seven versions of ScholarBERT, five science-specific large language models from the literature, BERT-Base, and BERT-Large) reveals little difference in performance across the 11 science-focused tasks, despite major differences in model size and training data. We argue that our results establish an upper bound for the performance achievable with BERT-based architectures on tasks from the scientific domain.
The Wisdom of Polarized Crowds
Nov 29, 2017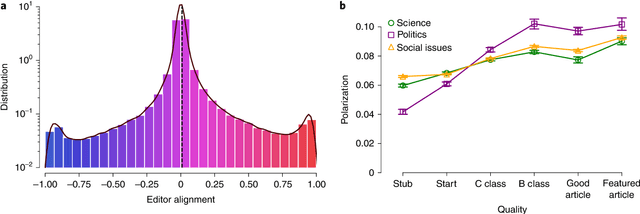
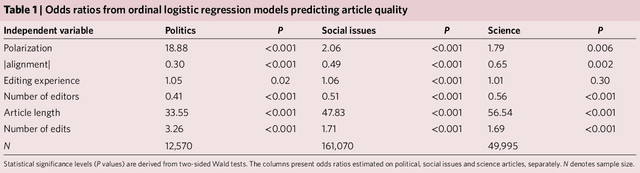
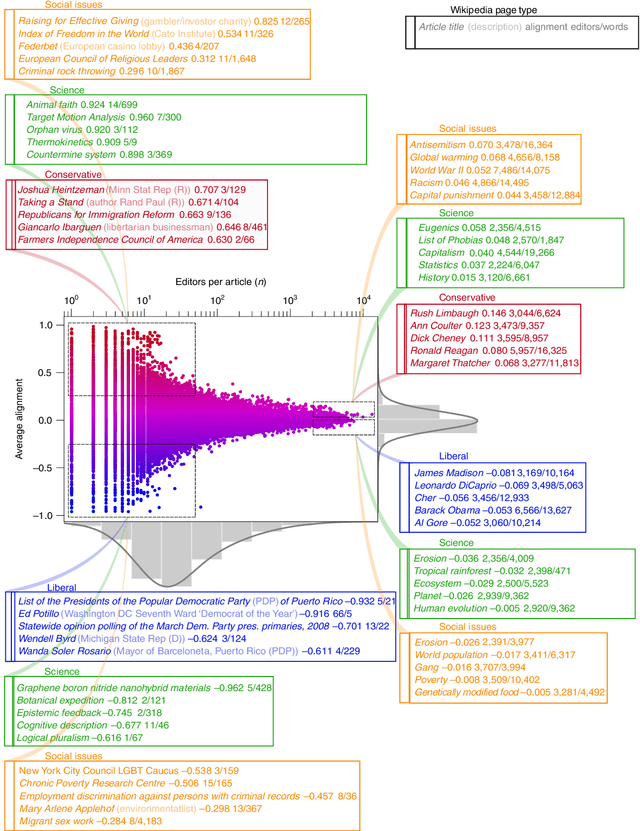
As political polarization in the United States continues to rise, the question of whether polarized individuals can fruitfully cooperate becomes pressing. Although diversity of individual perspectives typically leads to superior team performance on complex tasks, strong political perspectives have been associated with conflict, misinformation and a reluctance to engage with people and perspectives beyond one's echo chamber. It is unclear whether self-selected teams of politically diverse individuals will create higher or lower quality outcomes. In this paper, we explore the effect of team political composition on performance through analysis of millions of edits to Wikipedia's Political, Social Issues, and Science articles. We measure editors' political alignments by their contributions to conservative versus liberal articles. A survey of editors validates that those who primarily edit liberal articles identify more strongly with the Democratic party and those who edit conservative ones with the Republican party. Our analysis then reveals that polarized teams---those consisting of a balanced set of politically diverse editors---create articles of higher quality than politically homogeneous teams. The effect appears most strongly in Wikipedia's Political articles, but is also observed in Social Issues and even Science articles. Analysis of article "talk pages" reveals that politically polarized teams engage in longer, more constructive, competitive, and substantively focused but linguistically diverse debates than political moderates. More intense use of Wikipedia policies by politically diverse teams suggests institutional design principles to help unleash the power of politically polarized teams.