 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Cross-Facility Federated Learning for Scientific Foundation Models on Multiple Supercomputers
Mar 20, 2026Artificial Intelligence for scientific applications increasingly requires training large models on data that cannot be centralized due to privacy constraints, data sovereignty, or the sheer volume of data generated. Federated learning (FL) addresses this by enabling collaborative training without centralizing raw data, but scientific applications demand model scales that requires extensive computing resources, typically offered at High Performance Computing (HPC) facilities. Deploying FL experiments across HPC facilities introduces challenges beyond cloud or enterprise settings. We present a comprehensive cross-facility FL framework for heterogeneous HPC environments, built on Advanced Privacy-Preserving Federated Learning (APPFL) framework with Globus Compute and Transfer orchestration, and evaluate it across four U.S. Department of Energy (DOE) leadership-class supercomputers. We demonstrate that FL experiments across HPC facilities are practically achievable, characterize key sources of heterogeneity impacting the training performance, and show that algorithmic choices matter significantly under realistic HPC scheduling conditions. We validate the scientific applicability by fine-tuning a large language model on a chemistry instruction dataset, and identify scheduler-aware algorithm design as a critical open challenge for future deployments.
Scalable Agentic Reasoning for Designing Biologics Targeting Intrinsically Disordered Proteins
Dec 17, 2025Intrinsically disordered proteins (IDPs) represent crucial therapeutic targets due to their significant role in disease -- approximately 80\% of cancer-related proteins contain long disordered regions -- but their lack of stable secondary/tertiary structures makes them "undruggable". While recent computational advances, such as diffusion models, can design high-affinity IDP binders, translating these to practical drug discovery requires autonomous systems capable of reasoning across complex conformational ensembles and orchestrating diverse computational tools at scale.To address this challenge, we designed and implemented StructBioReasoner, a scalable multi-agent system for designing biologics that can be used to target IDPs. StructBioReasoner employs a novel tournament-based reasoning framework where specialized agents compete to generate and refine therapeutic hypotheses, naturally distributing computational load for efficient exploration of the vast design space. Agents integrate domain knowledge with access to literature synthesis, AI-structure prediction, molecular simulations, and stability analysis, coordinating their execution on HPC infrastructure via an extensible federated agentic middleware, Academy. We benchmark StructBioReasoner across Der f 21 and NMNAT-2 and demonstrate that over 50\% of 787 designed and validated candidates for Der f 21 outperformed the human-designed reference binders from literature, in terms of improved binding free energy. For the more challenging NMNAT-2 protein, we identified three binding modes from 97,066 binders, including the well-studied NMNAT2:p53 interface. Thus, StructBioReasoner lays the groundwork for agentic reasoning systems for IDP therapeutic discovery on Exascale platforms.
Topology-Aware Knowledge Propagation in Decentralized Learning
May 16, 2025Decentralized learning enables collaborative training of models across naturally distributed data without centralized coordination or maintenance of a global model. Instead, devices are organized in arbitrary communication topologies, in which they can only communicate with neighboring devices. Each device maintains its own local model by training on its local data and integrating new knowledge via model aggregation with neighbors. Therefore, knowledge is propagated across the topology via successive aggregation rounds. We study, in particular, the propagation of out-of-distribution (OOD) knowledge. We find that popular decentralized learning algorithms struggle to propagate OOD knowledge effectively to all devices. Further, we find that both the location of OOD data within a topology, and the topology itself, significantly impact OOD knowledge propagation. We then propose topology-aware aggregation strategies to accelerate (OOD) knowledge propagation across devices. These strategies improve OOD data accuracy, compared to topology-unaware baselines, by 123% on average across models in a topology.
MOFA: Discovering Materials for Carbon Capture with a GenAI- and Simulation-Based Workflow
Jan 18, 2025We present MOFA, an open-source generative AI (GenAI) plus simulation workflow for high-throughput generation of metal-organic frameworks (MOFs) on large-scale high-performance computing (HPC) systems. MOFA addresses key challenges in integrating GPU-accelerated computing for GPU-intensive GenAI tasks, including distributed training and inference, alongside CPU- and GPU-optimized tasks for screening and filtering AI-generated MOFs using molecular dynamics, density functional theory, and Monte Carlo simulations. These heterogeneous tasks are unified within an online learning framework that optimizes the utilization of available CPU and GPU resources across HPC systems. Performance metrics from a 450-node (14,400 AMD Zen 3 CPUs + 1800 NVIDIA A100 GPUs) supercomputer run demonstrate that MOFA achieves high-throughput generation of novel MOF structures, with CO$_2$ adsorption capacities ranking among the top 10 in the hypothetical MOF (hMOF) dataset. Furthermore, the production of high-quality MOFs exhibits a linear relationship with the number of nodes utilized. The modular architecture of MOFA will facilitate its integration into other scientific applications that dynamically combine GenAI with large-scale simulations.
LSHBloom: Memory-efficient, Extreme-scale Document Deduplication
Nov 06, 2024Deduplication is a major focus for assembling and curating training datasets for large language models (LLM) -- detecting and eliminating additional instances of the same content -- in large collections of technical documents. Unrestrained, duplicates in the training dataset increase training costs and lead to undesirable properties such as memorization in trained models or cheating on evaluation. Contemporary approaches to document-level deduplication are often extremely expensive in both runtime and memory. We propose LSHBloom, an extension to MinhashLSH, which replaces the expensive LSHIndex with lightweight Bloom filters. LSHBloom demonstrates the same deduplication performance as MinhashLSH with only a marginal increase in false positives (as low as 1e-5 in our experiments); demonstrates competitive runtime (270\% faster than MinhashLSH on peS2o); and, crucially, uses just 0.6\% of the disk space required by MinhashLSH to deduplicate peS2o. We demonstrate that this space advantage scales with increased dataset size -- at the extreme scale of several billion documents, LSHBloom promises a 250\% speedup and a 54$\times$ space advantage over traditional MinHashLSH scaling deduplication of text datasets to many billions of documents.
SoK: On Finding Common Ground in Loss Landscapes Using Deep Model Merging Techniques
Oct 16, 2024



Understanding neural networks is crucial to creating reliable and trustworthy deep learning models. Most contemporary research in interpretability analyzes just one model at a time via causal intervention or activation analysis. Yet despite successes, these methods leave significant gaps in our understanding of the training behaviors of neural networks, how their inner representations emerge, and how we can predictably associate model components with task-specific behaviors. Seeking new insights from work in related fields, here we survey literature in the field of model merging, a field that aims to combine the abilities of various neural networks by merging their parameters and identifying task-specific model components in the process. We analyze the model merging literature through the lens of loss landscape geometry, an approach that enables us to connect observations from empirical studies on interpretability, security, model merging, and loss landscape analysis to phenomena that govern neural network training and the emergence of their inner representations. To systematize knowledge in this area, we present a novel taxonomy of model merging techniques organized by their core algorithmic principles. Additionally, we distill repeated empirical observations from the literature in these fields into characterizations of four major aspects of loss landscape geometry: mode convexity, determinism, directedness, and connectivity. We argue that by improving our understanding of the principles underlying model merging and loss landscape geometry, this work contributes to the goal of ensuring secure and trustworthy machine learning in practice.
Mitigating Memorization In Language Models
Oct 03, 2024



Language models (LMs) can "memorize" information, i.e., encode training data in their weights in such a way that inference-time queries can lead to verbatim regurgitation of that data. This ability to extract training data can be problematic, for example, when data are private or sensitive. In this work, we investigate methods to mitigate memorization: three regularizer-based, three finetuning-based, and eleven machine unlearning-based methods, with five of the latter being new methods that we introduce. We also introduce TinyMem, a suite of small, computationally-efficient LMs for the rapid development and evaluation of memorization-mitigation methods. We demonstrate that the mitigation methods that we develop using TinyMem can successfully be applied to production-grade LMs, and we determine via experiment that: regularizer-based mitigation methods are slow and ineffective at curbing memorization; fine-tuning-based methods are effective at curbing memorization, but overly expensive, especially for retaining higher accuracies; and unlearning-based methods are faster and more effective, allowing for the precise localization and removal of memorized information from LM weights prior to inference. We show, in particular, that our proposed unlearning method BalancedSubnet outperforms other mitigation methods at removing memorized information while preserving performance on target tasks.
Flight: A FaaS-Based Framework for Complex and Hierarchical Federated Learning
Sep 24, 2024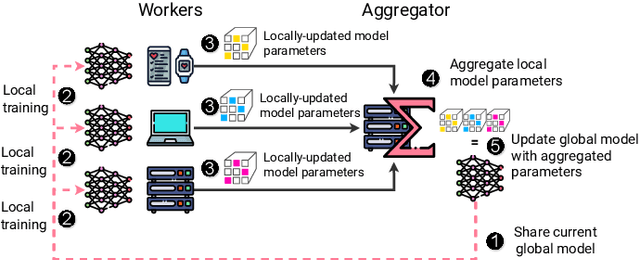

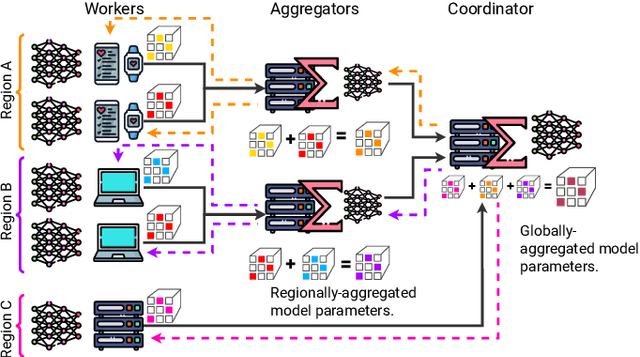
Federated Learning (FL) is a decentralized machine learning paradigm where models are trained on distributed devices and are aggregated at a central server. Existing FL frameworks assume simple two-tier network topologies where end devices are directly connected to the aggregation server. While this is a practical mental model, it does not exploit the inherent topology of real-world distributed systems like the Internet-of-Things. We present Flight, a novel FL framework that supports complex hierarchical multi-tier topologies, asynchronous aggregation, and decouples the control plane from the data plane. We compare the performance of Flight against Flower, a state-of-the-art FL framework. Our results show that Flight scales beyond Flower, supporting up to 2048 simultaneous devices, and reduces FL makespan across several models. Finally, we show that Flight's hierarchical FL model can reduce communication overheads by more than 60%.
Employing Artificial Intelligence to Steer Exascale Workflows with Colmena
Aug 26, 2024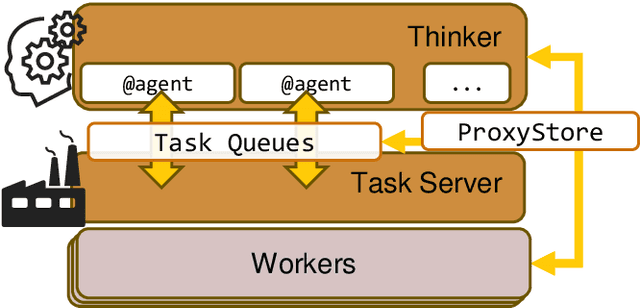
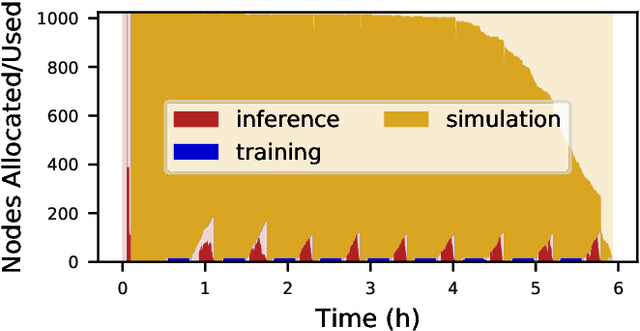
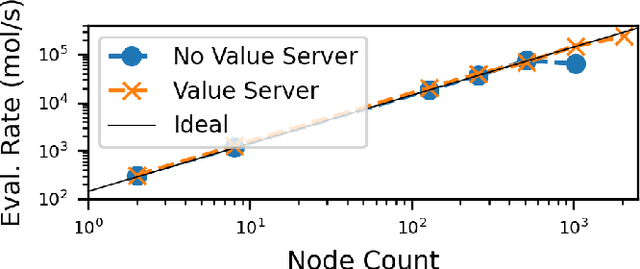
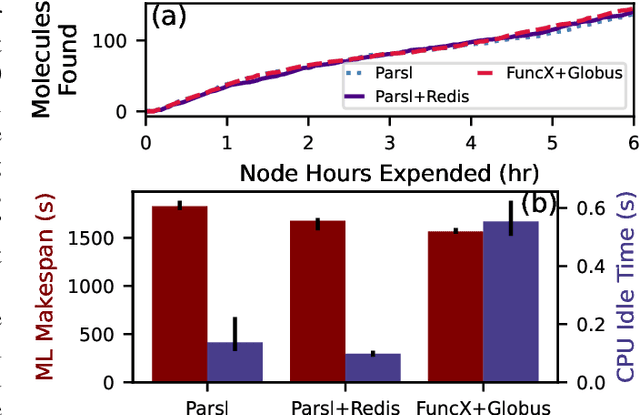
Computational workflows are a common class of application on supercomputers, yet the loosely coupled and heterogeneous nature of workflows often fails to take full advantage of their capabilities. We created Colmena to leverage the massive parallelism of a supercomputer by using Artificial Intelligence (AI) to learn from and adapt a workflow as it executes. Colmena allows scientists to define how their application should respond to events (e.g., task completion) as a series of cooperative agents. In this paper, we describe the design of Colmena, the challenges we overcame while deploying applications on exascale systems, and the science workflows we have enhanced through interweaving AI. The scaling challenges we discuss include developing steering strategies that maximize node utilization, introducing data fabrics that reduce communication overhead of data-intensive tasks, and implementing workflow tasks that cache costly operations between invocations. These innovations coupled with a variety of application patterns accessible through our agent-based steering model have enabled science advances in chemistry, biophysics, and materials science using different types of AI. Our vision is that Colmena will spur creative solutions that harness AI across many domains of scientific computing.
Combining Language and Graph Models for Semi-structured Information Extraction on the Web
Feb 21, 2024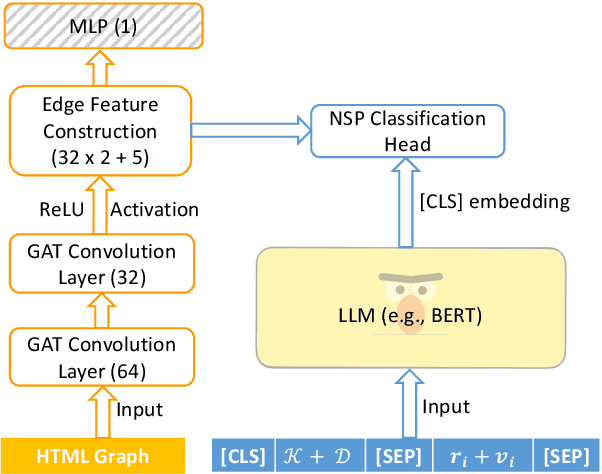


Relation extraction is an efficient way of mining the extraordinary wealth of human knowledge on the Web. Existing methods rely on domain-specific training data or produce noisy outputs. We focus here on extracting targeted relations from semi-structured web pages given only a short description of the relation. We present GraphScholarBERT, an open-domain information extraction method based on a joint graph and language model structure. GraphScholarBERT can generalize to previously unseen domains without additional data or training and produces only clean extraction results matched to the search keyword. Experiments show that GraphScholarBERT can improve extraction F1 scores by as much as 34.8\% compared to previous work in a zero-shot domain and zero-shot website setting.